AgentInstruct Uses Agentic Flows To Create Synthetic Training Data
For a while now, Microsoft has been working on creating purpose specific, fine-grained, high quality synthetic training data.

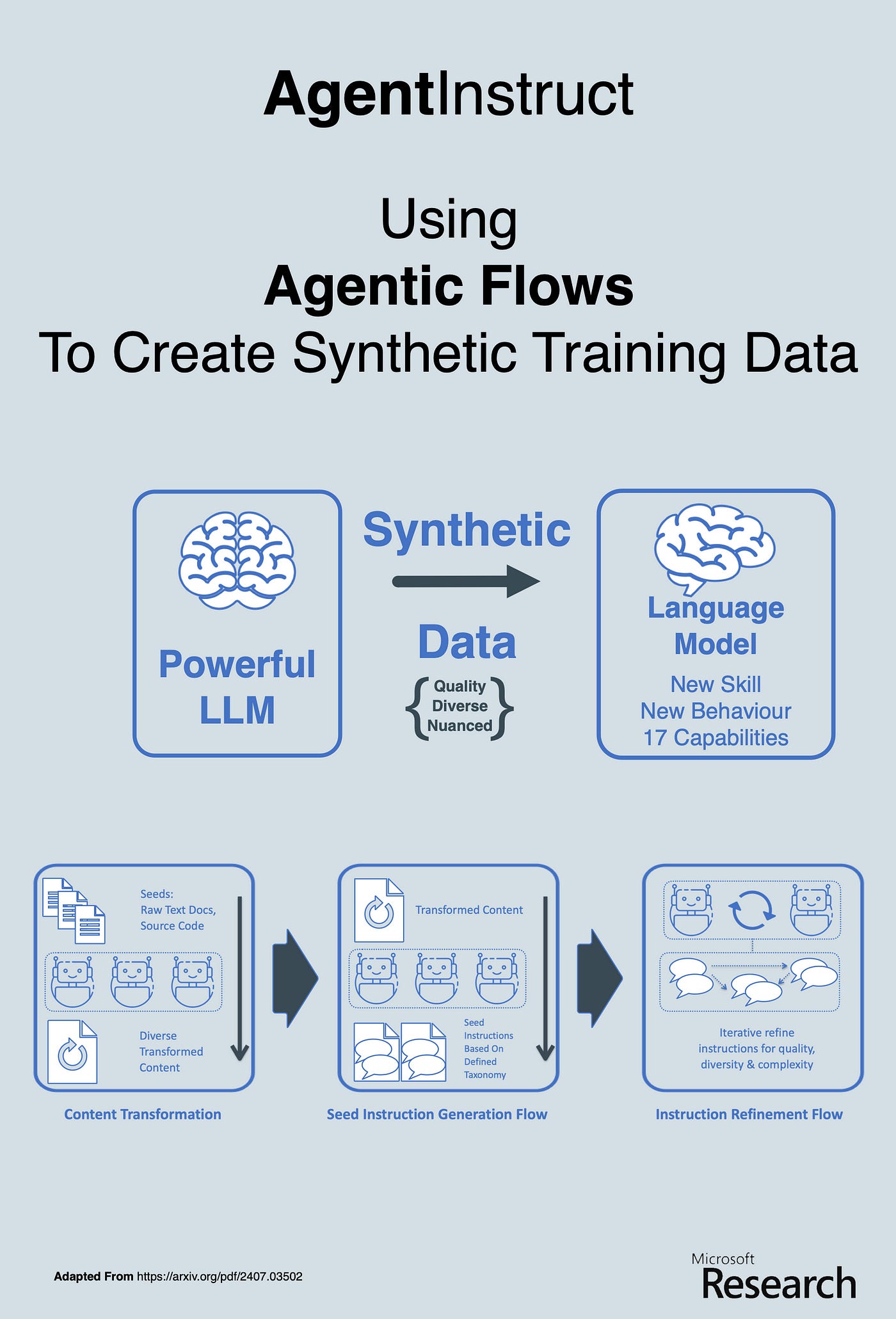
This training data is created by larger more capable models, with specific guardrails to ensure the generated data is quality, diverse and nuanced. Previous methods employed human supervision and annotation to ensure the data is nuanced on a very granular level, now agentic flows are used.
AgentInstruct, an extensible agentic framework for automatically creating large amounts of diverse and high-quality synthetic data.
Consider for a moment the card below, on how Microsoft trained the Phi-3 SLM. This simple procedure outlines how they ensured the data is diverse and repetition is avoided.

Introduction
There was this fear circulating a while ago, that we are running out of training data for Large Language Models.
Then we start seeing the value of Small Language Models, and the knowledge intensive nature of Language Models (LMs) became less important.
The next step was to train LMs, not to imbue them with knowledge, but rather specific behaviour and abilities. This behaviour and abilities include reasoning, chain of thought and more.
Hence the ontology of training data became much more important, and training data required to be fine-grained and nuanced and organised according to a certain topology.
Human supervision and annotation play a big role in this process, but by leveraging agentic workflows, this process of creating synthetic data can be automated to a large degree.
This research from Microsoft changes this by employing agentic flows.
AgentInstruct can also be an avenue for organisations to fine-tune SLMs with company specific data which has been put through the AgentInstructprocess.
Synthetic data accelerated the development of LLMS
Synthetic Data Meets Agents
Last year saw the rise of agentic workflows, particularly multi-agent ones.
These workflows can generate high-quality data that surpasses the capabilities of the underlying LLMs by incorporating reflection and iteration, allowing agents to review, critique, and improve solutions.
They also utilise tools such as search APIs, calculators, and code interpreters to address LLM limitations.

