A New Prompting Approach From DeepMind Called Analogical Prompting
Modern LLMs acquire vast knowledge ranging over various problems during training.

Via Analogical Prompting, explicitly prompting an LLM to recall relevant problems & solutions in context guides the model to perform in-context learning to solve new problems.
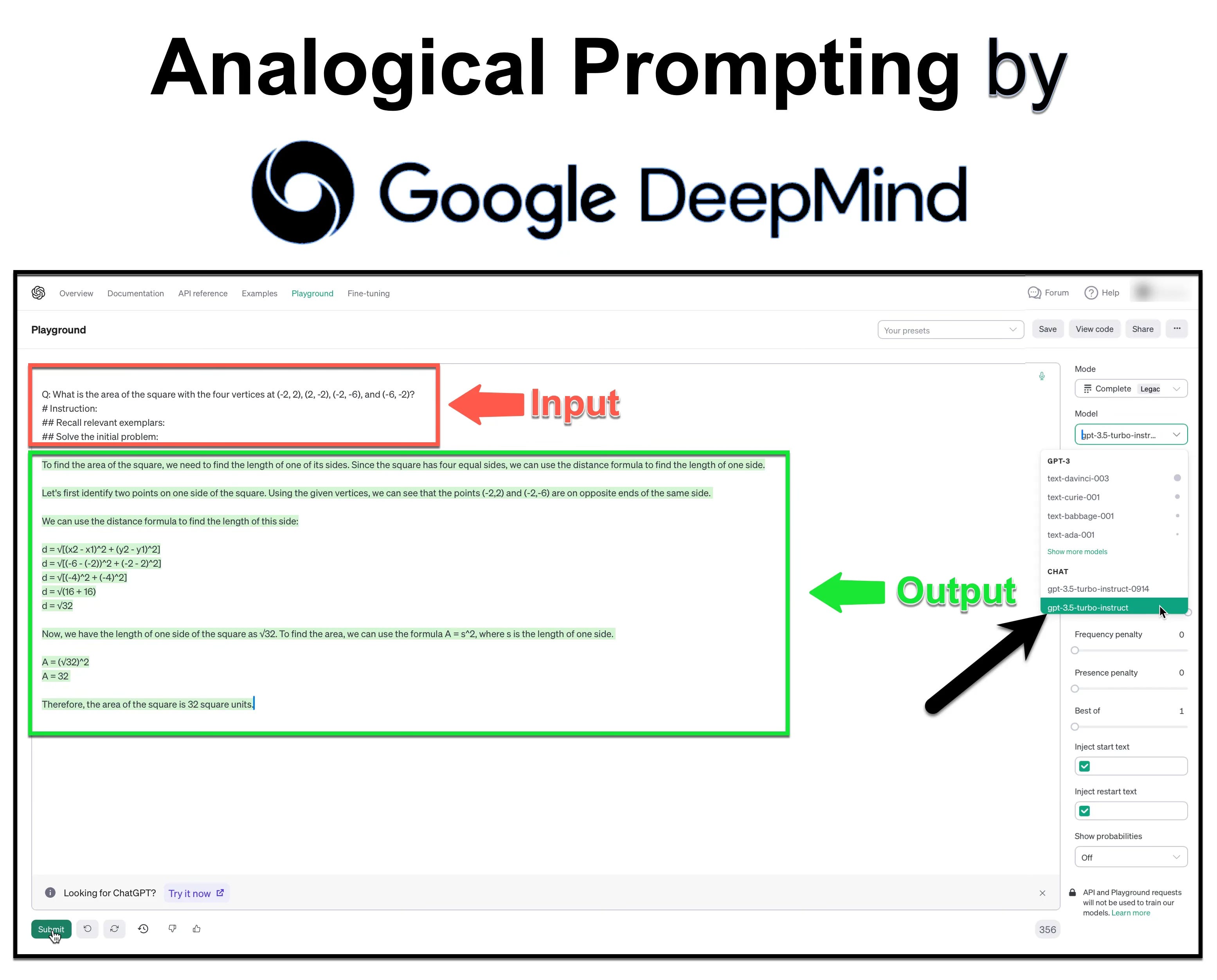
The new prompt engineering approach by DeepMind shown in the image above offers several advantages…
Taking a step back, we as humans often solve problems by asking ourselves, “do I know a related problem?”, subsequently we recall how we solved related problems in the past to derive insights for solving the new problem.
DeepMind’s intention is to prompt LLMs to mimic this reasoning process to effectively solve new problems.
This approach imbue the LLM to self-generate examples and negate the need for manually labelling reasoning examples for each task. This approach can remove overhead from a RAG or prompt pipeline approach by offloading to the LLM some of the labelling and creation of few-shot training data.
