Agent = Model + Harness
LLM-based agents are increasingly deployed as executable systems that use tools, write code, live in and modify workspaces and produce concrete output.


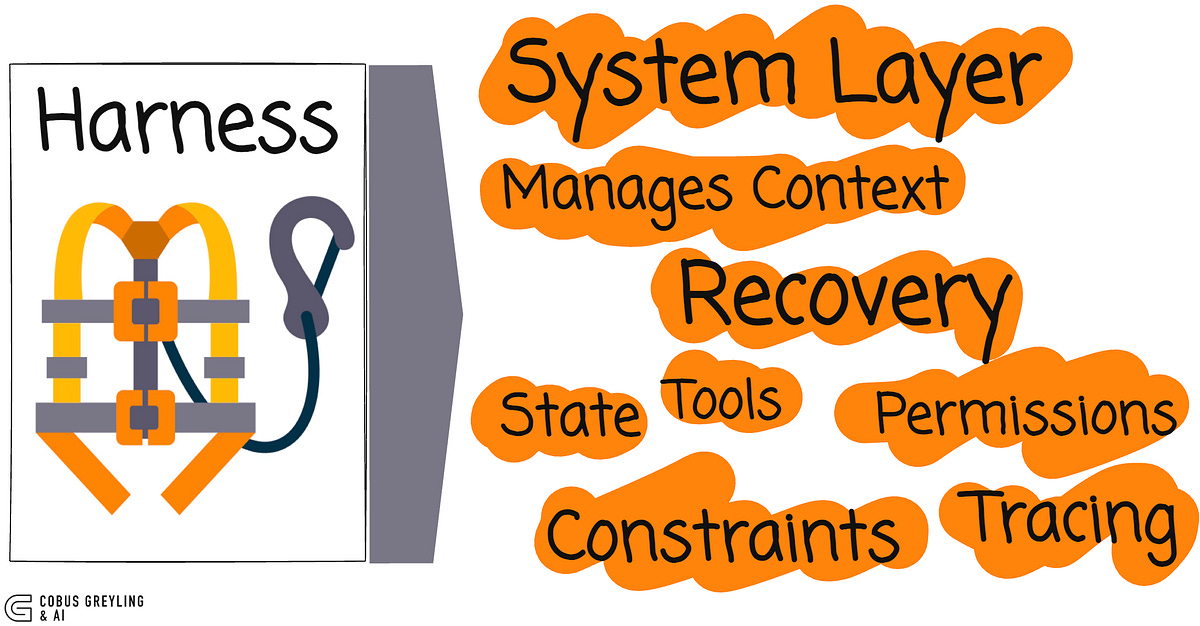
Their performance depends not only on the base model, but also on the harness.
One can think of the harness as the system layer that manages context, tools, state, constraints, permissions, tracing, and recovery.
The study suggests that agent capability should be reported at the model-harness configuration level rather than attributed to the base model alone.
Which, for me, makes perfect sense.
The study also identifies recurring execution-alignment failures, where plausible reasoning becomes decoupled from tool feedback, workspace state, evidence, or verifiable output contracts.
So the aim of Harness-Bench is to provide a reproducible foundation for diagnosing and improving reliable, efficient and auditable agent execution stacks.
Harness-Bench gives a clear signal on how harness and model combinations actually perform together.
Background
The benchmark breaks the AI agent architecture down to an extent where everything does not revolve around the model…
Yes, there are one or more models, but then there is the harness …the part that manages context, tools, state, permissions, and recovery.
