Agentic Context Engineering
Context is becoming increasingly important, with exciting advancements around managing and engineering context.

In Short
With the advent of Language Models the focus was initially on different prompt engineering strategies, and how to introduce context. Context meaning the contextual reference for the Language Model at inference.
From here the focus shifted to Small Language Models, and multi-model orchestration. Added to this a data feedback loop, or what NVIDIA calls a data flywheel.
The next step was AI Agents, and there was the notion that one AI Agent is enough, with a number of tools.
As the tools assigned to an AI Agent grew, it was clear that there is a balance required of creating multiple AI Agents, with each having a smaller number of tools assigned to them.
This lead to the need for an orchestration AI Agent, or orchestrator…which needs to orchestrate and manage the AI Agents.
Which in turn lead the notion of Agentic Workflows, where multiple AI Agents are managed in a workflow; Agentic Workflows.
And now we are seeing how methodologies are developed within this new structure, very similar to how methodologies were developed for prompt engineering.
More Background
It has become a commonly accepted principle to inject information snippets (chunks) into prompts at inference to act as a contextual reference.
One can contrast this approach against fine-tuning the model…
Adapting through contexts rather than weights offers several key advantages.
Contexts are human-readable, allowing users and developers to inspect and understand adaptations easily, unlike opaque weight changes via fine-tuning.
Also, new knowledge or instructions can be added dynamically during inference without retraining, supporting real-time updates for evolving tasks.
Contexts are interpretable and explainable for users and developers.
Contexts can be reused or shared across different models, modules, or compound AI systems, facilitating collaboration and efficiency in multi-component setups.
And, with advances in long-context LLMs context-based methods are deployment-friendly, with low-overhead self-improvement without the computational expense of fine-tuning.
It allows for rapid integration of new knowledge at runtime and can be shared across models or modules in a compound system.
But, a recent research paper identified a number of problems, or rather points of improvement, when it comes to context management.
In traditional Retrieval-Augmented Generation (RAG), contexts are pulled from documents to ground LLM outputs, but adaptation methods often fall short in two ways…
Optimisers favour short, generic summaries over detailed retrievals, dropping key domain details like tool tips or error patterns.
This hurts tasks needing nuance, similar to how RAG chunks lose specificity if over-condensed.
And, repeated rewrites shrink accumulated contexts into vague summaries, worsening results.
The ACE Framework
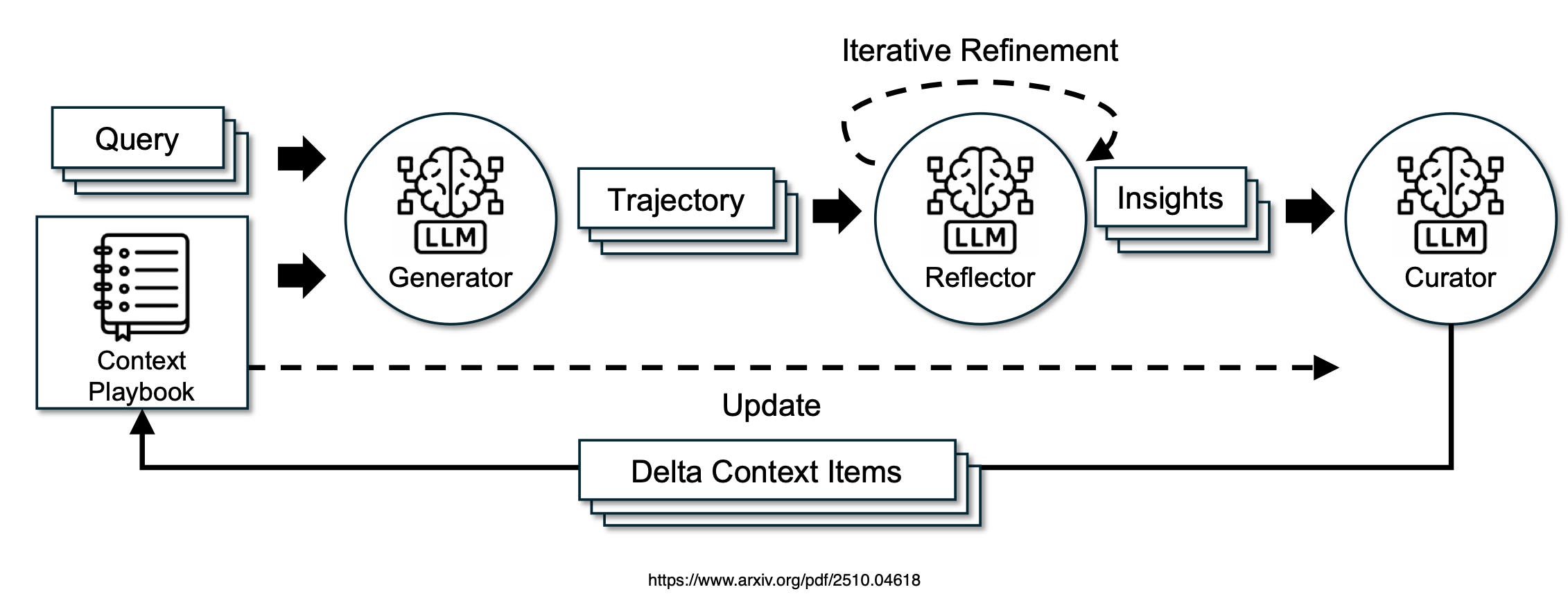
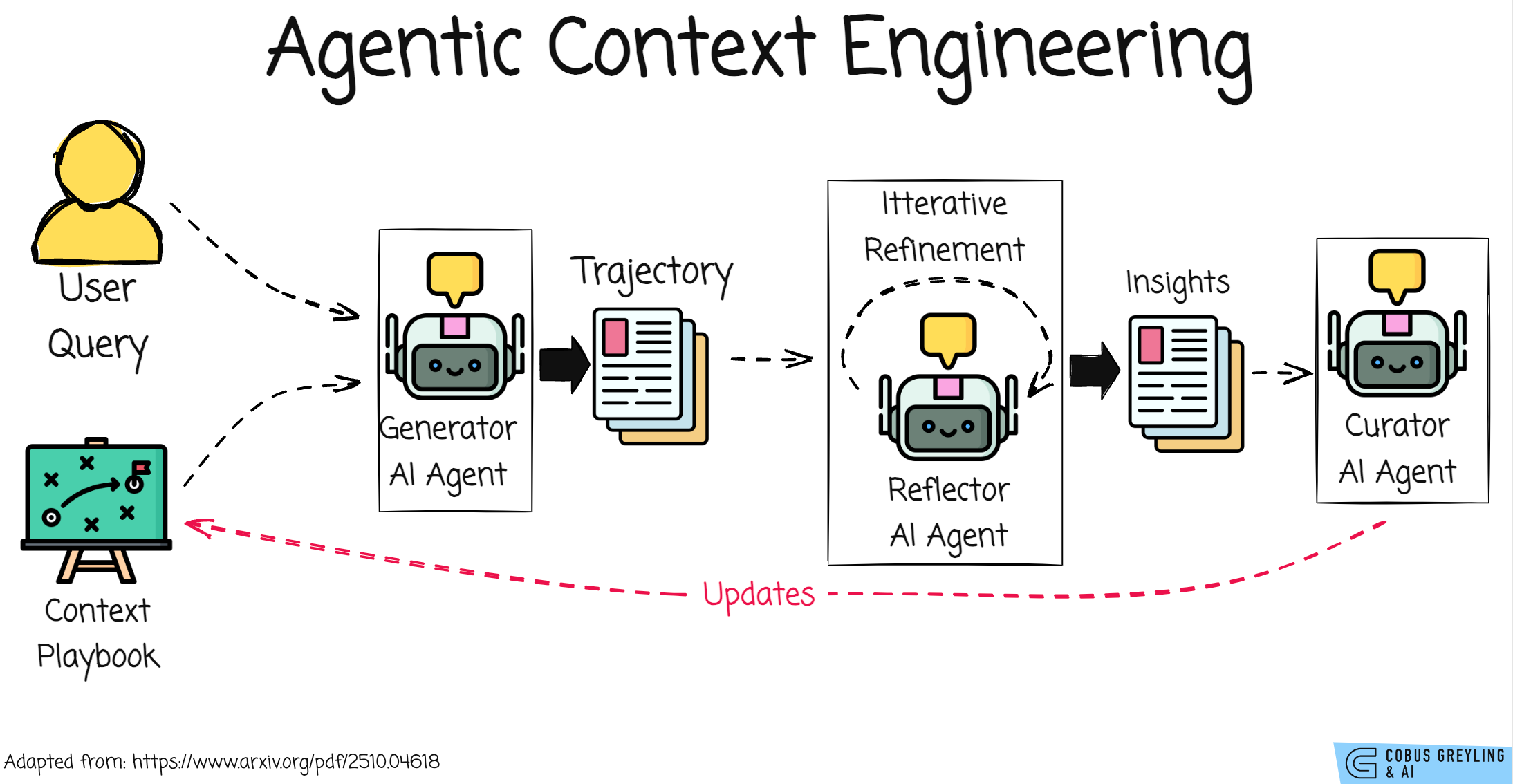
The image above shows the core of the ACE (Agentic Context Engineering) system as a flowchart.
