A Short History Of RAG
In this article I explain the fundamentals of RAG and why it is important.

Introduction
One of the most popular themes currently around Large Language Models is the idea of Retrieval Augmented Generation (RAG).
RAG is important for a number of reasons, in this article I first discuss what caused the rise in popularity of RAG. Together with a basic illustration of RAG in its most simplest form.
Why RAG
Emergent Capabilities
A short while ago, LLMs were deemed to have something which was referred to as emergent capabilities.
Emergent capabilities refer to the unexpected or previously unforeseen functionalities that the model demonstrates during its interactions with users or tasks.
Emergent capabilities in LLMs might include:
Problem-solving, where LLMs might exhibit problem-solving abilities by providing insightful solutions or approaches to tasks they were not explicitly trained on, leveraging their understanding of language and reasoning abilities.
Adaptation to user inputs where LLMs adapt their responses to specific user inputs or contexts, demonstrating a degree of personalisation or tailoring in their outputs based on the interaction dynamics.
Are Emergent Abilities of Large Language Models a Mirage?
Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models…
arxiv.org
Contextual understanding, with LLMs demonstrating nuanced understanding of context, allowing them to generate responses that are relevant and appropriate to the given context, even if it’s not explicitly stated in the prompt.
The phenomenon of emergent capabilities gave rise to organisations trying to discover previously unknown LLM functionality.
The concept of emergent capabilities was proven to be a mirage.
A recent study tagged the idea of emergent capabilities as a mirage, and it was actually found that what was deemed as an emergent abilities was the fact that, in general, LLMs responds really well when supplied with context.
