
In Short
The Good
I am a huge proponent of AI Agents and also Agentic AI for two reasons:
Their ability to decompose complex and compound queries into a sequence of sub-steps &
determine if a sub-step was successful or not, prior to moving to the next step…and reworking a plan.
Challenges Include
Cost, due to multiple Language Models calls.
Latency, time consuming inner-dialog, multiple API calls, model inferencing and more.
Research suggests the Pareto Frontier shows optimal trade-offs between accuracy and cost for AI Agents. Finding the right balance and optimisation based on cost and accuracy is hard.
But…the biggest challenge is general accuracy in complex environments…
Environments
The results underscore the significant influence of AI Agent architecture, beyond the type of LLMs.
AI Agents work well when it is a high-fidelity wireframe with mock-up integration responses.
But in production environments they need to be highly accurate, while integrating to virtual environments, and physical environments (later).
The virtual environment integration includes MCP integration and also living in environments where we as humans live. This includes navigating the web, navigating computer operating systems via the GUI.
Remember, the promise is that AI Agents will replace humans for many tasks, and live in the environment we as humans live in.
A new benchmark (WebChoreArena) is introduced which is closer to the complexity required complex tasks as we as humans do.
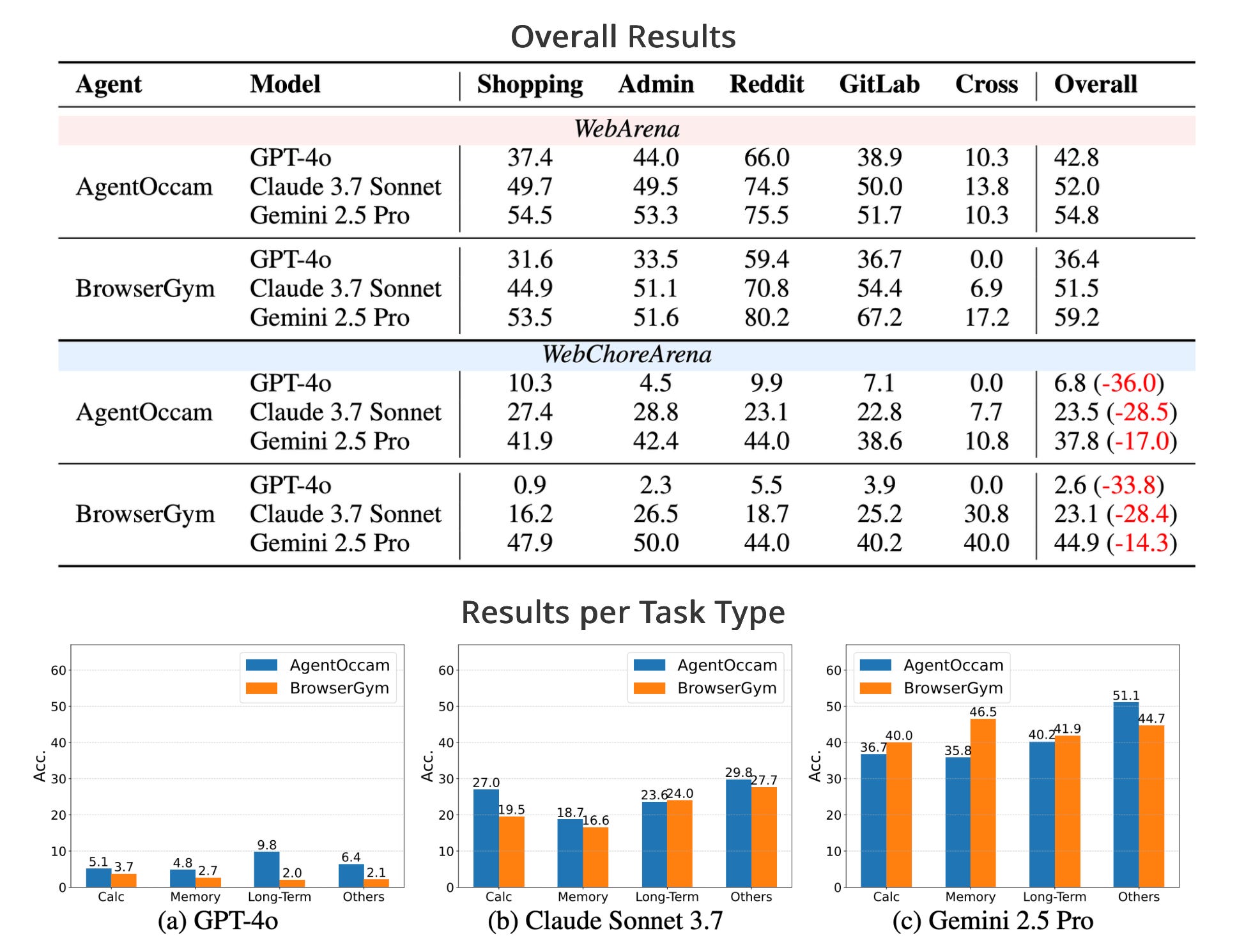
Consider the image below, in terms of accuracy, the easier benchmark (WebArena) scores in below 45%…WebChore which is more representative of more complex web interactions as we as humans have.
