Adaptive-RAG
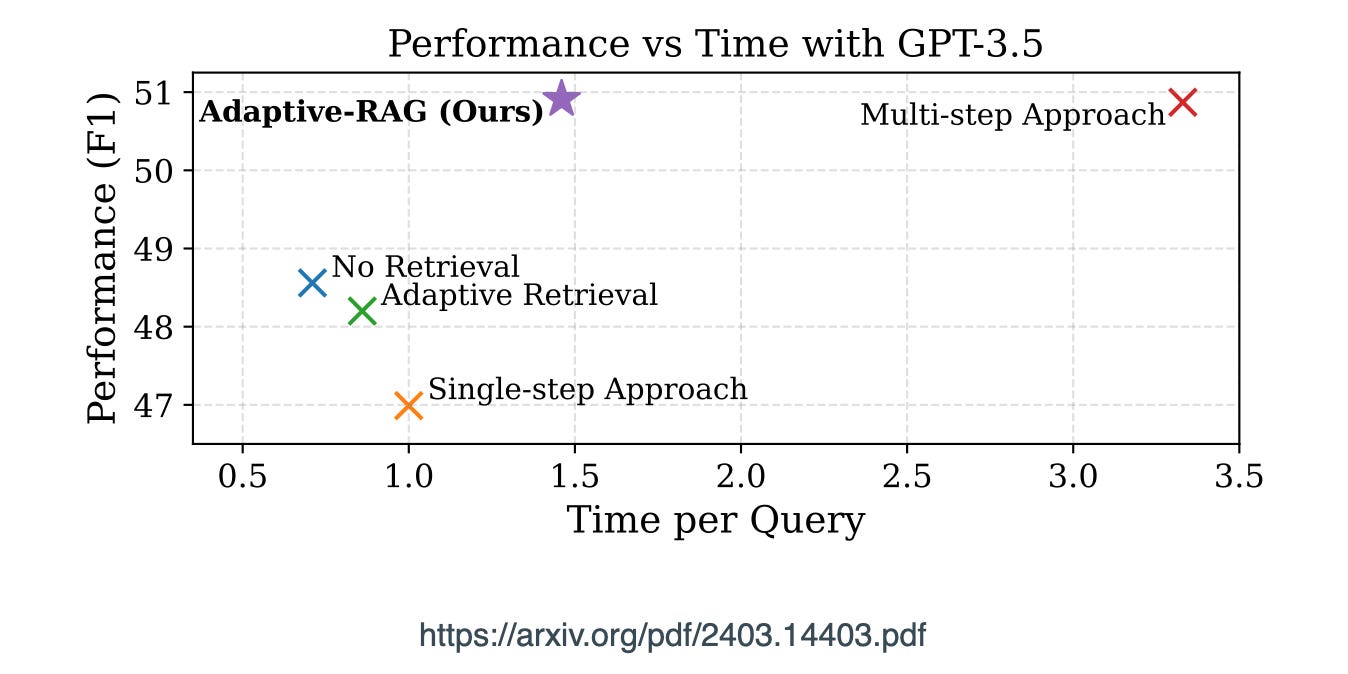
It is evident that there needs to be a balance between query time, quality in terms of performance, but also efficiency.

Introduction
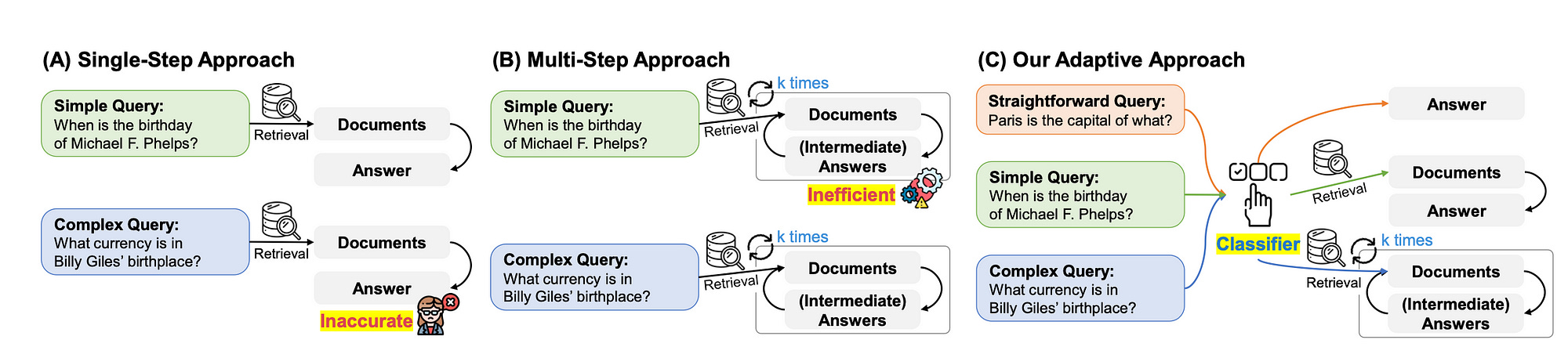
The challenge with any LLM implementation is the extent to which simple queries are recognised as such, and no unnecessary computational overhead is created.
Or, the implementation fails to adequately address more complex multi-step queries.