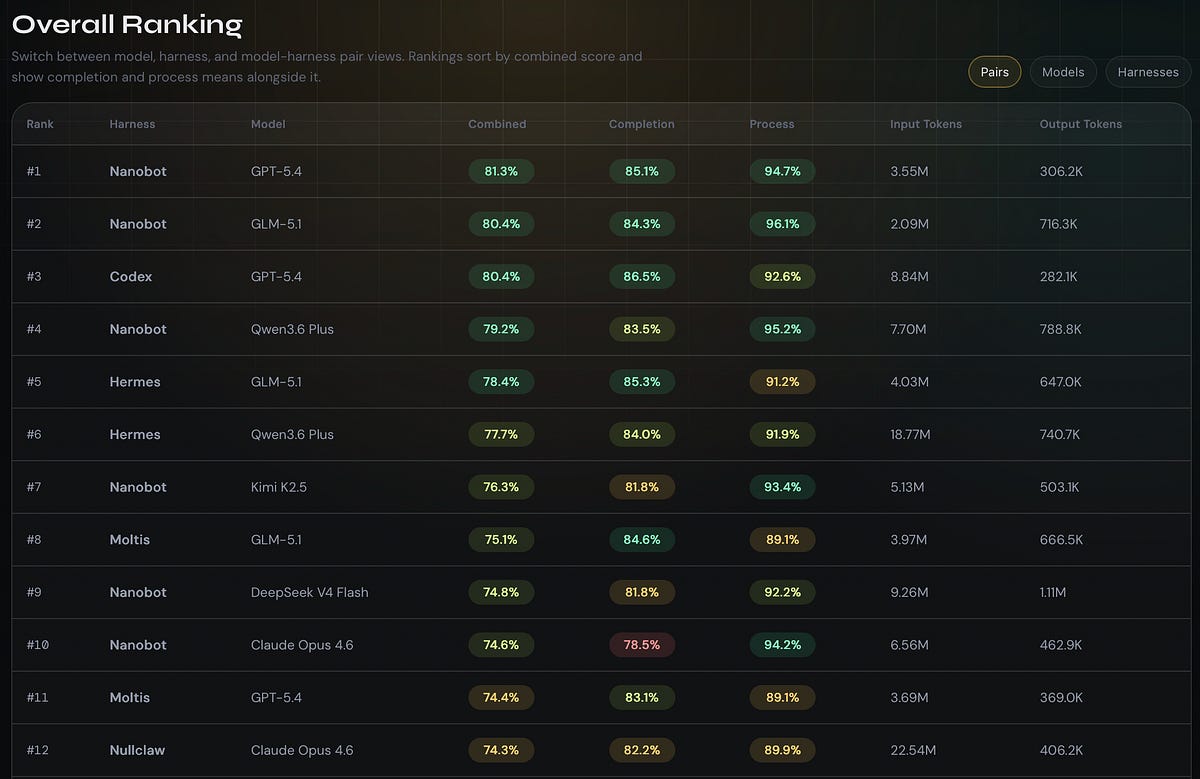
And when you swap it, the score moves 23.8 points on the same tasks with the same model-backend pool.
NanoBot scores 76.2.
OpenClaw scores 52.4.
Same tasks and model pool. Different scaffolding. The model was not the variable.
The paper states the idea as an equation, and the equation is the whole argument:
> Agent = Model + Harness
It is easy and convenient to put a single number next to a model.
But considering the wide array of tasks and varying complexity, the model should not be the primary axis…the harness should be.
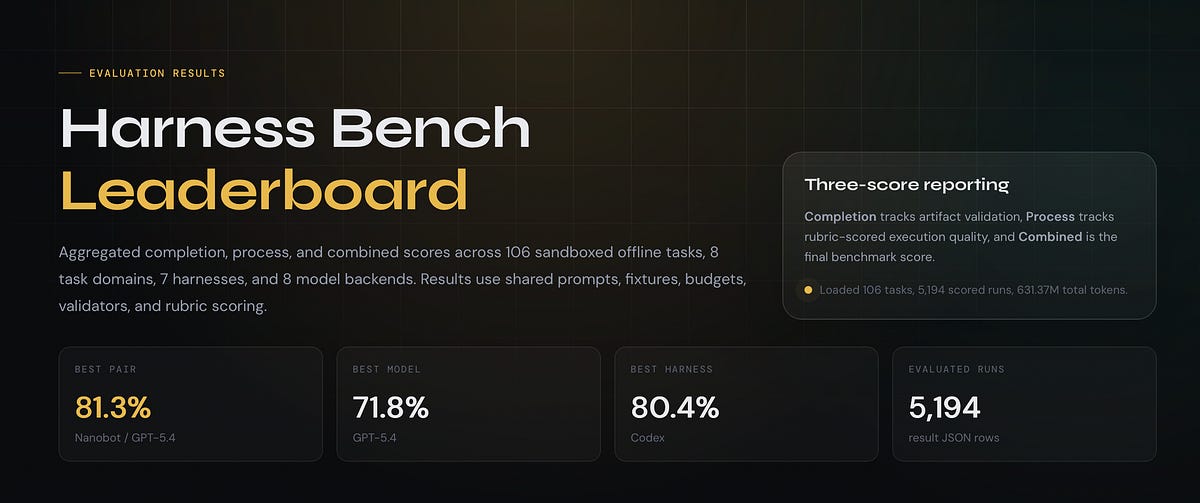
Harness-Bench involves 106 sandboxed tasks, 8 model backends, 6 harnesses, and 5,194 trajectories.