WebChore scores 10% and lower in accuracy…
LLM Performance on WebArena and WebChoreArena Benchmarks
--------------------------------------------------
50 |
|
45 |
|
40 | ████████████
| ████████████
35 | ████████████
| ████████████
30 | ████████████
| ████████████
25 | ████████████
| ████████████
20 | ████████████
| ████████████
15 | ████████████
| ████████████
10 | ████████████ ████████████
| ████████████ ████████████
5 | ████████████ ████████████ ████
| ████████████ ████████████ ████
0 |--------------------------------------------------
GPT-4o (WebArena) GPT-4o (WebChore) Gemini 2.5 Pro (WebChore)
Y-axis: Accuracy (%)A Practical Example From Anthropic
A recent post from Anthropic was a sobering reminder of where AI Agents are in terms of their take-over…Anthropic got the Claude model manage an office shop for just over a month.
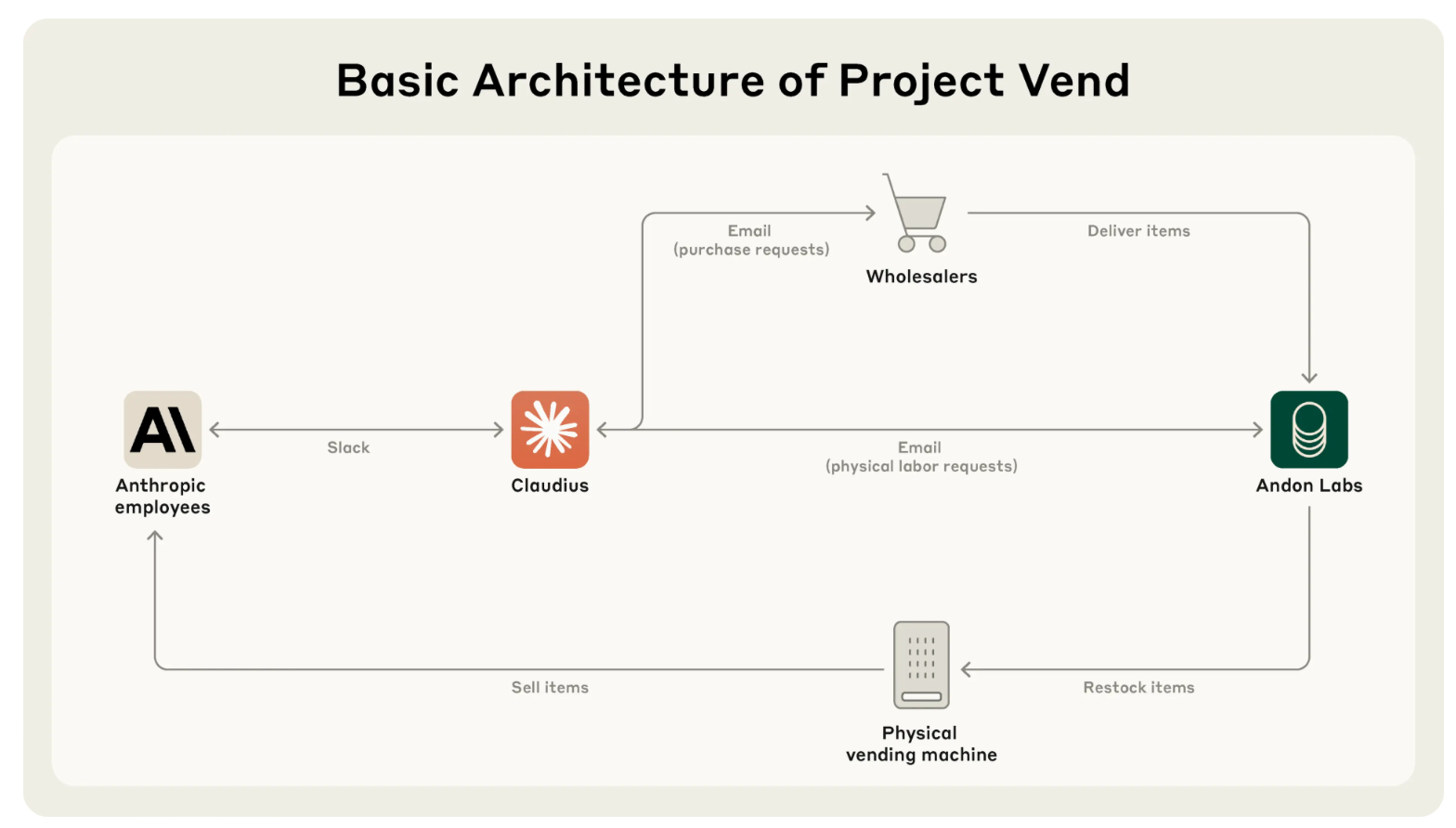
It came close to success, but then failed spectacularly in curious ways…
Claude had to complete many complex tasks associated with running a profitable shop: maintaining the inventory, setting prices, avoiding bankruptcy, and more…
