A Short History Of LLMs & Conversational UIs
It is said that every good AI strategy starts with a data strategy.


Considering the adoption of LLMs in general and specifically within Conversational AI, the Data AI portion has been lagging considerably behind the data delivery portion.
Introduction
Obviously from a market perspective the LLM tooling ecosystem is developing at a tremendous pace, while users and organisations are still trying to figure out what their top use-cases should be.
Hence while technology is advancing and morphing at a rapid pace, the implementation aspect is lagging for obvious reasons.
I would still argue, that from a tooling perspective most of the focus and consideration is given to LLM Stage 4. But there has been a few exciting developments in the area of LLM Stage 5.
Taking a step back…
When LLM implementations moved from Stage 1 to Stage 2, from design-time use to run-time use, there was a realisation that data needs to be delivered to the LLM at inference.
The importance of In-Context Learning (ICL) has been highlighted by numerous studies, and hence the importance of injecting prompts with highly succinct, concise and contextually relevant data.
And hence the focus was on finding various and optimal ways of delivering contextual reference data at inference.
Taking Generative AI Apps To Production
Recently, I inquired on LinkedIn about the hurdles encountered in deploying Large Language Models (LLMs) to production. Here are the top five concerns raised:
1. Dependency on LLM providers for hosting and API access poses operational challenges that are exceedingly difficult to mitigate.
2. Ideally, organisations would prefer to have a local installation of an LLM for streamlined usage. However, this presents obstacles that many organisations struggle to overcome, such as hosting infrastructure, processing capabilities, and other technical requirements.
3. While “raw” open-source models are available, obstacles persist in terms of hosting, fine-tuning, and the requisite technical expertise.
LLM Disruption: Stage One
AI Assisted & Accelerated NLU Development
The initial phase of Large Language Model (LLM) implementations centred on the development of chatbots, particularly in expediting Natural Language Understanding (NLU) development.
What truly catalysed the disruption in LLM Stage 1 was the integration of LLM functionality during the design phase rather than during runtime.
This approach allowed issues such as inference latency, high-volume usage, costs, and aberrations in LLM responses to be contained within the development phase and shielded from customers in a production environment.
LLMs were initially introduced to aid in the development of Natural Language Understanding (NLU) by clustering existing customer utterances into semantically similar groups for intent detection. Once intent labels and descriptions were established, training utterances for intents could be defined. Additionally, LLMs could be leveraged for entity detection and more.
Looking at the image below, Conversational AI essentially relies on the five elements depicted.
Since the inception of chatbots, the aspiration has been to achieve reliable, concise, coherent, and cost-effective Natural Language Generation (NLG) functionality. This, combined with rudimentary built-in logic and the ability for common-sense reasoning, constitutes the ultimate goal.
Moreover, incorporating a flexible mechanism for managing dialogue context and state, as well as a solution that is more knowledge-intensive than NLU, makes SLMs appear to be the ideal solution.
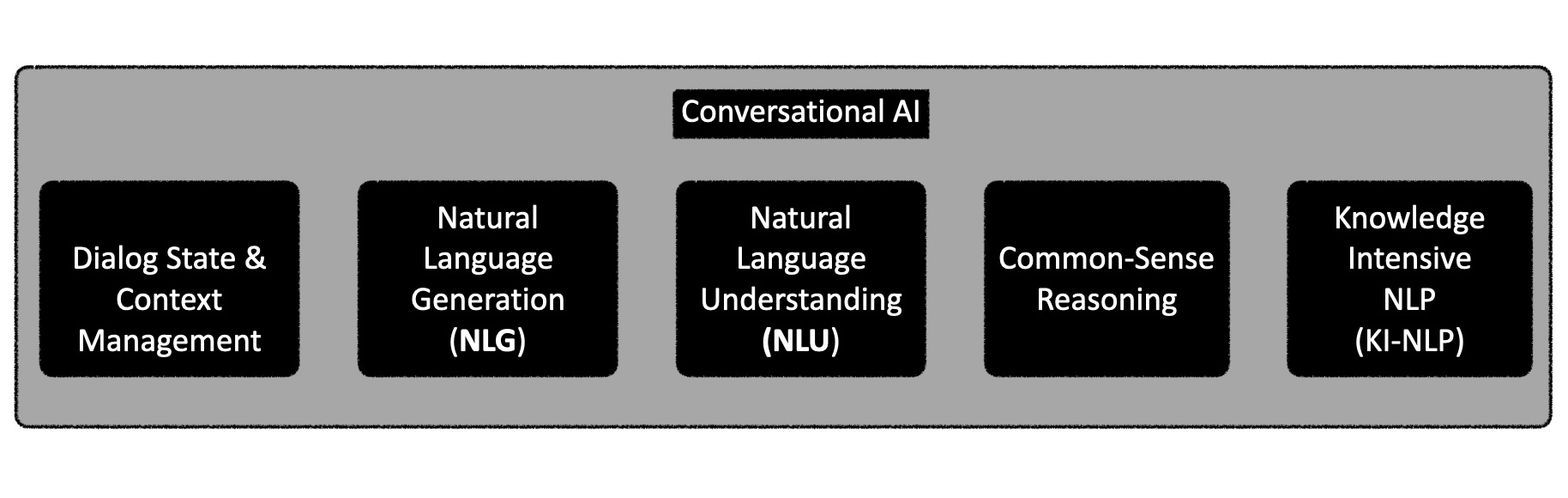