Tasks
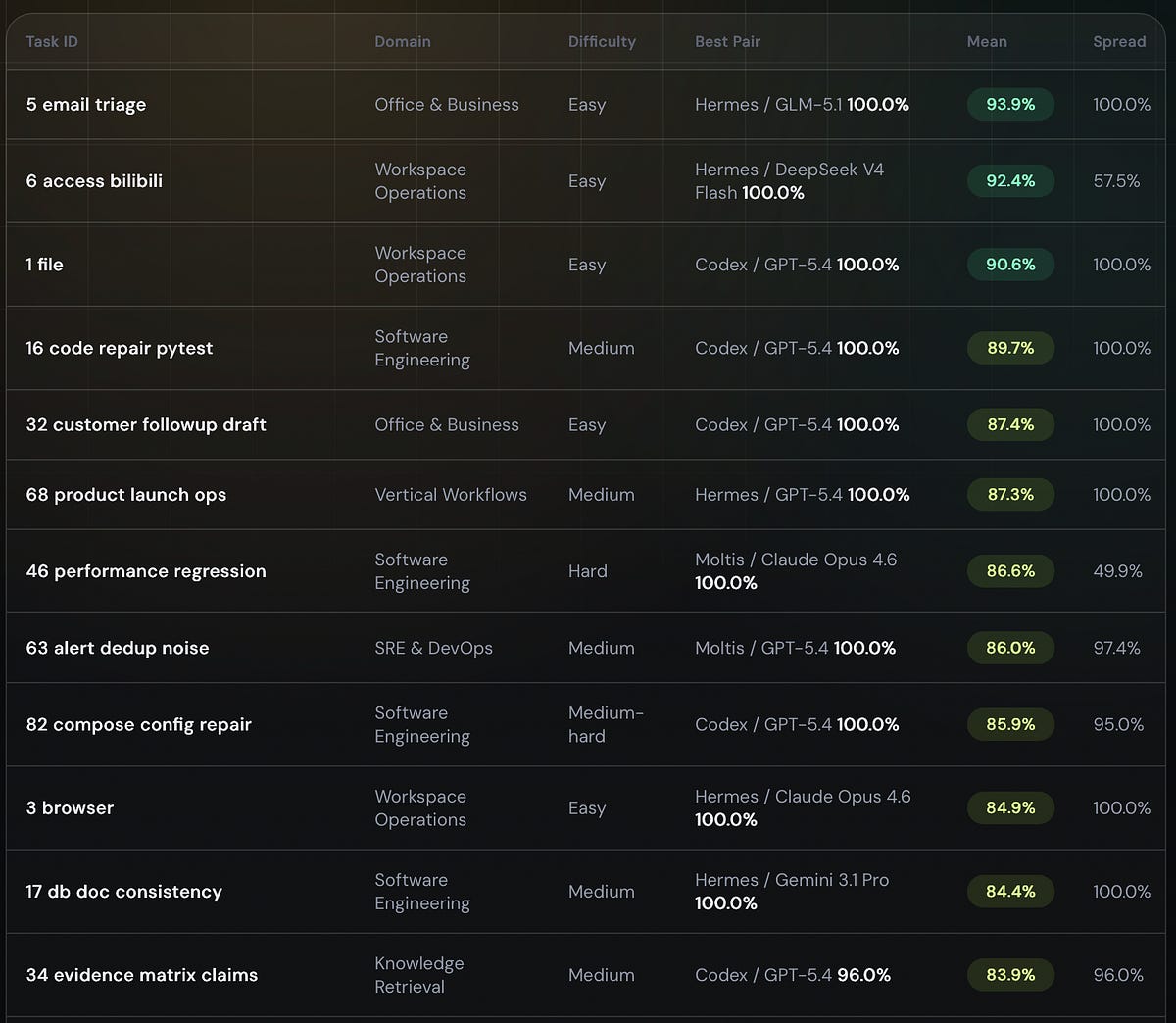
The agents were measured on 106 tasks across eight categories:
Software Engineering
Data, BI & Analytics
Long-running Autonomy
Research & Synthesis
Personal Productivity
Creative & Media Production
Operations & DevOps
Security, Compliance & Policy
The real failure is translation, not reasoning
Looking past the scoreboard and at why runs fail…
Here is what breaks, ranked by how often it shows up in failed trajectories:
Contract / format violations 36.4%. Malformed JSON. A missing ledger row. An incomplete manifest. Interesting, this is also something that stood out in a previous study on why AI Agents fail.
