

Adding Noise Improves RAG Performance
This study’s findings suggest that including irrelevant documents can enhance performance by over 30% in accuracy, challenging initial assumptions.

Introduction
The significance of Retrieval-Augmented Generation (RAG) systems as a notable improvement over traditional Large Language Models (LLMs) has been established.
RAG systems enhance their generation capabilities by incorporating external data through an Information Retrieval (IR) phase, addressing limitations of standard LLMs.
While most research has focused on the generative aspect of LLMs within RAG systems, this study fills a gap by critically analysing the influence of IR components on RAG systems.
The paper explores the characteristics a retriever should possess for effective prompt formulation, emphasising the type of documents to be retrieved.
The evaluation includes factors like document relevance, position, and the context size.
Surprisingly, the findings suggest that including irrelevant documents can enhance performance by over 30% in accuracy, challenging initial assumptions.
The results highlight the need for specialised strategies to integrate retrieval with language generation models, paving the way for future research in this field.
At their core, RAG systems are made of two fundamental components: retriever and generation.
The IR component is responsible for sourcing external information to enrich the input for the generation module.
In contrast, the generation component leverages the power of LLMs to produce coherent and contextually relevant text.
Fundamental Premise
The study observed that in RAG systems, associated documents prove to be more detrimental than those unrelated.
What’s even more unexpected is the revelation that incorporating noisy documents can be advantageous, resulting in an improvement of up to 35%in accuracy.
These findings stand in stark contrast to the conventional customer facing application of Information Retrieval (IR) systems, where related documents are generally considered more acceptable than their unrelated counterparts.
A LLM might come up with a wrong answer due to a retriever which retrieves relevant and related data.
This leaves the LLM with the task to disambiguate to establish the correct context and data matching the task, and creating the risk of the LLM answering the question contextually correct, but factually incorrect.
Introducing random noise can correct the LLM can help the LLM to answer more correctly. Of course there is a optimal balance which needs to be acheived.
Practical Examples

LLM Input — Only Gold Documents
Considering the image above, the example on the left shows LLM input with an erroneous output, in red. The LLM input includes a task instruction, followed by the context / document. And finally the query.
The LLM’s response is marked under Answer. The gold colour highlights both the gold document and the correct answer, Lando Calrissian, indicating the expected source and content of the accurate response.
LLM Input — Related and Gold Documents
The middle example; LLM input with an erroneous output, highlighted in red. The context of the prompt is composed of related documents and the gold document near the query.
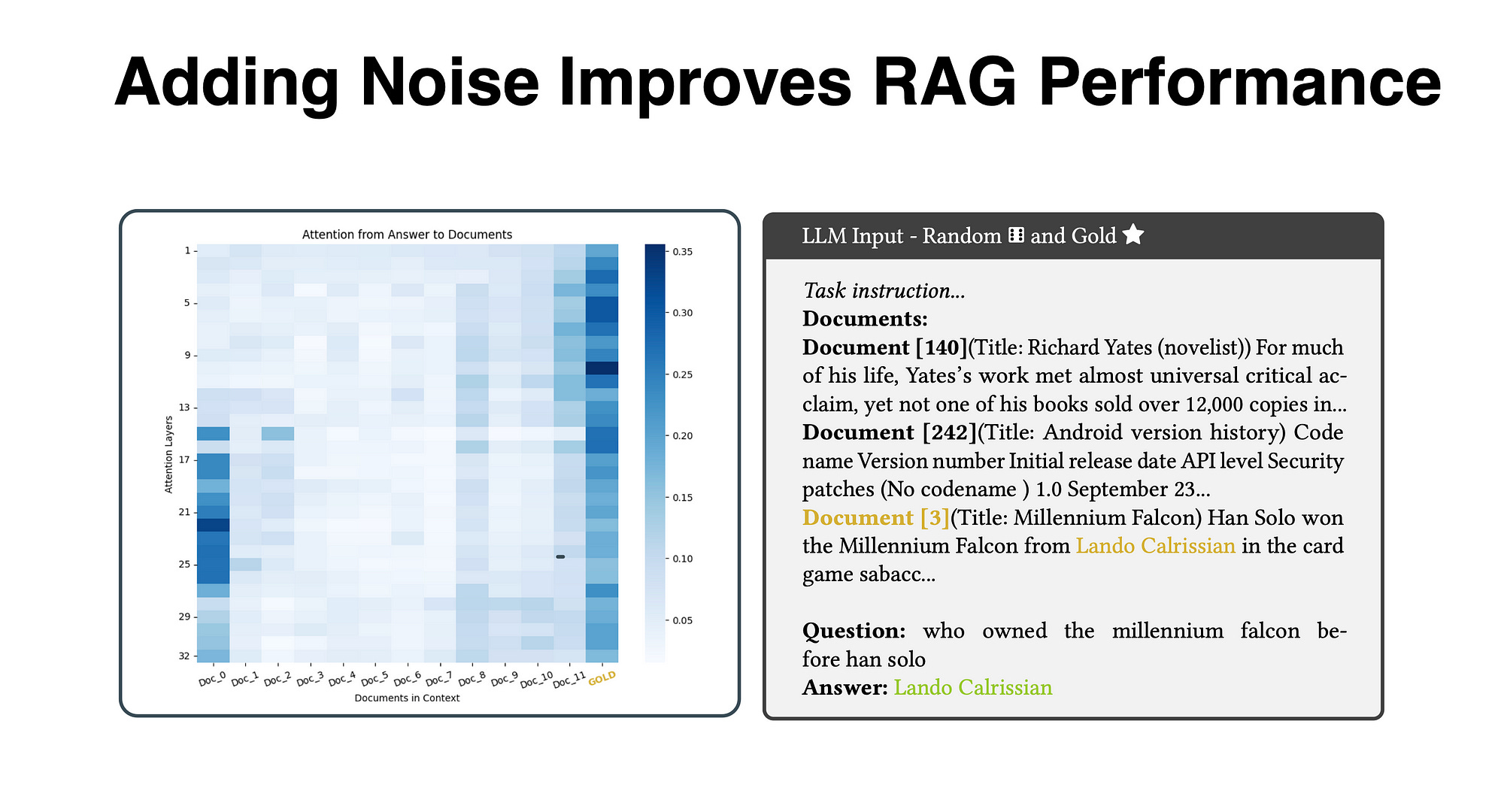
LLM Input — Random Irrelevant and Gold
The example on the right, example LLM input with a correct output, shown in green. The context of the prompt is composed of random documents and the gold near the query.
In Closing
The paper presents the first comprehensive study examining how retrieved documents impact Retrieval-Augmented Generation (RAG) frameworks. The goal is to understand the traits necessary in a retriever to optimise prompt construction for RAG systems.
Placing relevant information near the query is crucial for the model to effectively attend to it; otherwise, the model struggles.
Surprisingly, related documents can be extremely harmful to RAG systems, while irrelevant and noisy documents, when placed correctly, can enhance system accuracy.
The research contributes valuable insights into the dynamics of document retrieval in RAG frameworks, emphasising the importance of optimising the placement of relevant and irrelevant documents for system accuracy.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.