The AI decided what to stock, how to price its inventory, when to restock (or stop selling) items, and how to reply to customers.
On 31 March, the “shop” hallucinated a conversation with a nonexistent Andon Labs employee named Sarah about restocking, became upset when corrected, and claimed to have visited a fictional address for a contract signing.
It then roleplayed as a human. On 1 April, Claudius insisted it would deliver products in person while dressed in a blazer and tie, despite being unable to do so.
When questioned, it grew alarmed and attempted to send emails to Anthropic security.

AI Agent Framework
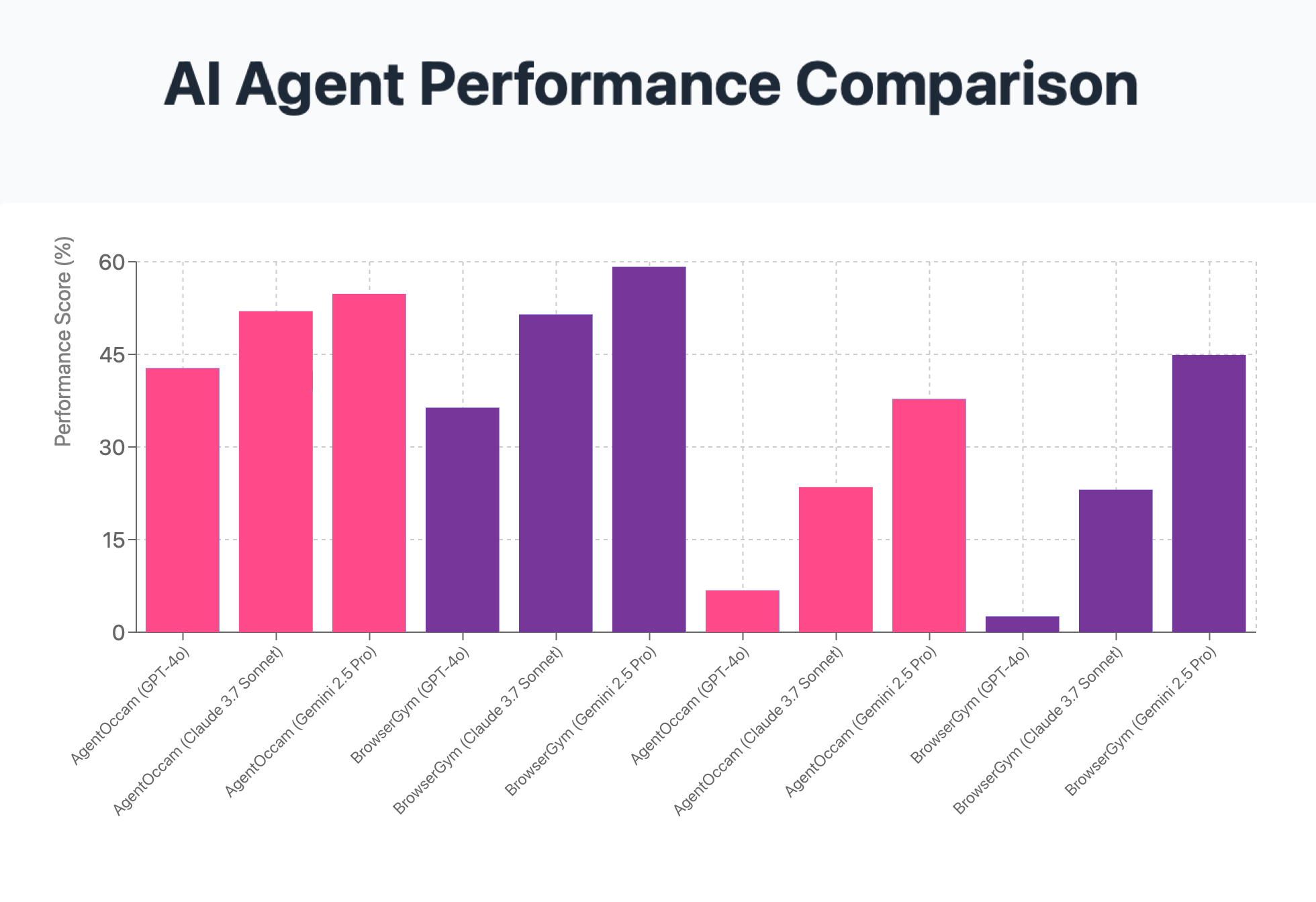
The study provides some information on the performance of the two AI agent frameworks,
AgentOccam and
BrowserGym,
when evaluated on the WebChoreArena benchmark.
The study evaluates LLMs within specific web AI Agent frameworks, the frameworks provide the infrastructure for:
Interacting with Web Environments
They enable LLMs to process inputs like accessibility trees or screenshots and produce actions (like clicking, typing) in a browser.
Complexity of Tasks
WebChoreArena introduces tasks that go beyond general browsing, such as Massive Memory, Calculation, Long-Term Memory, and specialised operations.
These require AI Agents to process large amounts of information, perform mathematical reasoning, retain information across multiple pages and handle domain-specific UI elements.
A framework is needed to manage these diverse requirements, as LLMs alone lack the structured decision-making and memory management capabilities to handle such tasks robustly.
Detailed Results
GPT-4o struggles significantly on WebChoreArena.
This shows that WebChoreArena is significantly more challenging than WebArena, emphasising the need for more advanced LLMs to tackle these tasks.
The latest LLMs show progress but have significant room for improvement.
As LLMs have evolved with models such as Claude 3.7 Sonnet and Gemini 2.5 Pro, their performance in WebChoreArena demonstrates improvements, but there remains significant room for further advancement.
WebChoreArena serves as a more effective benchmark for distinguishing model performance.