Instruction & Contextual Reference
LLMs respond well on instructions at inference. And, it has been found that LLMs respond really well when a prompt is injected with contextual reference data.
Numerous studies have empirically proven that LLMs prioritises contextual knowledge supplied at inference above data the model has been fine-tuned on.
In-Context Learning
In-context learning refers to the ability of the model to adapt and refine its responses based on the specific context provided by the user or the task at hand.
This process allows the model to generate more relevant and coherent outputs by considering the context in which it is operating.
Non-Gradient Approach
There are two approaches to programming LLMs. Another way to describe programming LLMs is to think of it as the way you deliver your data to the LLM.
Data delivery can be gradient or gradient-free.
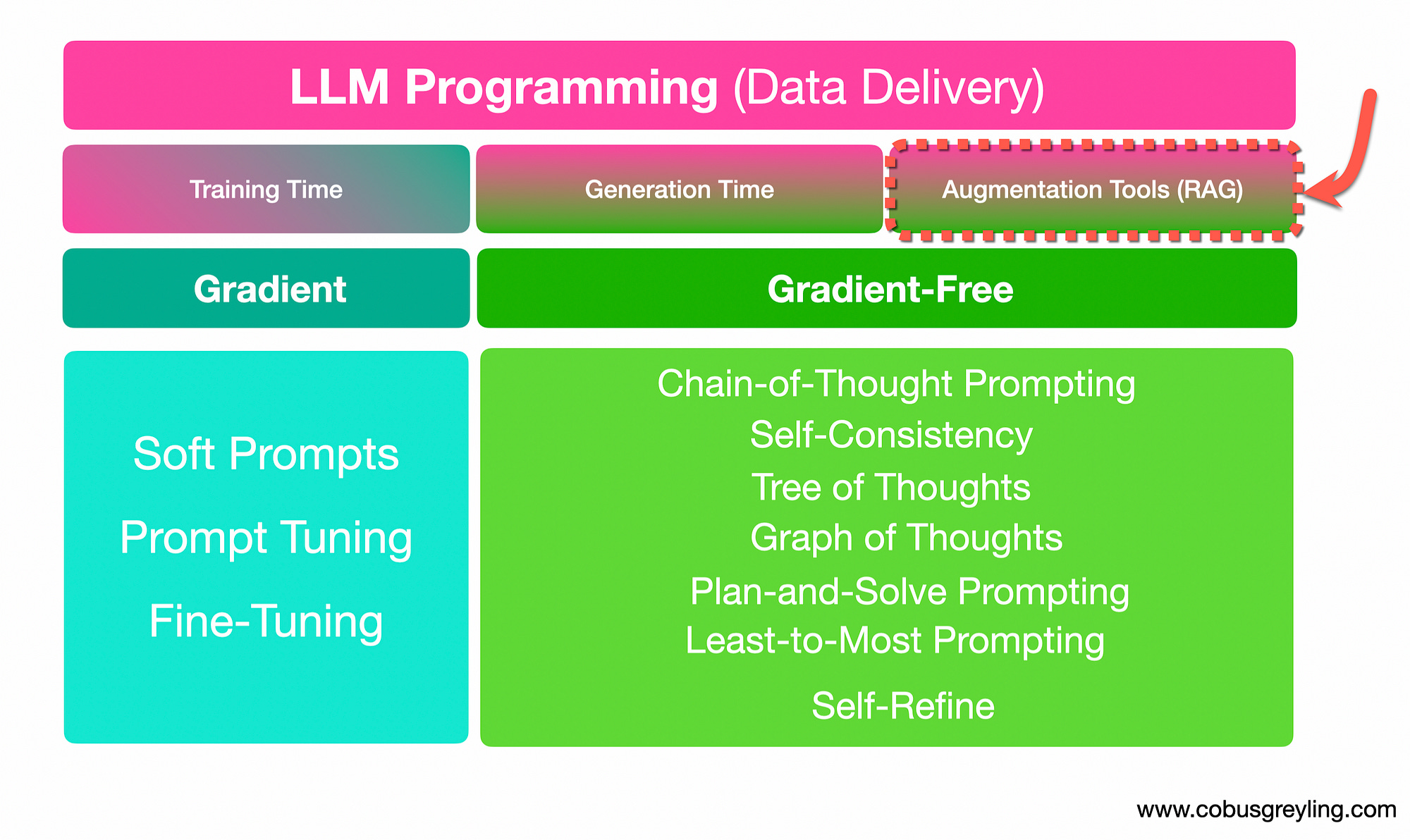
In the context of training large language models (LLMs), the difference between a gradient-based approach and a gradient-free approach lies in how the model parameters are updated during the training process.
Gradient-based Approach
In a gradient-based approach, the model parameters are updated iteratively; for example, via model fine-tuning.
Gradient-based optimisation methods are widely used in training LLMs because they leverage the smoothness of the loss landscape and efficiently update the parameters to converge towards an optimal solution.
Gradient-Free Approach
In contrast, gradient-free optimisation methods do not rely on gradients (fine-tuning) to update the model parameters. Instead, they explore the parameter space using heuristic search algorithms that do not require gradient information.
In the case of gradient free approaches, an investment is not made in any particular model. And the structure and methods developed sit outside of the LLM.