It’s like a team of three specialised workers (all powered by the same language model, but with focused roles) that collaboratively build and improve a playbook (your evolving context or prompt) for an AI.
This playbook starts small and grows smarter over time, collecting tips, strategies, and fixes from real tasks without losing details.
The goal is to help the AI (like a chatbot or agent) get better at complex jobs, such as planning steps.
It’s like a feedback loop inspired by human learning…try something, review what worked or failed.
Add notes to your guidebook — but done efficiently by AI to avoid forgetting useful info.
Multi-Agent Orchestration
On the ACE (Agentic Context Engineering) framework described in the paper, the Generator, Reflector and Curator are explicitly designed as specialised AI agents within an agentic architecture.
Agentic Architecture
This means the system mimics multi-agent collaboration, where each component acts autonomously but interdependently, much like AI Agents in frameworks such as ReAct or LangChain.
They are powered by the same underlying LLM but assigned distinct roles to divide labor efficiently — avoiding overload on a single model.
Generator Agent
Perceives the query and current playbook (context), then acts by generating reasoning trajectories.
The trajectory could look something like this:
Query: “Process time-sensitive transaction involving specific relationships.”
Trajectory:
- Thought: Check criteria relationships before processing items.
- Action: Call API to resolve identities from correct source (using Bullet #001).
- Observation: API returns matched identities; transaction succeeds.
- Feedback: Bullet #001 was helpful (+1 count); avoid assuming defaults without verification.
- Thought: If mismatch, fallback to manual review.
- Action: Execute code snippet for error handling.
- Observation: Error resolved; no further issues.
- End: Task completed successfully.Reflector Agent
Observes the Generator’s output, critiques it for patterns in successes/errors, and refines insights iteratively (up to 5 rounds). It’s the critic that learns from execution signals.
Insights could look like:
{
“id”: “insight_song_map_001”,
“content”: “For artist agreement when processing songs,
use default(list) to map song titles to artist names if
available in song metadata.”, “helpful_count”:
1, “harmful_count”: 0
}Curator Agent
Takes refined insights, synthesises them into structured delta updates (bullet-point knowledge items with metadata), and merges them into the playbook using lightweight logic.
It’s the organiser that curates and prunes for scalability.
Finally
If you are still reading, thank you for your time, I don’t take it for granted…
Finally, key elements to keep in mind is latency, cost and other overheads.
And are the necessary benefits realised by the implementation; general guidance is to start as simple as possible and iterated and augment based a data feedback loop.
Starting way too complex, and then trying to optimise and tweak is a much harder task.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. Language Models, AI Agents, Agentic Apps, Dev Frameworks & Data-Driven Tools shaping tomorrow.
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context…www.arxiv.org
COBUS GREYLING
Where AI Meets Language | Language Models, AI Agents, Agentic Applications, Development Frameworks & Data-Centric…www.cobusgreyling.com
Memory, Context & AI Agents
There are a number of key components to AI Agents which are well established…Language Models, Tools, Function Calling…cobusgreyling.medium.com
Fascinating. Your clear breakdown of the shift from prompt engineering to complex agentic workflows, and the role of orchestrators, clarifies the practical path for robust AI. As a developer, I agree multple specialized agents make more sense. Thanks for this insightful analysis.