Tool error with no recovery, 24.6%. A command blocks, and the agent never revises the plan.
Evidence not tied to claims, 14.6%. Sources skimmed, assertions unsupported.
Reasoning never committed as an artefact, 11.1%. The thinking happened but the file was never written.
None of these are reasoning failures.
In nearly every case the model understood the task. It produced locally plausible thought. And then the thought never got rendered into the form the environment could check.
The agent knew the answer. It just never wrote it down where it counts.
This is not an intelligence problem. It is a bookkeeping problem, something that is part of the harness’s job.
Execution alignment
The authors give this gap a name, and the name is the most useful idea in the paper.
Execution alignment is the degree to which the harness preserves correspondence among four things:
what the agent reasons about,
what the workspace records,
what the tools actually do, and
what the evaluator checks.
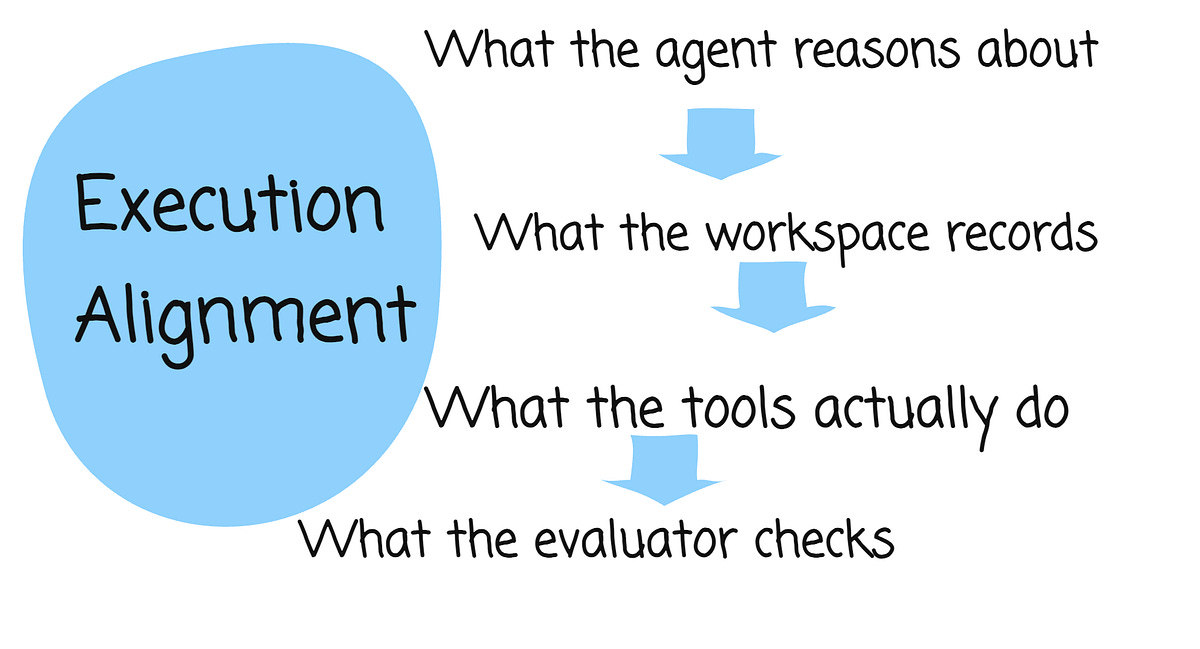
When that correspondence holds, plausible reasoning becomes verified work.
When it breaks, the agent drifts.
Tool feedback arrives and is ignored. Partial progress is made and lost. An intended result is computed and never committed.
The reasoning floats free of the conditions under which the task is judged.
The harness is not a thinker. It is the thing that keeps reasoning tethered to reality.