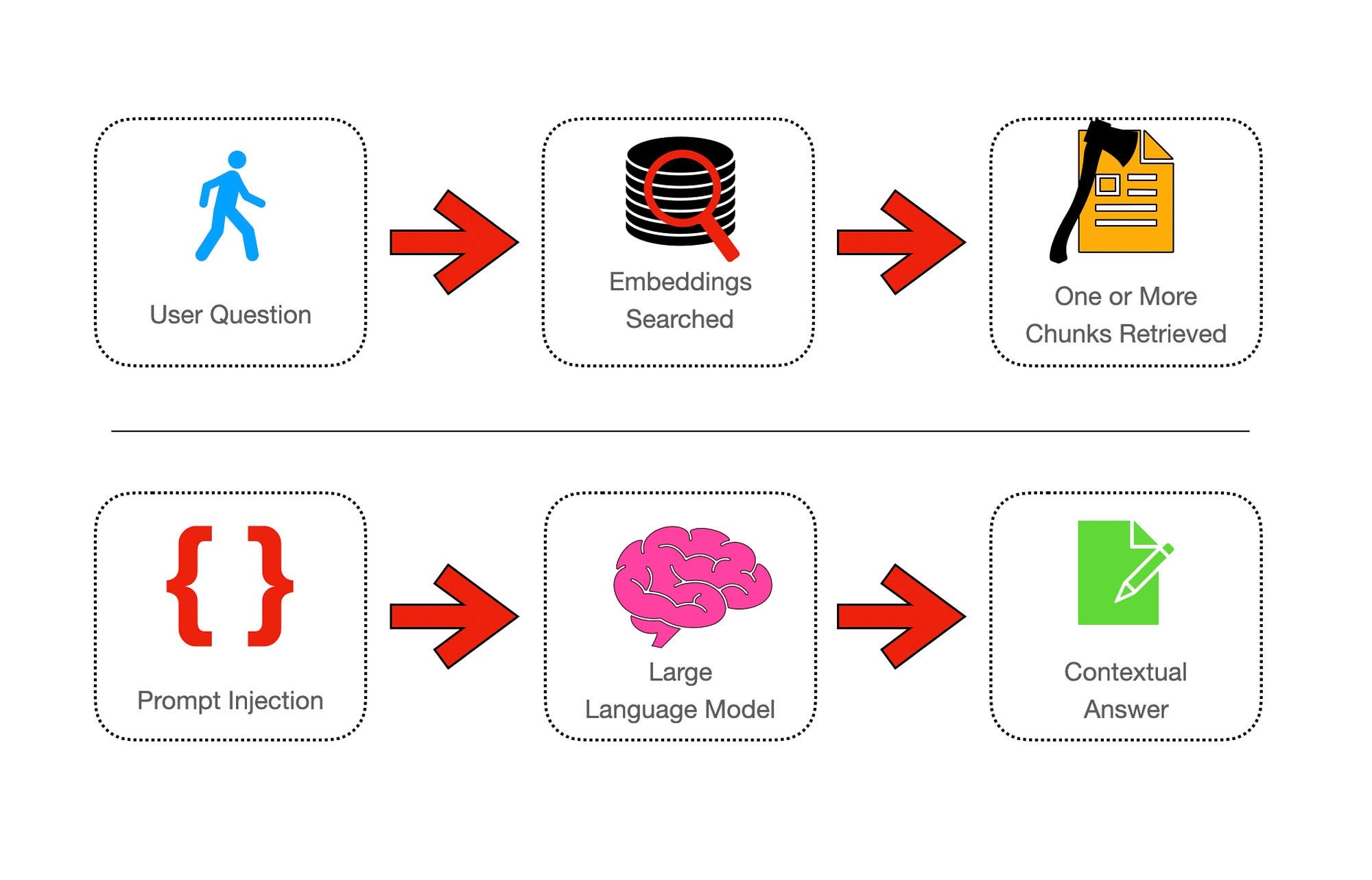
RAG Example In Its Most Simplest Form
The two impediments which LLMs have, for obvious reasons, are the following:
Even-though LLMs are knowledge-intensive, the model does not have knowledge outside of the ambit of knowledge it was trained on, and there is a model cut-off date.
Models need to be given the context of the question in order to generated accurate and succinct answers.
Consider the image below from the OpenAI playground, a highly contextual question is put to GPT-4, which it obviously cannot understand.

In the example below, the same highly contextual question is asked. Notice that without the context, the question is ambiguous and really impossible to answer.
However, here a RAG prompt is manually created, with an instruction, and a context piece which will augment the generation. And lastly the question is asked. This time round, the LLM answers the question correctly by referencing the context.