Multi-agent workflows offer additional benefits, such as simulating scenarios to generate both new prompts and corresponding responses. They also automate data generation workflows, reducing or eliminating the need for human intervention in some tasks.
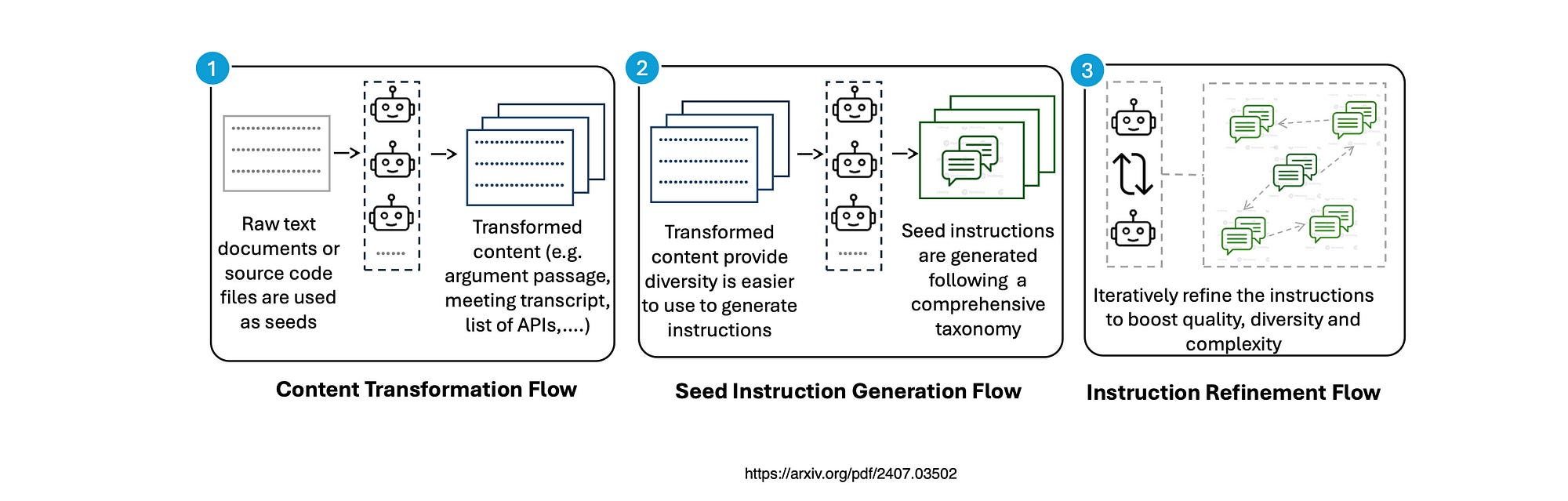
AgentInstruct Capabilities
High-Quality Data
By leveraging powerful models like GPT-4, along with tools such as search APIs and code interpreters, AgentInstruct ensures the generation of high-quality data.
Diverse Data
AgentInstruct produces both prompts and responses using a large number of agents equipped with powerful LLMs, various tools, and reflection flows.
It employs a taxonomy with over 100 subcategories to ensure diversity and quality in the prompts and responses generated.
Large Quantities of Data
Operating autonomously, AgentInstruct can generate vast amounts of data, applying flows for verification and filtering. It eliminates the need for seed prompts by using raw documents for seeding.
High Quality Synthetic Data
This challenge stems from the difficulty in creating high-quality and diverse synthetic data, which necessitates significant human effort in curation and filtering.
A common approach involves using powerful models like GPT-4 to generate responses to a set of prompts. This process is often enhanced by eliciting explanations or step-by-step instructions and employing complex prompting techniques to improve answer quality.
Using raw data (such as unstructured text documents or source code) as seeds offers two advantages. Firstly, it is abundant, enabling the creation of vast and diverse datasets using AgentInstruct.
Secondly, bypassing existing prompts, either as-is or after paraphrasing, can foster learning of more general capabilities rather than specific benchmarks.
The AgentInstruct approach is conducive to enhancing larger, more capable models due to its ability to generate new prompts and produce responses of higher quality than the LLM used in the agentic flow, facilitated by tools and reflection.
In Conclusion
The AgentInstruct approach offers an effective solution for generating diverse, high-quality data for model post-training.
This method employs agentic flows to create synthetic data, addressing common issues such as lack of diversity and the need for extensive human curation.
By leveraging an agentic framework, AgentInstruct can produce custom datasets from unstructured data sources, enhancing model training and skill development.
The approach’s effectiveness is evidenced by the improved performance of the Orca-3 model, which benefited from a 25 million pair dataset generated by AgentInstruct.
The researchers believe that using agentic flows for synthetic data creation is valuable for all stages of model training, including pre-training, post-training, and domain/task specialisation.
This capability to generate diverse, high-quality instruction data from unstructured content could lead to partial or completely automated pipelines for model customisation and continuous improvement.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.