An Introduction To DSPy
Declarative Self-Improving Language Programs (DSPy) aims to separate the program flow from the prompts. While also optimising prompts based on key metrics


Introduction & General Observations
The last couple of days I have been trying to get my head around DSPy, especially in relation to LangChain and LlamaIndex.
Here are some initial observations, and any feedback or additional insights will be helpful….
Terminology
We have come to recognise the settle terminology introduced by frameworks like LlamaIndex and LangChain. DSPy is introducing a whole host of new terminologies like signatures, teleprompters which recently changed to be called Optimisers, modules and more.
Simplification
The principle of simplification has played a big role in the attractions of RAG, due to the fact that RAG is not opaque, and very transparent.
A framework like LangChain has done much work to introduce inspectability and observability at each step. Ensuring each step can be observed and inspected within the flow of the application.
With DSPy the attempt to introduce a programming interface and automating and hiding the prompting engineering portion, makes DSPy opaque to a large degree and does not contribute to simplification.
Prompt Engineering
One of the aims of DSPy is to abstract prompt engineering, hence separating programming and prompting. With the user describing to DSPy what to do, but not how to do it.
This is all achieved under the hood, and the user defines there needs via one or more signatures, DSPy chooses which prompt templates and prompt strategy/practice are best for the task at hand.
So signatures can be been seen as a shorthand to prompting, expressing your requirements and DSPy going off and performing it.
Simplification
Most frameworks are settling on the same general ideas, and many of these ideas are really simplified approaches where set features are abstracted.
The abstraction we have come to know are those of flow-building, prompt playgrounds, chunking etc. It makes sense to unify these different abstractions into a single data productivity suite.
DSPy does not contribute to this simplification and follows a more programatic approach.
Possible DSPy Use-Cases
Exploration & Optimisation
DSPy can be well suited as an interface to describe your needs, share a very small amount of data, and have DSPy generate the optimal prompts, prompt templates and prompting strategies.
To get better results without spending a fortune, you should try different approaches like breaking tasks into smaller parts, refining prompts, increasing data, fine-tuning, and opting for smaller models. The real magic happens when these methods work together, but tweaking one can impact the others.
GUI
DSPy is a programatic approach and I can just imagine how DSPy will benefit from a GUI for more basic implementations. Consider a user can upload sample data, describe in natural language what they want to achieve, and then have via the GUI a prompting strategy generated with templates etc.
Use-Case
Deciding if DSPy is the right fit for your implementation, the use-case needs to be considered. And this goes for all implementations, the use-case needs to lead.
In essence, DSPy is designed for scenarios where you require a lightweight, self-optimising programming model rather than relying on pre-defined prompts and integrations.
Introducing DSPy
The ML community is working on making language models (LLMs) better at understanding prompts and stacking or chaining them to solve complex tasks.
Manually crafting templates is the most common approach, but the DSPy team sees it as brittle and unscalable. As apposed to a process like DSPy which does not rely on fixed prompt templates and pipelines.
To improve this, DSPy introduced a new way to develop and optimise LM pipelines. It treats them as text transformation graphs, where LLMs are used through declarative modules.
As you will see later, these modules can learn from demonstrations how to apply various techniques like prompting, fine-tuning, and reasoning.
A compiler is designed to optimise DSPy pipelines to improve performance.
Two case studies show that DSPy can express and optimise complex LM pipelines for tasks like solving math word problems and answering complex questions.