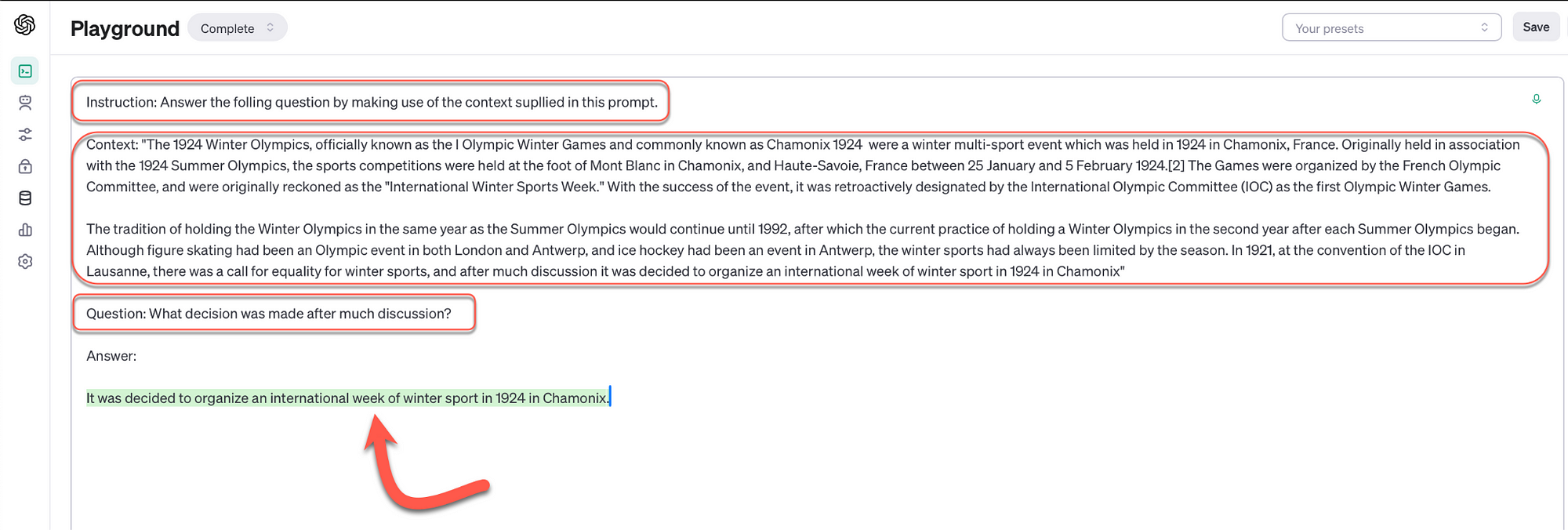
So in the above example augmented generation is illustrated, but the context was manually entered and not retrieved via any automated methods.
For any enterprise grade installation, the insertion or injection of the context into the prompt needs to be automated where the context is retrieved and inserted into the prompt in real-time at inference.
The second challenge, apart from speed and latency, is that the contextual snipped needs to be highly relevant to the context of the user.
And, the snipped needs to be an optimal size. The size needs to take into consideration:
Latency and overhead in terms of bandwidth when scaling users.
Optimised in terms of input token usage of LLMs. This plays a determining factor in terms of the cost.
Context pieces are referred to as chunks. So corpuses of data which need to serve as contextual reference needs to be chunked into these context reference snippets.
And again, some kind of semantic search needs to be performed to retrieve the correct contextual chunk of text to insert into the prompt.
Prompt Injection
Below is a prompt example from LlamaIndex:
qa_prompt_tmpl_str = """\
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, \
answer the query asking about citations over different topics.
Please provide your answer in the form of a structured JSON format containing \
a list of authors as the citations. Some examples are given below.
{few_shot_examples}
Query: {query_str}
Answer: \
"""In Conclusion
The importance of context for Large Language Models (LLMs) lies in their ability to understand and generate language in a manner that is relevant, coherent, and appropriate to the given situation or task.
Context provides the necessary background information and cues that shape the interpretation and generation of language by LLMs.
Overall, context serves as a guiding framework for LLMs, enabling them to understand, interpret, and generate language in a manner that reflects the intricacies of human communication.
By incorporating context into their models, researchers and developers can enhance the capabilities and effectiveness of LLMs across a wide range of applications and domains.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.