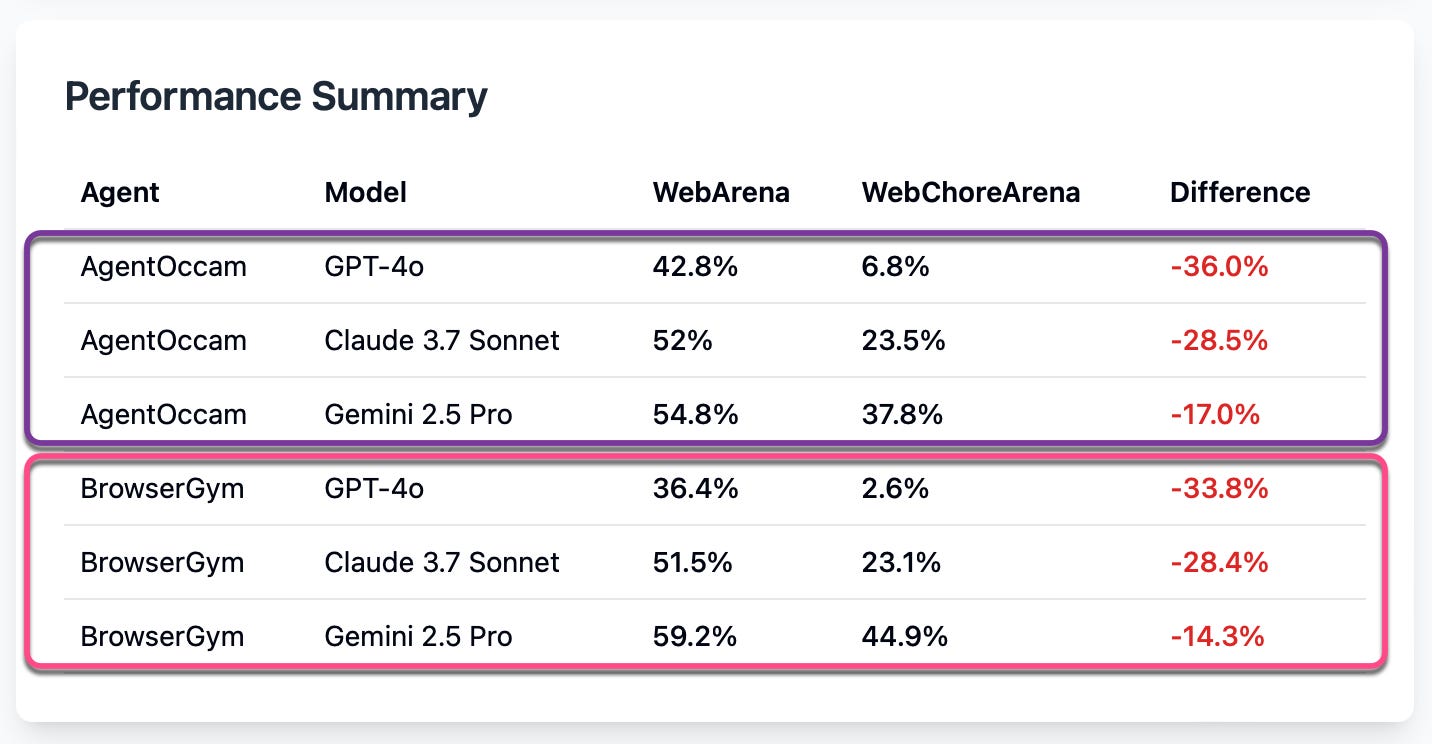
Unlike WebArena, which presents a narrower performance spectrum, WebChoreArena exposes a substantial performance divergence. Therefore, WebChoreArena provides model developers and evaluators with clear insights into the strengths and weaknesses of each model.
Detailed analysis of each AI Agent’s performance across diverse task typologies.
The results underscore the significant influence of AI Agent architecture, beyond the type of LLMs.

Finally
The WebChoreArena study reveals the remarkable yet limited capabilities of advanced LLMs like Gemini 2.5 Pro, achieving 40% accuracy on complex web tasks, underscoring the evolving role of autonomous AI Agents.