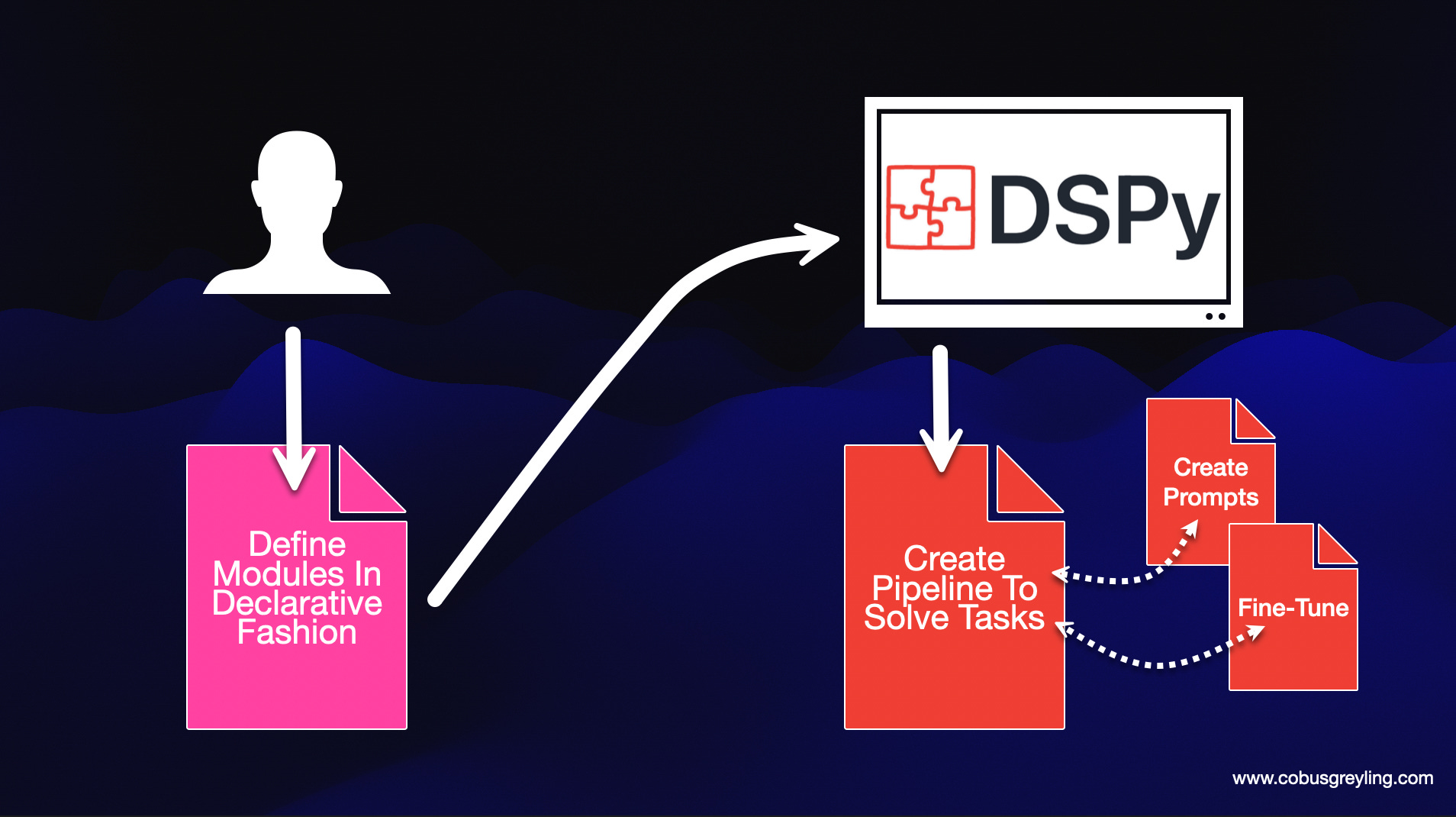
DSPy Workflow
Considering the image below, DSPy programs can perform various tasks, including question answering, information extraction and more. Whatever the task, the general workflow remains the same:

DSPy follows an iterative approach. Initially, you outline your task and the metrics you aim to optimise.
Then, you assemble a set of example inputs, usually without labels (or with labels only for the final outputs, if necessary for your metric).
Next, you construct your pipeline by choosing from the available built-in layers (modules), assigning each layer a specific input/output specification, and incorporating them into your Python code as needed.
Finally, you utilise a DSPy optimizer to transform your code into high-quality instructions, generate automatic few-shot examples, or update the weights of your language model (LM). This iterative process ensures efficient task execution and maximises the effectiveness of your DSPy implementation.
Signature
Every call from DSPy to the LLM requires a signature, the signature consists of three elements, as shown below. A minimal description of the sub-task. A description of one or more input fields and output fields.

Instead of free-form string prompts, DSPy programs use natural language signatures to assign work to the LM.
A DSPy signature is natural-language typed declaration of a function which can be described as a short declarative specification that tells DSPy what a text transformation needs to do. Rather than how a specific LM should be prompted to implement that behaviour.