But there are also queries that fall within the range between these to extremes which needs to be addressed adequately.
Hence this study introduces an adaptive QA framework designed to choose the most appropriate strategy for (retrieval-augmented) large language models (LLMs), ranging from simple to complex, depending on the complexity of the query.
This is accomplished by using a classifier, a smaller LM trained to predict query complexity levels using automatically gathered labels from real model predictions and inherent dataset patterns.
This approach allows for a flexible strategy, seamlessly transitioning between iterative and single-step retrieval-augmented LLMs, as well as non-retrieval methods, to handle various query complexities.
This model was tested on multiple open-domain QA datasets with different query complexities, demonstrating its ability to improve overall efficiency and accuracy compared to relevant baselines, including adaptive retrieval approaches.
Adaptive RAG
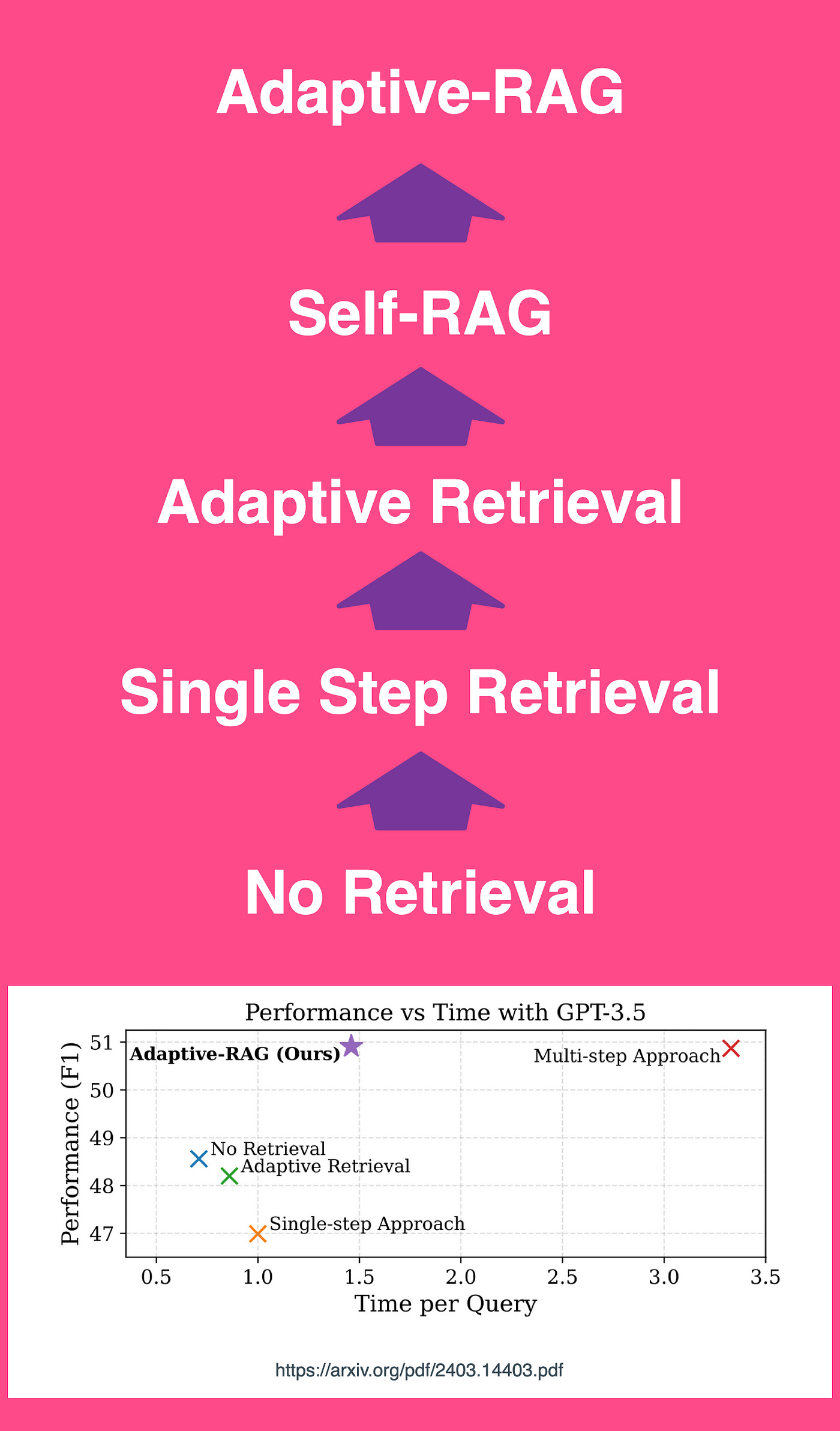
The image below shows a conceptual comparison of three RAG approaches to question answering.
Adaptive RAG shows an approach that can select the most suitable strategy ranging from iterative, to single, to even no retrieval approaches, based on the complexity of given queries determined by the classifier.
Obviously in Adaptive RAG, the classifier is of utmost importance to the success of the framework.
In Conclusion
Considering the graph below, it is evident that there needs to be a balance between query time, quality in terms of performance, but also efficiency. With cost also being a consideration.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.