Agentic RAG With LlamaIndex
The topic of Agentic RAG explores how agents can be incorporated into existing RAG pipelines for enhanced, conversational search and retrieval.


Introduction
Considering the architecture below, it is evident how Agentic RAG creates an implementation which easily scales. New documents can be added with each new set being managed by a sub-agent.

The basic structure of LlamaIndex’s approach called Agentic RAG is shown in the diagram below where a large set of documents are ingested, in this case it was limited to 100.
The large corpus of data is broken up into smaller documents. An agent is created for each document, and each of the numerous document agents have the power of search via embeddings and to summarise the response.
A top-level agent is created over the set of document agents. The meta-agent / top-level agent performs tool retrieval and then uses Chain-of-Thought to answer the user’s question.
The Rerank endpoint computes a relevance score for the query and each document, and returns a sorted list from the most to the least relevant document.

Notebook Example
Here you will find a Colab notebook with a fully working and executed example of this implementation.
To run the notebook, you will need an OpenAI and Cohere API key…
import os
import openai
import cohere
os.environ["OPENAI_API_KEY"] = "Your API Key goes here"
os.environ["COHERE_API_KEY"] = "Your API Key goes here"For each document agent, the system prompt is:
You are a specialized agent designed to answer queries about the
`{file_base}.html` part of the LlamaIndex docs.
You must ALWAYS use at least one of the tools provided when answering a
question; do NOT rely on prior knowledge.The system prompt for the meta-agent /top-agent:
You are an agent designed to answer queries about the documentation.
Please always use the tools provided to answer a question.
Do not rely on prior knowledgeWorking Example
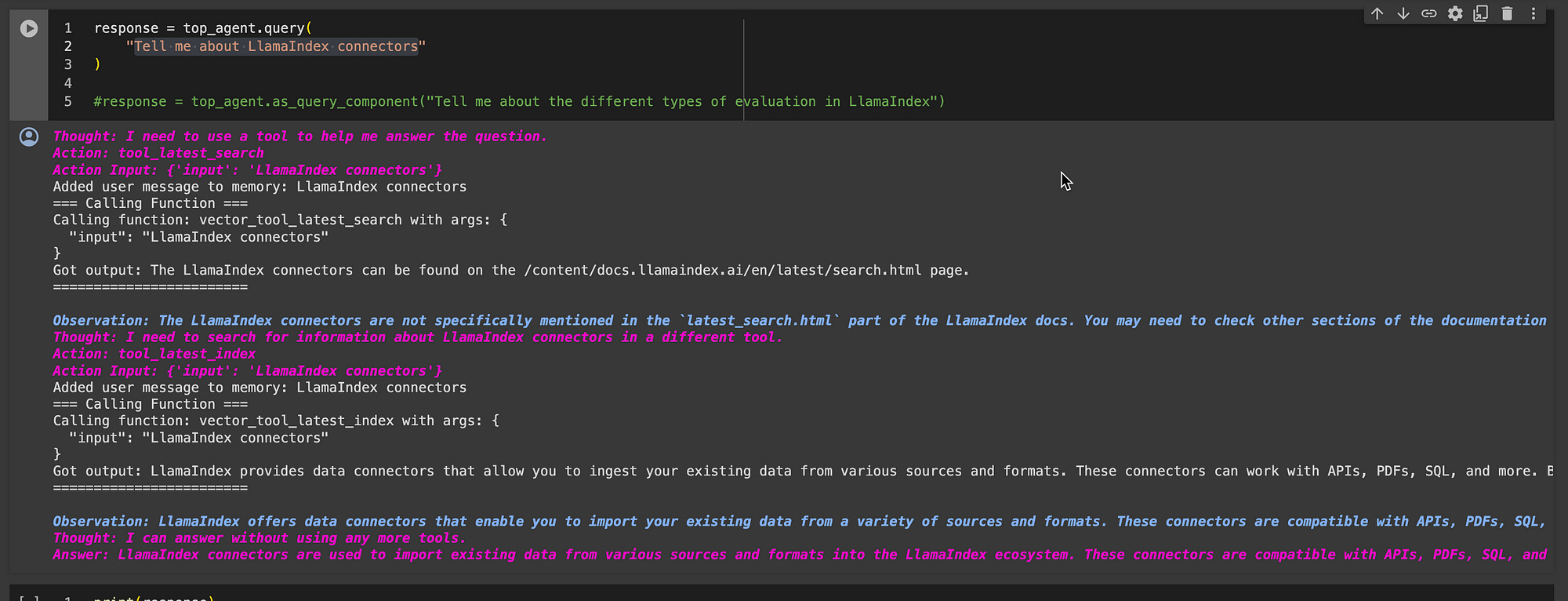
I asked the agent the following question:
Tell me about LlamaIndex connectors
Below is the detailed answer generated by the agent:
Thought: I need to use a tool to help me answer the question.
Action: tool_latest_search Action Input: {‘input’: ‘LlamaIndex connectors’}
Added user message to memory: LlamaIndex connectors
=== Calling Function ===
Calling function: vector_tool_latest_search with args: {
“input”: “LlamaIndex connectors”
}
Got output: The LlamaIndex connectors can be found on the /content/docs.llamaindex.ai/en/latest/search.html page. ========================
Observation: The LlamaIndex connectors are not specifically mentioned in the `latest_search.html` part of the LlamaIndex docs. You may need to check other sections of the documentation for detailed information about LlamaIndex connectors.
Thought: I need to search for information about LlamaIndex connectors in a different tool.
Action: tool_latest_index Action Input: {‘input’: ‘LlamaIndex connectors’}
Added user message to memory: LlamaIndex connectors
=== Calling Function ===
Calling function: vector_tool_latest_index with args: {
“input”: “LlamaIndex connectors”
}
Got output: LlamaIndex provides data connectors that allow you to ingest your existing data from various sources and formats. These connectors can work with APIs, PDFs, SQL, and more. By using LlamaIndex connectors, you can easily bring your data into the LlamaIndex ecosystem and make it accessible for natural language access and retrieval. ========================
Observation: LlamaIndex offers data connectors that enable you to import your existing data from a variety of sources and formats. These connectors are compatible with APIs, PDFs, SQL, and more. Utilizing LlamaIndex connectors allows you to seamlessly integrate your data into the LlamaIndex ecosystem, making it readily available for natural language access and retrieval.
Thought: I can answer without using any more tools.
Answer: LlamaIndex connectors are used to import existing data from various sources and formats into the LlamaIndex ecosystem. These connectors are compatible with APIs, PDFs, SQL, and more, allowing seamless integration of data for natural language access and retrieval.
Below is a snipped from the Colab notebook:
This complex implementation from LlamaIndex is an example of multi-document agents which can:
Select documents relevant to a user query
Execute an agentic loop over the documents relevant to the query; including chain-of-thought, summarisation and reranking.
In Conclusion
This implementation by LlamaIndex illustrates a few key principles…
Agentic RAG, where an agent approach is followed for a RAG implementation adds resilience and intelligence to the RAG implementation.
It is a good illustration of multi-agent orchestration.
This architecture serves as a good reference framework of how scaling an agent can be optimised with a second tier of smaller worker-agents.
Agentic RAG is an example of a controlled and well defined autonomousagent implementation.
One of the most sought-after enterprise LLM implementation types are RAG, Agentic RAG is a natural progression of this.
It is easy to envisage how this architecture can grow and expand over an organisation with more sub bots being added.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.