Agentic AI: Creating An AI Agent Which Can Navigate The Internet
WebVoyager is a vision-enabled web-browsing agent capable of navigating the web. It interprets annotated browser screenshots for each state, and decides on the next step.

Introduction
Considering OpenAI, both the GPT-4o and GPT-4 Turbo models have vision capabilities. Hence the models can ingest images and answer questions based on what is on the image.
Language Models (LMs) could in the past only ingest text; hence single input modality.
But apart from just giving a Foundation Model (FM) an image to ingest and describe, an agentic application, or agent AI, can be used to on the fly annotate web pages, and navigate web pages to reach an answer.
Get an email whenever Cobus Greyling publishes.
Get an email whenever Cobus Greyling publishes. By signing up, you will create a Medium account if you don't already…
WebVoyager
WebVoyager is an AI Agent application which is based on recent study called WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models.
WebVoyager is a vision-enabled web-browsing agent that can control the mouse and keyboard. It operates by analysing annotated browser screenshots for each step and then determining the next action to take.
The agent uses a basic reasoning and action (ReAct) loop architecture. Its unique features include:
The use of Set-of-Marks-like image annotations as UI affordances.
Application within a browser environment, utilising tools to control both the mouse and keyboard.
Autonomous Applications In Real-World Scenarios
AI Agents, also referred to as Agentic Applications have been limited in terms of modality, and was only text based. Hence the agent has got access to a number of tools, like for instance a math library, web text-based search, one or more API calls, and that’s about it.
Hence current agents have access to web tools, but typically only handle one input modality (text) and are evaluated only in simplified web simulators or static web snapshots.
WebVoyager is an innovative Large Multimodal Model (LMM)-powered web agent designed to complete user instructions end-to-end by interacting with real-world websites.
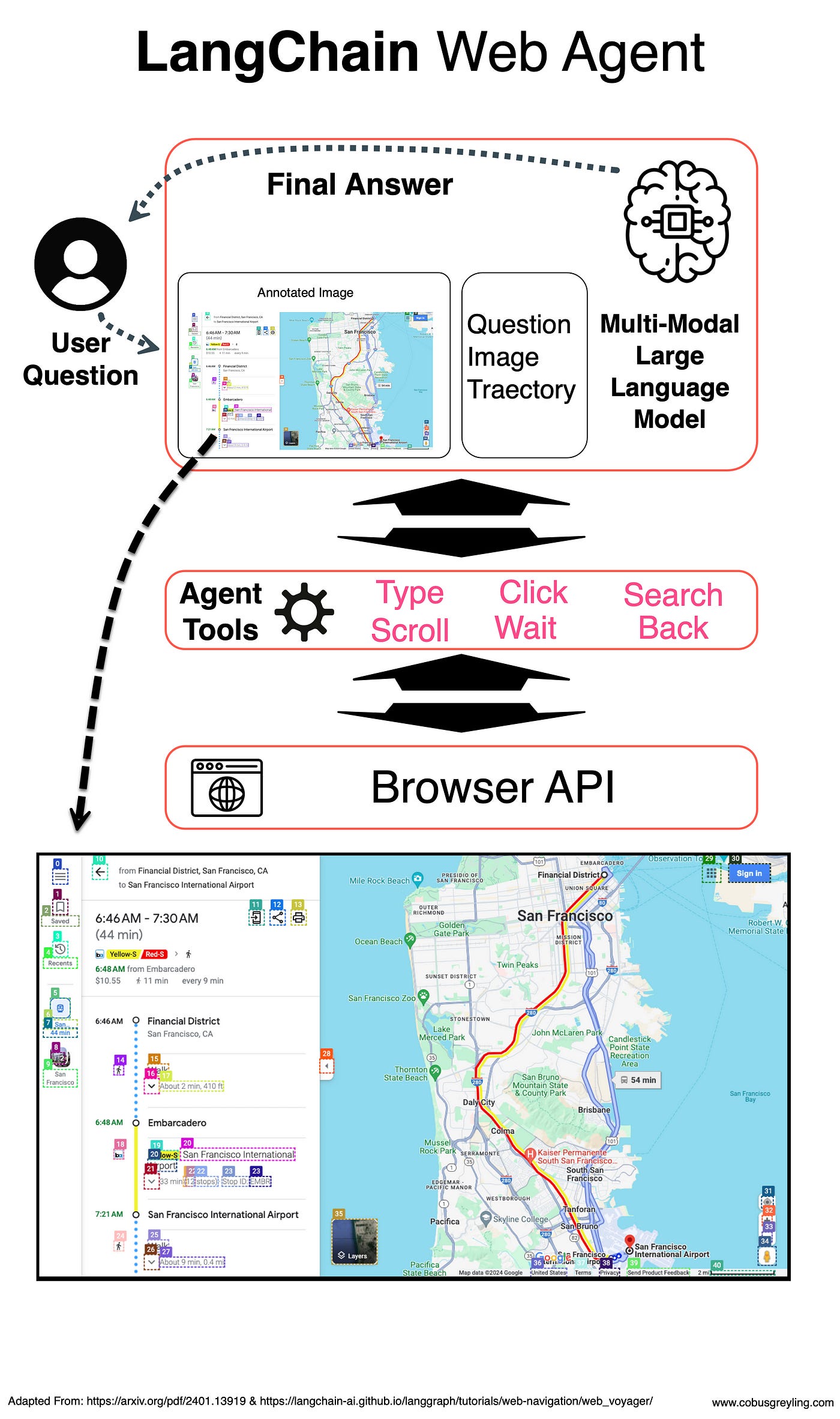
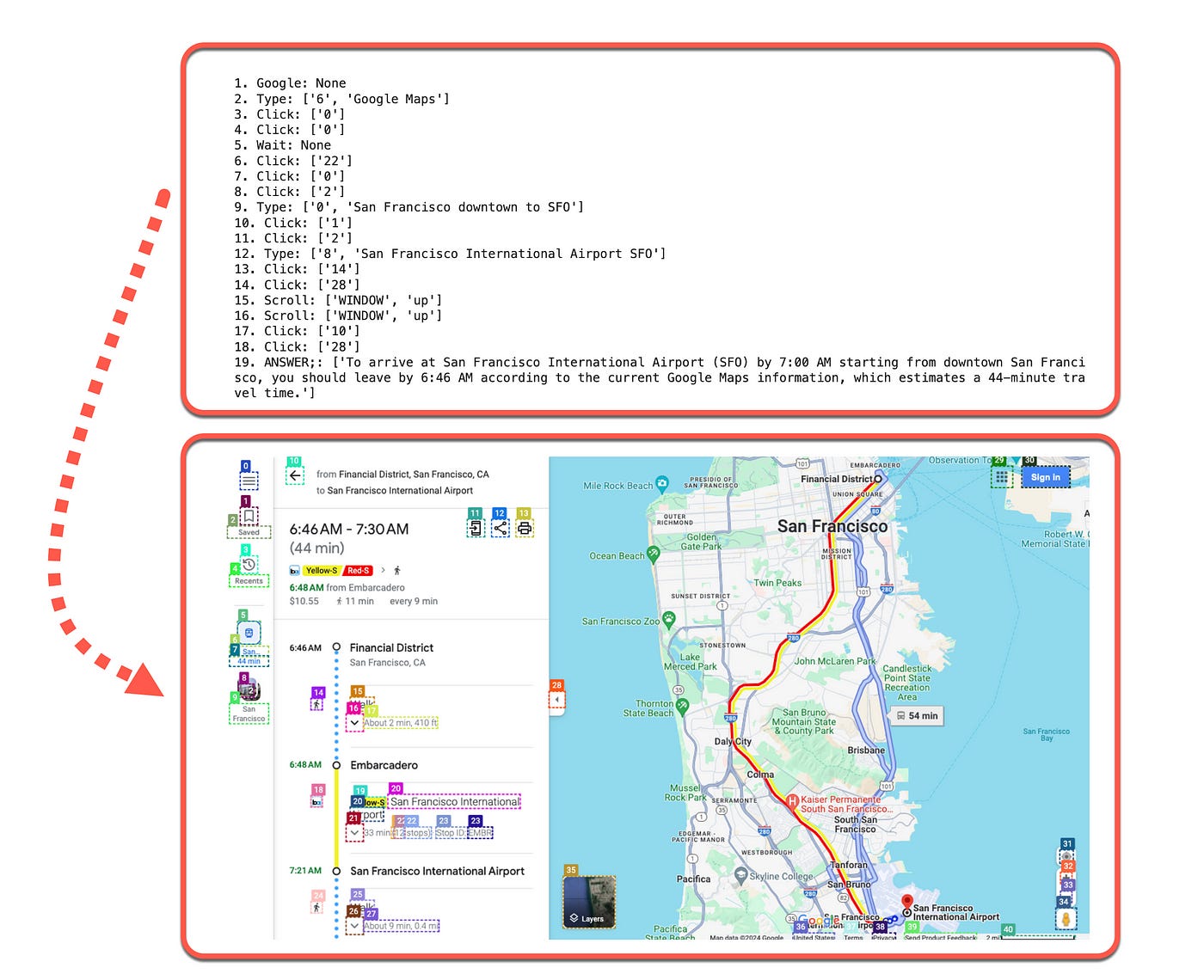
For example, WebVoyager was asked the question: Could you check google maps to see when i should leave to get to SFO by 7 o’clock? starting from SF downtown.