More formally, a DSPy signature is a tuple of:
input fields and
output fields &
An optional instruction.
DSPy compiler will use in-context learning to interpret a question differently from an answer and will iteratively refine its usage of these fields.
The benefit signatures bring over prompts, is that they can be compiled into self-improving and pipeline-adaptive prompts or fine-tunes.
This is primarily done by bootstrapping useful demonstrating examples for each signature. Additionally, they handle structured formatting and parsing logic to reduce or avoid brittle string manipulation in user programs.
In practice, DSPy signatures can be expressed with a shorthand notation like question -> answer, so that line 1 in the following is a complete DSPy program for a basic question-answering system (with line 2 illustrating usage and line 3 the response when GPT-3.5 is the LM):
1 qa = dspy.Predict("question -> answer")
2 qa(question="Where is Guaran ́ı spoken?")
3 # Out: Prediction(answer='Guaran ́ı is spoken mainly in South America.')Teleprompters (Now known as Optimisers)
When compiling a DSPy program, it generally invokes a teleprompter, which is an optimiser that takes the (1) program, a (2) training set, and a (3) metric— and returns a new optimised program.
Different teleprompters apply different strategies for optimisation.
Compiler
A key source of DSPy’s expressive power is its ability to compile or automatically optimise any program in this programming model.
Compiling relies on a teleprompter, which is an optimiser for DSPy programs that improves the quality or cost of modules via prompting or fine-tuning, which are unified in DSPy.
While DSPy does not enforce this when creating new teleprompters, typical teleprompters go through three stages.
Candidate Generation
Parameter Optimisation
Higher-Order Program Optimisation
DSPy vs LangChain & LlamaIndex
LangChain and LlamaIndex specialise in high-level application development, offering ready-to-use application modules that seamlessly integrate with your data or configuration.
If you prefer using a standard prompt for tasks like question answering over PDFs or converting text to SQL, these libraries provide a comprehensive ecosystem to explore.
In contrast, DSPy takes a different approach…
It doesn’t come bundled with pre-defined prompts tailored for specific applications. Think of the notion of having a prompt-hub with a collection of searchable prompts.
Instead, DSPy introduces a compact yet potent set of versatile modules.
These modules can adapt and refine prompts (or fine-tune language models) within your pipeline, using your data.
Whether you’re modifying your dataset, adjusting program control flows, or switching to a different language model, DSPy’s compiler seamlessly generates optimised prompts or fine-tuning configurations tailored to your specific pipeline.
Depending on your project, there might be a chance that DSPy delivers superior results for your tasks with minimal effort, especially if you’re open to crafting or extending your own scripts.
In essence, DSPy is designed for scenarios where you require a lightweight, self-optimising programming model rather than relying on pre-defined prompts and integrations.
Minimal Working Example
This minimal working example, shows how a simple signature as shown below, is converted into a chain of thought prompt by DSPy…

In the DSPy documentation there is a minimal working example which I managed to run within a Colab notebook. This is a chain-of-thought example making use of the DSPy library.
The short tutorial makes use of the GSM8K dataset and the OpenAI GPT-3.5-turbo model to simulate prompting tasks within DSPy.
