Agentic Workflows To Balance Autonomy with Human Oversight
Agentic workflows are changing how knowledge workers are interacting with technology.

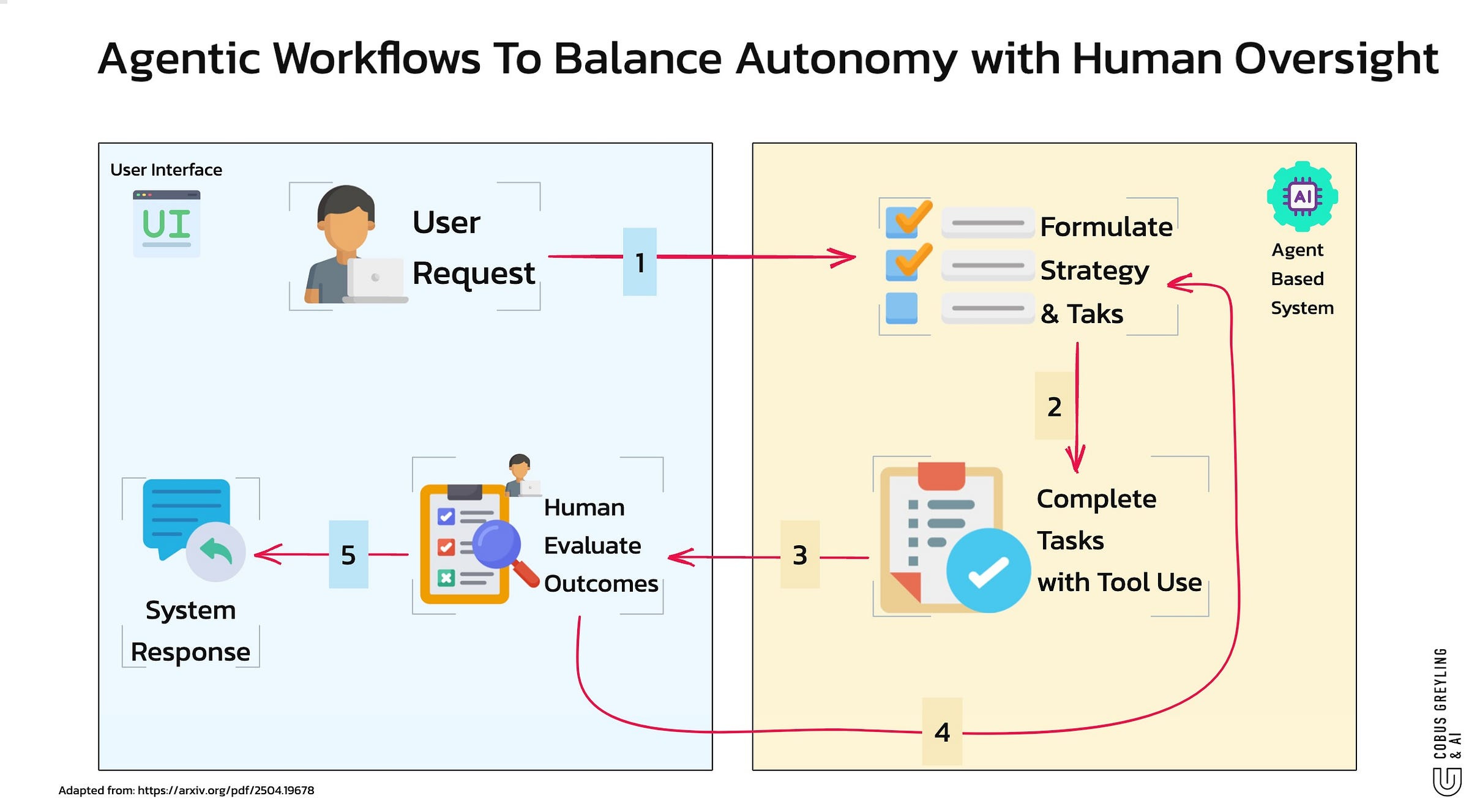
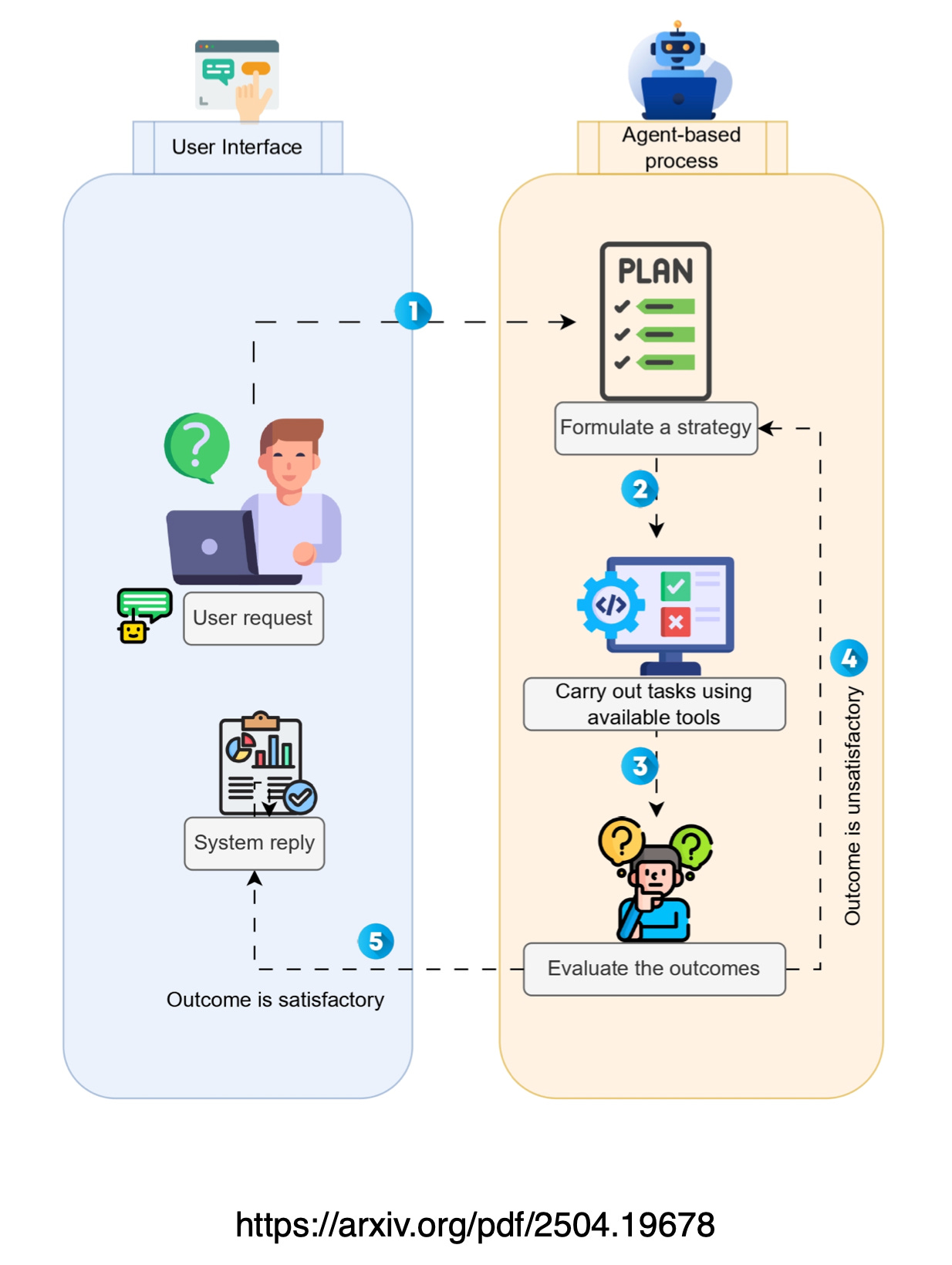
While AI Agents introduce a new level of autonomy, they still require strong human supervision to ensure accuracy and reliability.
What Are Agentic Workflows?
Agentic workflows refer to processes where AI Agents — powered by advanced large language models (LLMs) — execute multi-step tasks autonomously.