Below is an example of the Python code, together with the annotated screenshot…
res = await call_agent(
"Could you check google maps to see when i should leave to get to SFO by 7 o'clock? starting from SF downtown.",
page,
)
print(f"Final response: {res}")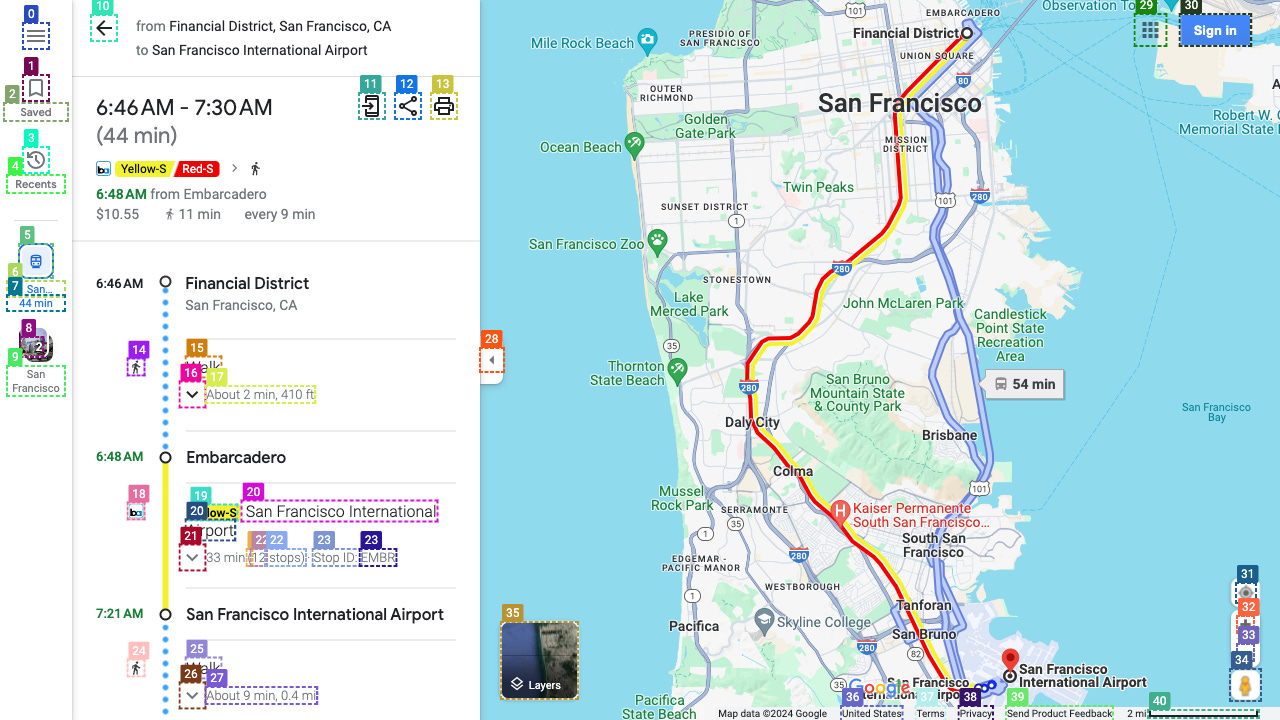
Leveraging Multi-Modal Understanding Capabilities
Recent studies have explored the construction of text-based web browsing environments and how to instruct large language model agents to perform web navigation.