Small Language Models (SLMs) serve as excellent complementary technology for Natural Language Understanding (NLU). These SLMs can operate locally, leveraging open-source models to handle tasks such as Natural Language Generation (NLG), dialog and context management, common-sense reasoning, small talk, and more.
Integrating NLU with an SLM forms a robust foundation for developing chatbots. By running an SLM locally and employing an augmented generation approach with in-context learning, challenges like inference latency, token cost, model drift, data privacy, and data governance can be effectively addressed.
AI Assisted & Accelerated Chatbot Development
Copy Writing & Personas
The next phase of LLM disruption was to use LLMs / Generative AI for chatbot & Voicebot copy writing and to improve bot response messages.
This approach again was introduced at design time as opposed to run time, acting as an assistant to bot developers in crafting and improving their bot response copy.
Designers could also describe to the LLM a persona, tone and other personality traits of the bot in order to craft a consistent and succinct UI.
This is the tipping point where LLM assistance extended from design time to run time.
The LLM was used to generate responses on the fly and present it to the user. The first implementations used LLMs to answer out-of-domain questions, or craft succinct responses from document search and QnA.
LLMs were leveraged for the first time for:
Data & context augmented responses.
Natural Language Generation (NLG)
Dialog management; even though only for one or two dialog turns.
Stage 1 was very much focused on leveraging LLMs and Gen-AI at design time which has a number of advantages in terms of mitigating bad UX, cost, latency and any aberrations at inference.
The introduction of LLMs at design time was a safe avenue in terms of the risk of customer facing aberrations or UX failures. It was also a way to mitigate cost and not face the challenges of customer and PII data being sent into the cloud.
Flow Generation
What followed was a more advanced implementation of LLMs and Generative AI (Gen-AI) with a developer describing to the bot how to develop a UI and what the requirements are for a specific piece of functionality.
And subsequently the development UI went off, leveraging LLMs and Generative AI, it generated the flow, with API place holders, variables required and NLU components.
LLM Disruption: Stage Two
Text Editing
Stage two saw LLMs being used to edit text prior to sending the bot response to the user. For instance, on different chatbot mediums the appropriate message size differs. Hence bot responses could be easily controlled by asking the LLM to summarise, extract key points and change the tone of the response based on user sentiment.
This meant that the hard requirement for a message abstraction layer was deprecated to some degree. In any chatbot / Conversational AI development framework the job of the message abstraction layer is to hold a whole array of bot response messages.
These bot response messages had placeholders which needed to be filled with context specific data to respond to the user with.
Different sets of responses had to be defined for each modality and medium. LLMs made the crafting of responses on the fly easier. This was the NLG (Natural Language Generation) tool we were all waiting for.
Document Search & Document Chat
Chatbots can be given a document, piece of information at inference, this allowed for the LLM to have a frame of reference for the conversation.
Scaling this approach had two impediments, the first is the impediment of limited LLM context windows, and also scaling this approach.