Unlike traditional LLMs that generate text in response to prompts, AI Agents can
plan,
reason, and
interact with external tools, such as APIs, databases, or web browsers, to achieve specific goals.
For example, an AI Agent might book a flight, draft an email, or scrape data from a website by breaking down the task into actionable steps.
Workflows leverage a more modular approach AI Agent frameworks, that integrate LLMs with toolkits for decision-making and task orchestration.
- Also follow me on LinkedIn or on X! 🙂
The Role of Human Supervision
While AI Agents can operate independently, the study highlights that their autonomy is most effective when paired with human supervision.
Humans provide
context,
set objectives, and
intervene
when AI Agents misinterpret tasks or produce inaccurate results.
For instance, an AI Agent tasked with browsing the web for market research might misinterpret ambiguous queries or fetch outdated data.
Human supervisors can clarify instructions, verify sources, or adjust the agent’s approach to ensure alignment with the intended outcome.
Challenges in Accuracy & Insights from Benchmarks
The study proposes a taxonomy of approximately 60 benchmarks developed between 2019 and 2025 to evaluate AI Agents across domains like general knowledge reasoning, mathematical problem-solving, code generation and multimodal tasks.
In my article The Hard Truth About AI Agents & Accuracy I look at the limitations of AI Agents in terms of accuracy and reliability, despite the hype surrounding their capabilities.
Key points include:
Speech Recognition Benchmark
I note that accurate speech recognition, now embedded in apps like Grok and ChatGPT, has reached human-level performance (95%+ accuracy), as exemplified by Google’s ML Voice Recognition surpassing this threshold by 2017.
However, this success is not yet mirrored in general AI Agent performance.
AI Agent Accuracy
Current AI Agents struggle with low success rates.
For instance, the top-performing agents like S2 achieves only a 34.5% success rate with 50 steps, meaning over 60% failure.
Even advanced models like Claude, which leads in computer-use tasks, scores only 14.9% on the OSWorld benchmark, far below human-level performance (70–75%).
OpenAI’s Operator achieves 30–50% accuracy in web and computer tasks, still lagging behind human capability.
Overfitting and Benchmarks
I am quite sure researchers often overfit AI models to score high on benchmarks, which may not reflect real-world performance.
This inflates perceived capabilities and masks true limitations.
Complexity and Cost
AI Agents are becoming more complex, integrating functions like computer vision, task decomposition and web search.
But, this increases computational costs, as AI Agents often call underlying language models multiple times.
The article suggests a shift toward granular frameworks like LangChain and LlamaIndex for better efficiency.
Human Supervision
AI Agents can operate with weak human supervision, allowing minor corrections along the way, but their high cost and limited accuracy make them less viable for widespread enterprise use compared to more reliable agentic workflows.
While AI agents are advancing, their current accuracy and cost inefficiencies make them unsuitable for many production environments,
The Hard Truth About AI Agents & Accuracy
The length of tasks (measured by how long they take human professionals) that generalist autonomous frontier model…cobusgreyling.medium.com
Enhancing Accuracy with Human-AI Collaboration
To address these accuracy challenges, the study advocates for stronger human-AI collaboration protocols.
By combining the scalability of AI Agents with human judgment, agentic workflows can achieve higher reliability.
For example, frameworks that allow humans to set clear parameters or review intermediate outputs can catch errors early.
Additionally, iterative improvements in benchmark design — focusing on real-world scenarios — can help developers fine-tune agents for better performance.
Conclusion
Agentic workflows represent a leap toward autonomous AI systems capable of tackling complex tasks with minimal human input.
However, as the study highlights, their autonomy is most effective when paired with robust human supervision.
Benchmarks reveal that while AI Agents show promise in computer use and web browsing, accuracy issues persist, particularly in dynamic or ambiguous scenarios.

Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
Large language models and autonomous AI agents have evolved rapidly, resulting in a diverse array of evaluation…arxiv.org
COBUS GREYLING
Where AI Meets Language | Language Models, AI Agents, Agentic Applications, Development Frameworks & Data-Centric…www.cobusgreyling.com
The Hard Truth About AI Agents & Accuracy
The length of tasks (measured by how long they take human professionals) that generalist autonomous frontier model…cobusgreyling.medium.com