This new development focusses on building multimodal web agents to leverage the environment rendered by browsers through screenshots, thus mimicking human web browsing behaviour.
WebVoyager is a multi-modal web AI agent designed to autonomously accomplish web tasks online from start to finish, managing the entire process end-to-end without any intermediate human intervention.
WebVoyager processes the user query by making observations from screenshots and textual content in interactive web elements, formulates a thought on what action to take.
Actions can include clicking, typing, scrolling, etc. And subsequently executes that action on the websites.
Below the sequence of events are shown for the agent to follow based on annotated screenshots from web navigation.
Observation Space
Similar to how humans browse the web, this agent uses visual information from the web (screenshots) as its primary input.
This approach allows for the bypassing the complexity of processing HTML DOM trees or accessibility trees, which can produce overly verbose texts and hinder the agent’s decision-making process.
Very similar to the approach Apple took with Ferret-UI, the researchers overlay bounding boxes on the interactive elements of the websites to better guide the agent’s action prediction.
This method does not require an object detection module but instead uses GPT-4V-ACT5, a JavaScript tool that extracts interactive elements based on web element types and overlays bounding boxes with numerical labels on the respective regions.
GPT-4V-ACT5 is efficient since it is rule-based and does not rely on any object detection models.
Action Space
The action space for WebVoyager is designed to closely mimic human web browsing behaviour. This is achieved by implementing the most commonly used mouse and keyboard actions, enabling the agent to navigate effectively.
Using numerical labels in screenshots, the agent can respond with a concise Action Format. This method precisely identifies the interactive elements and executes the corresponding actions.
The primary actions include:
1. Click: Clicking on a webpage element, such as a link or button.
2. Input: Selecting a text box, clearing any existing content, and entering new content.
3. Scroll: Moving the webpage vertically.
4. Wait: Pausing to allow webpages to load.
5. Back: Returning to the previous page.
6. Jump to Search Engine: Redirecting to a search engine when stuck on a website without finding an answer.
7. Answer: Concluding the iteration by providing an answer that meets the task requirements.
These actions enable the agent to interact with web pages efficiently, simulating a human-like browsing experience.
Below, Screenshots of A Complete Trajectory of Online Web Browsing
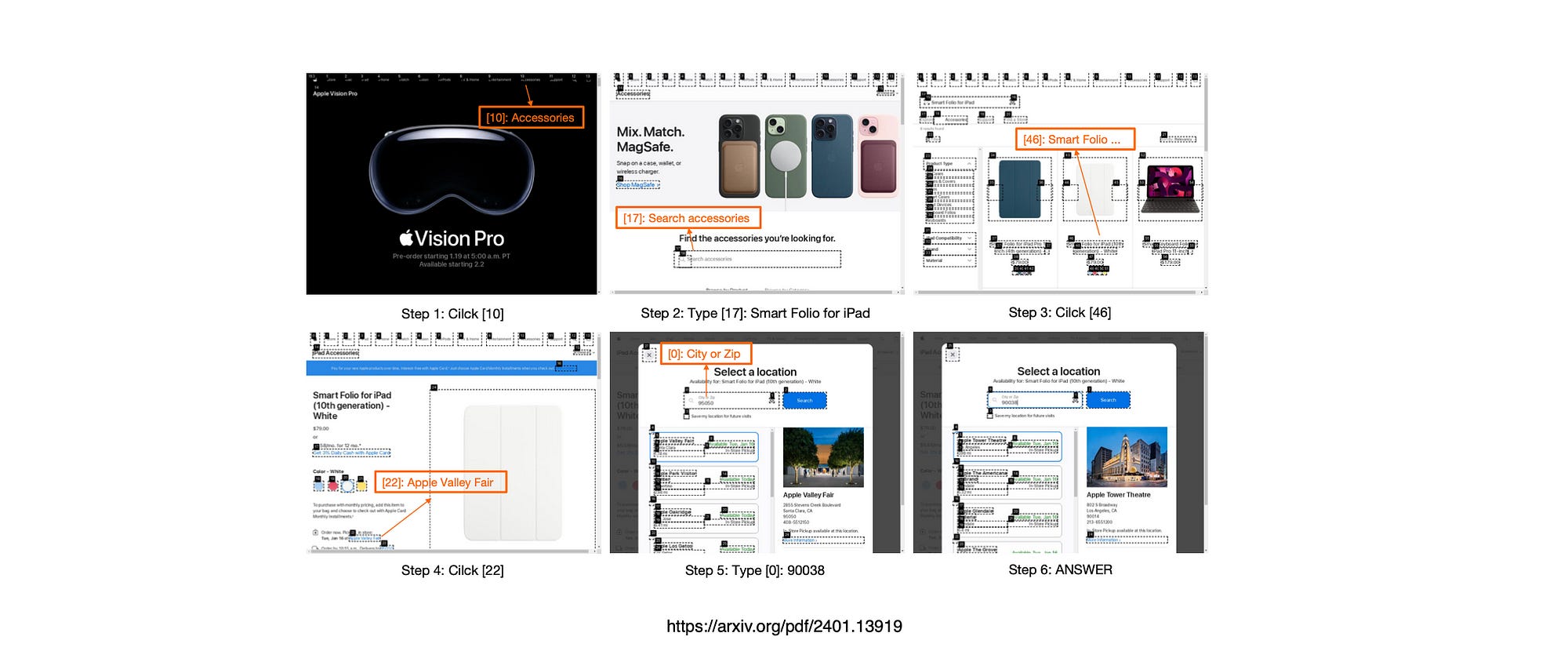
Task:
‘Search Apple for the accessory Smart Folio for iPad and check the closest pickup availability next to zip code 90038.’
Process:
Initial Search: The agent navigates to the Apple website and uses the search function to look for the ‘Smart Folio for iPad.
Product Selection: The agent clicks on the appropriate search result to open the product page.
Check Availability: The agent inputs the zip code ‘90038’ to check the closest pickup availability.