Think of it as a translator. Think of the ledger as the memory that insists on being consulted.
This reframes the entire job. The relevant question about a harness was never how many tools does it expose or how permissive is the runtime.
The question is whether it preserves the thread between intention and verifiable completion.
The inversion
Here is where the paper gets honest and where the easy version of the argument falls apart.
If the harness carries so much of the weight, you would expect that weight to be constant.
It is not.
Cross-harness variance shrinks as the model gets stronger.
Weak models are hostages to their harness, swap it and their scores swing wildly.
Strong models shrug it off. They tolerate differences in prompting, tool interfaces, state management, and recovery.
They absorb the substrate.
The harness is not a fixed multiplier on intelligence.
It is a crutch whose value decays as the model improves.
That complicates the clean story.
The harness matters most exactly where the model is weakest.
As models climb, the execution layer recedes from view, not because it stopped working, but because the model stopped needing it to.
This raises a real question for anyone building agents today: are you engineering a harness that will continue to matter, or are you building a temporary brace for a model that is about to outgrow it?
Minimal beats elaborate
One more finding…
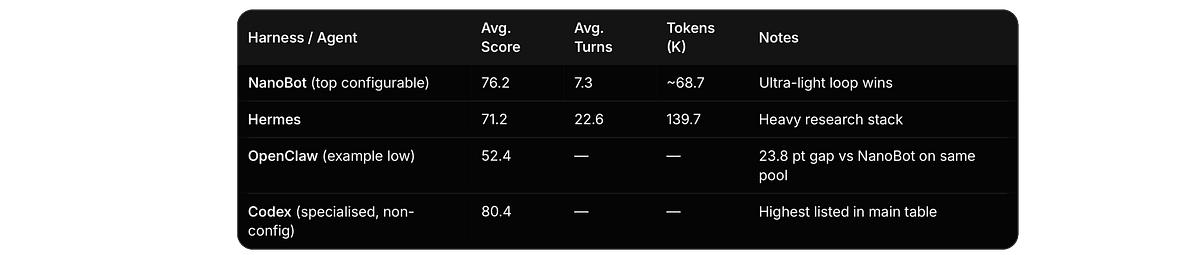
NanoBot, described as an ultra-lightweight agent with a small core loop, took the top configurable score: 76.2, on 7.3 turns, using fewer tokens than anyone above it.
Hermes, the heavier research-oriented stack, burned 139.7K tokens across 22.6 turns and scored lower, at 71.2.
Longer trajectories did not win. More machinery did not win.
The tight, legible loop won.
And the single highest score on the board, 80.4, belonged to Codex, a model-bound coding agent with a specialised stack, not a configurable harness at all.
Specialisation edged out flexibility.
The lesson is not add a harness. It is “a small loop that keeps its books beats a large one that loses them.
The six harnesses configurations
These are the six harnesses evaluated in the benchmark (short descriptions drawn from the paper):
NanoBot (HKUDS)
Ultra-lightweight personal AI agent with a small core loop, memory, MCP support and lightweight deployment.
Top configurable performer on both score and efficiency.
Hermes (Nous Research)
Research-oriented stack with persistent multi-level memory, skills, plugins, and a learning loop that improves from experience.
OpenClaw
Feature-rich, long-running multi-channel assistant runtime with broad ecosystem, plugins, and messaging integrations.
ZeroClaw
Self-hosted system-control runtime focused on performance, single-binary deployment, provider routing, and feature gating.
Moltis
Secure local runtime with sandboxing, vault/passkey support, hooks, and emphasis on local security and persistence.
NullClaw
Low-footprint, minimal-overhead self-hosted execution focused on resource efficiency and sandboxing.
The benchmark evaluates complete harness configurations, not isolated models or isolated tool lists.
Key numbers at a glance
Benchmark scale: 106 tasks, 8 model backends, 6 harnesses, 5,194 trajectories.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.
Harness-Bench: Measuring Harness Effects across Models in Realistic Agent Workflows
LLM agents are increasingly deployed as executable systems that use tools, modify workspaces, and produce concrete…arxiv.org
GitHub - Qihoo360/harness-bench
Contribute to Qihoo360/harness-bench development by creating an account on GitHub.github.com
Harness Bench
Harness Bench is a diagnostic benchmark for measuring model-harness configurations across 106 sandboxed offline agent…www.harness-bench.ai