The existing CoT paradigm faces two key challenges: providing relevant guidance or exemplars for reasoning, and minimising the need for manual labelling.
Few-Shot CoT provides more detailed guidance but demands labeled exemplars of the reasoning process, which can be costly to obtain for every task.
This raises the research question, can the best of both worlds be achieved by automating the generation of relevant exemplars to guide LLMs’ reasoning process? Hence addressing the challenges faced by Zero-Shot and Few-Shot CoT.
Self-generated exemplars are tailored to individual problems rather than generic ‘math problems’.
This approach prompt LLMs to self-generate relevant exemplars in the context, using instructions like:
# Recall relevant problems and solutions:
And then proceed to solve the original problem.
Simultaneously, DeepMind also prompt LLMs to generate high-level knowledge that complements specific exemplars, using instructions like:
# Provide a tutorial:
In the image below you see the existing methods of LLM prompting on the left, with DeepMind’s Analogical Prompting on the right.

Given a problem, our method prompts LLMs to self-generate relevant exemplars before solving the problem. This eliminates the need for labelling and also tailors the exemplars to each individual problem.
Below an actual example from DeepMind’s prompt for MATH task. The DeepMind prompt supplements the problem statement with instructions to generate relevant exemplars and then solve the problem.
Your task is to tackle mathematical problems. When presented with a math problem, recall relevant problems as examples. Afterward, proceed to solve the initial problem.
# Problem:
An airline serves a dinner to all the passengers on an airplane. They get their choice of steak or fish. Three steak meals and three fish meals are set aside for the six-member crew. If the meals are distributed to the crew members randomly, what is the probability that both pilots get the fish?
# Instructions:
## Relevant Problems:
Recall three examples of math problems that are relevant to the initial problem. Your problems should be distinct from each other and from the initial problem (e.g., involving different numbers and names). For each problem:
- After "Q: ", describe the problem
- After "A: ", explain the solution and enclose the ultimate answer in \boxed{}.
## Solve the Initial Problem:
Q: Copy and paste the initial problem here.
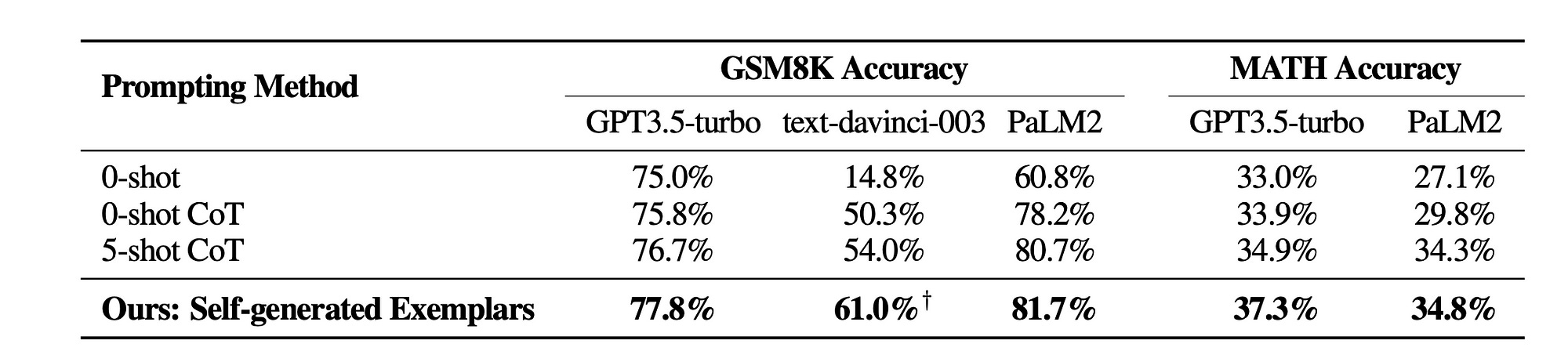
A: Explain the solution and enclose the ultimate answer in \boxed{} here.Below you seen performance on this prompting method which self-generates exemplars. It shows how Analogical Prompting outperforms baseline prompting like zero-short, zero-shot Chain Of Thought and few-shot CoT.
Finally
One of the dangers LLMs introduces, is the absolute abundance they provide in terms of reasoning, NLG and the ability to off-load complexity to the LLM.
For a highly scaleable and manageable solution a framework is required for building, testing and monitoring solutions. A balance needs to be found between LLM fine-tuning and RAG/prompt injections.
Exercising due diligence in terms of prompt injection and creating a contextual reference at inference is important.
I always feel the ideal is to become LLM agnostic as far as possible.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.