Result: The agent identifies ‘Apple Tower Theatre’ as the closest pickup location.
Insights:
Direct Interaction: Direct interaction with the website is necessary to complete the task.
Multimodal Necessity: Both text and vision inputs are essential for the agent to function effectively as a generalist web agent.
Challenge of Interactive Elements: Websites with more interactive elements pose a greater challenge for the agent due to the increased complexity of navigating and interacting with various components.
Multimodal Necessity: Both text and vision inputs are essential for the agent to function effectively as a generalist web agent.
Challenge of Intractable Elements: Websites with more interactive elements pose a greater challenge for the agent due to the increased complexity of navigating and interacting with various components.
WebVoyager’s ability to handle this task highlights its proficiency in performing complex web navigation and interaction tasks autonomously, leveraging both visual and textual information to achieve accurate and efficient results.
Finally
WebVoyager is an innovative web agent powered by large multimodal models (LMMs) designed to complete real-world web tasks end-to-end by interacting with websites.
Evaluations have shown that WebVoyager outperforms several baselines by effectively leveraging both visual and textual signals.
This research demonstrates the promise of using advanced LMM capabilities to build intelligent web agents. WebVoyager aims to provide a strong foundation for future research focused on developing more versatile and capable web assistants.
System Prompt for WebVoyager. We instruct agents to perform web navigation, along with specific browsing actions and action formats. To enhance efficiency and accuracy, we can incorporate additional general into the prompts. These guidelines should be generic and not about a specific website to ensure generalisability.
Imagine you are a robot browsing the web, just like humans. Now you need to complete a task. In each iteration, you will receive an Observation that includes a screenshot of a webpage and some texts. This screenshot will feature Numerical Labels placed in the TOP LEFT corner of each Web Element. Carefully analyze the visual information to identify the Numerical Label corresponding to the Web Element that requires interaction, then follow the guidelines and choose one of the following actions:
1. Click a Web Element.
2. Delete existing content in a textbox and then type content. 3. Scroll up or down.
...
Correspondingly, Action should STRICTLY follow the format: - Click [Numerical_Label]
- Type [Numerical_Label]; [Content]
- Scroll [Numerical_Label or WINDOW]; [up or down]
- Wait
- GoBack
- Google
- ANSWER; [content]
Key Guidelines You MUST follow:
* Action guidelines *
1) Execute only one action per iteration.
...
* Web Browsing Guidelines *
1) Don't interact with useless web elements like Login, Sign-in, donation that appear in Webpages.
...
Your reply should strictly follow the format:
Thought: {Your brief thoughts (briefly summarize the info that will help ANSWER)} Action: {One Action format you choose}
Then the User will provide:
Observation: {A labeled screenshot Given by User}I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.