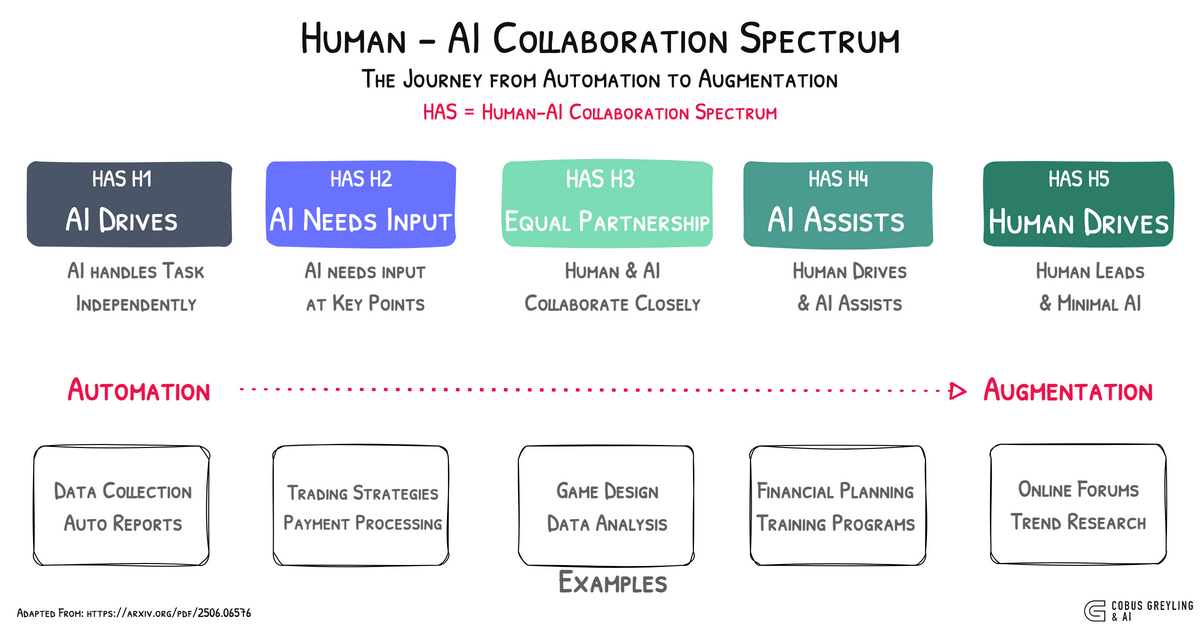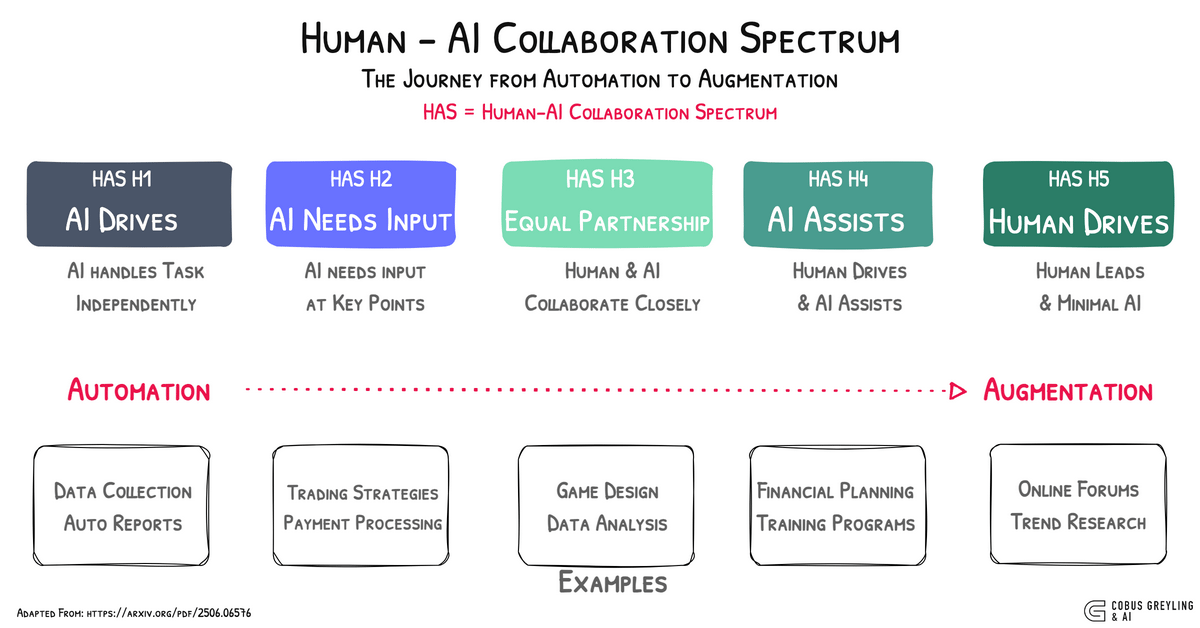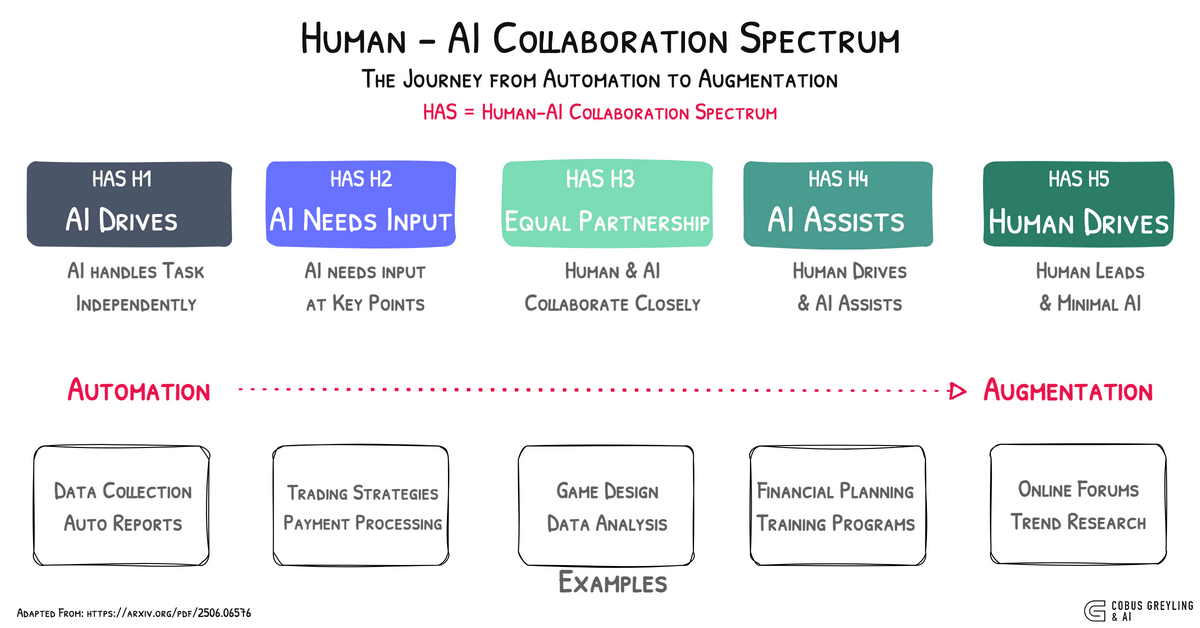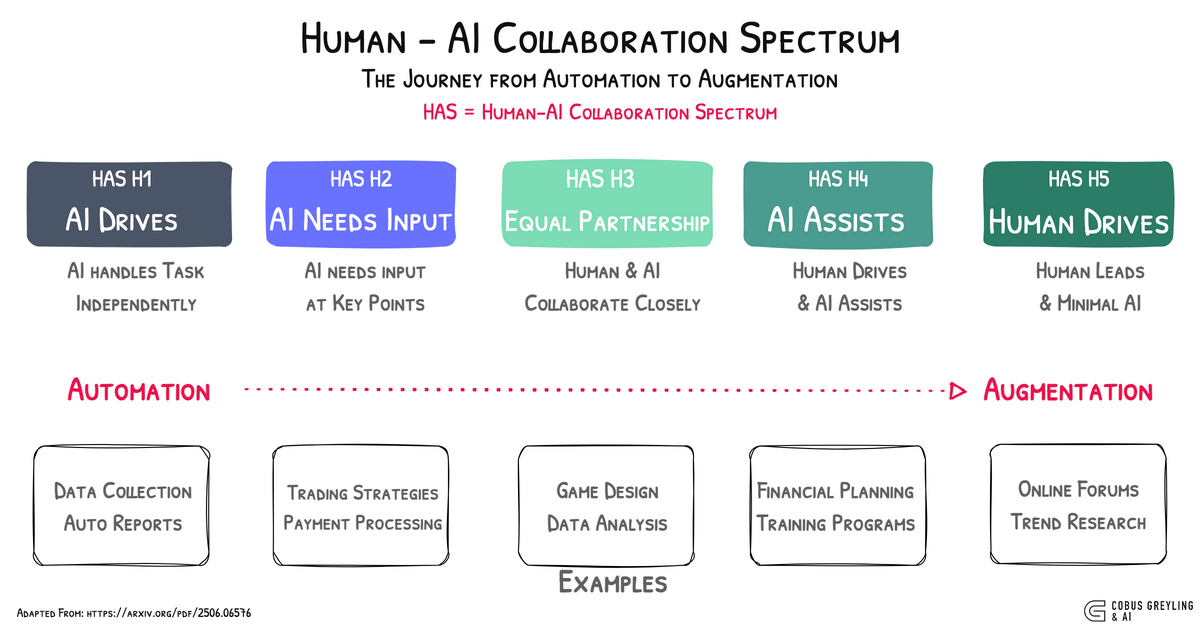
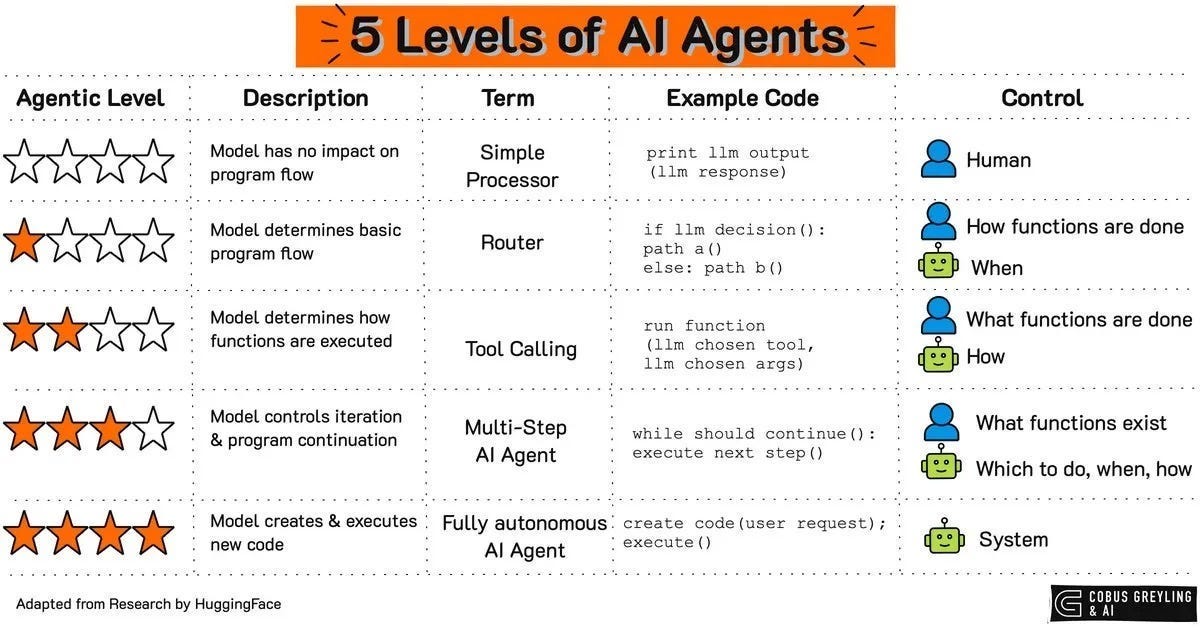
I love the concept of the agentic spectrum where AI Agents are operating on a continuum, from basic task execution to sophisticated decision-making, yet still requiring structured frameworks like AgentOccam and BrowserGym.
This spectrum highlights the agentic gap — the disparity between current AI Agent performance and the human-like autonomy needed for seamless task completion.
Even as AI Agents improve, they falter in tedious, memory-intensive tasks, as seen with GPT-4o’s mere 6.8% accuracy on WebChoreArena.
Human oversight remains critical, bridging this gap by guiding AI Agents through ambiguous or complex scenarios where their reasoning falls short.
The study’s findings align with my view that AI Agents must integrate human feedback to navigate the nuances of real-world tasks effectively.
As we advance along the AI Agentic continuum, closing the agentic gap will demand not just better models but also enhanced human-AI collaboration.
Ultimately, the journey toward truly autonomous AI Agents, hinges on balancing technological progress with human insight to tackle the challenges exemplified by WebChoreArena.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.