RAG
Rag served as a solution to the problems mentioned above. Read more about RAG here.

Prompt Chaining
Prompt Chaining found its way into Conversational AI development UIs, with the ability to create flow nodes consisting of one or more prompts being passed to a LLM.
Longer dialog turns could be strung together with a sequence of prompts, where the output of one prompt serves as the input for another prompt.
Between these prompt nodes are decision and data processing nodes…so prompt nodes are very much analogous to traditional dialog flow creation, but with the flexibility so long yearned for.
LLM Disruption: Stage Three
Custom Playgrounds
Technology suppliers started creating their own custom playgrounds with extra features and acting as an IDE and collaboration space.
This moved users beyond using LLM-based playgrounds only. Custom playgrounds offered access to multiple models for experimentation, collaboration and various starter code generation options.

Prompt Hubs
Both Haystack and LangChain have launched open community-based prompt hubs.
Prompt hubs help to encode and aggregate best practices for different approaches to Prompt Engineering. The vision is for Gen-Apps to become LLM agnostic where different models are to be used at different stages in the application.
No-Code Fine-Tuning
While fine-tuning changes the behaviour of the LLM and RAG provides a contextual reference for inference, fine-tuning has not received the attention it should have in the recent past. One can argue that this is due to a few reasons…read more here…
LLM Disruption: Stage Four
Prompt Pipelines
In Machine Learning a pipeline can be described as an end-to-end construct, which orchestrates a flow of events and data.
The pipeline is kicked-off or initiated by a trigger; and based on certain events and parameters, a flow is followed which results in an output.
In the case of a prompt pipeline, the flow is in most cases initiated by a user request. The request is directed to a specific prompt template.
Read more here.
Autonomous Agents
Agents make use of pre-assigned tools in an autonomous fashion to perform one or more actions. Agents follow a chain-of-thought reasoning approach.
The concept of autonomous agents can be daunting at first, read more here…
Orchestration
From this point onwards, the market has not really caught up…orchestration refers to orchestrating multiple LLMs for an application.
LLM Hosting
Most of the ailments plaguing LLM implementations are related to LLMs not being self-hosted, or hosted in a private data centre / cloud.
Delayed responses at inference, model drift, data governance and more are all factors which are solved if LLMs are self-hosted and managed.
LLM Disruption: Stage Five
Data Discovery
Data Discovery is the process of identifying any data within an enterprise which can be used for LLM fine-tuning. The best place to start is with existing customer conversations from the contact centre which can be voice or text based. Other good sources of data to discover are customer emails, previous chats and more.

This data should be discovered via an AI accelerated data productivity tool (latent space) where customer utterances are grouped according to semantic similarity, These clusters can be visually represented as seen below, which are really intents or classification; and classifications are still important for LLMs.
Data Design
The next stage in the process is data design, where the identified data undergoes transformation into the necessary format for fine-tuning Large Language Models (LLMs). This involves structuring and formatting the data in a specific manner to function as optional training data.
The design phase is complementary to the discovery phase; at this juncture, we understand which data is crucial and will have the greatest impact on users and customers.
Therefore, data design encompasses two aspects: the technical formatting of the data itself and the content and semantics of the training data.
Data Development
This step involves the operational aspect of continuously monitoring and observing customer behaviour and data performance. Data can be refined by augmenting training data with insights gained from observed vulnerabilities in the model.
Data Delivery
Data Delivery can be understood as the process of enriching one or more models with data tailored to the specific use-case, industry, and user context during inference. The contextual data segment injected into the prompt serves as a reference point for the LLM to provide accurate responses consistently.
There’s often a misconception that the various methods of data delivery are mutually exclusive, with one approach deemed as the ultimate solution. This viewpoint can stem from ignorance, a lack of understanding, organizations seeking quick-fix solutions, or vendors advocating for their specific product as the silver bullet.
However, the reality is that enterprise implementations require flexibility and manageability, which inherently entail complexity. This complexity applies to any LLM implementation and the approach taken to deliver data to the LLM. There is no one-size-fits-all solution; rather, a balanced multi-pronged approach, incorporating methods like RAG or Prompt Chaining, is necessary for optimal results.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.