Start by importing the necessary modules and configuring the language model:
###################################################
import dspy
from dspy.datasets.gsm8k import GSM8K, gsm8k_metric
# Set up the LM
turbo = dspy.OpenAI(model='gpt-3.5-turbo-instruct', max_tokens=250)
dspy.settings.configure(lm=turbo)
# Load math questions from the GSM8K dataset
gsm8k = GSM8K()
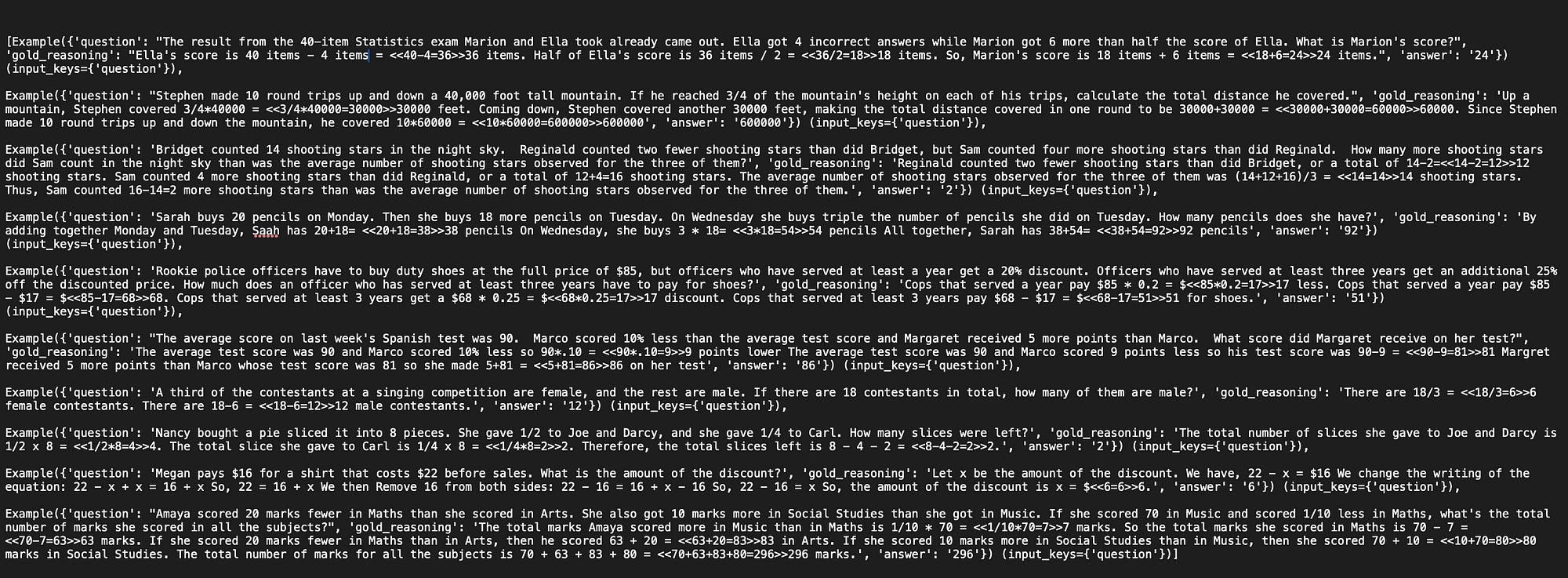
gsm8k_trainset, gsm8k_devset = gsm8k.train[:10], gsm8k.dev[:10]Then you can print the training set as seen below:
print(gsm8k_trainset)You can see the number of examples, the question for each and the answer.
Now define a custom program that utilises the ChainOfThought module to perform step-by-step reasoning to generate answers:
class CoT(dspy.Module):
def __init__(self):
super().__init__()
self.prog = dspy.ChainOfThought("question -> answer")
def forward(self, question):
return self.prog(question=question)Considering the code above, and the extract from the DSPy documents below, it is clear how the signature for Question Answering is inserted.

Now we move on to compiling it with the BootstrapFewShot teleprompter. In recent DSPy documentation, the term teleprompter has been replaced with the term Optimizer.
from dspy.teleprompt import BootstrapFewShot
# Set up the optimizer: we want to "bootstrap" (i.e., self-generate) 4-shot examples of our CoT program.
config = dict(max_bootstrapped_demos=4, max_labeled_demos=4)
# Optimize! Use the `gsm8k_metric` here. In general, the metric is going to tell the optimizer how well it's doing.
teleprompter = BootstrapFewShot(metric=gsm8k_metric, **config)
optimized_cot = teleprompter.compile(CoT(), trainset=gsm8k_trainset)After compiling the DSPy program, move to evaluating its performance on the dev dataset.
from dspy.evaluate import Evaluate
# Set up the evaluator, which can be used multiple times.
evaluate = Evaluate(devset=gsm8k_devset, metric=gsm8k_metric, num_threads=4, display_progress=True, display_table=0)
# Evaluate our `optimized_cot` program.
evaluate(optimized_cot)For a deeper understanding of the model’s interactions, review the most recent generations through inspecting the model’s history:
turbo.inspect_history(n=1)Below the output, notice the instruction and the template.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.