Automatic Prompt Engineering
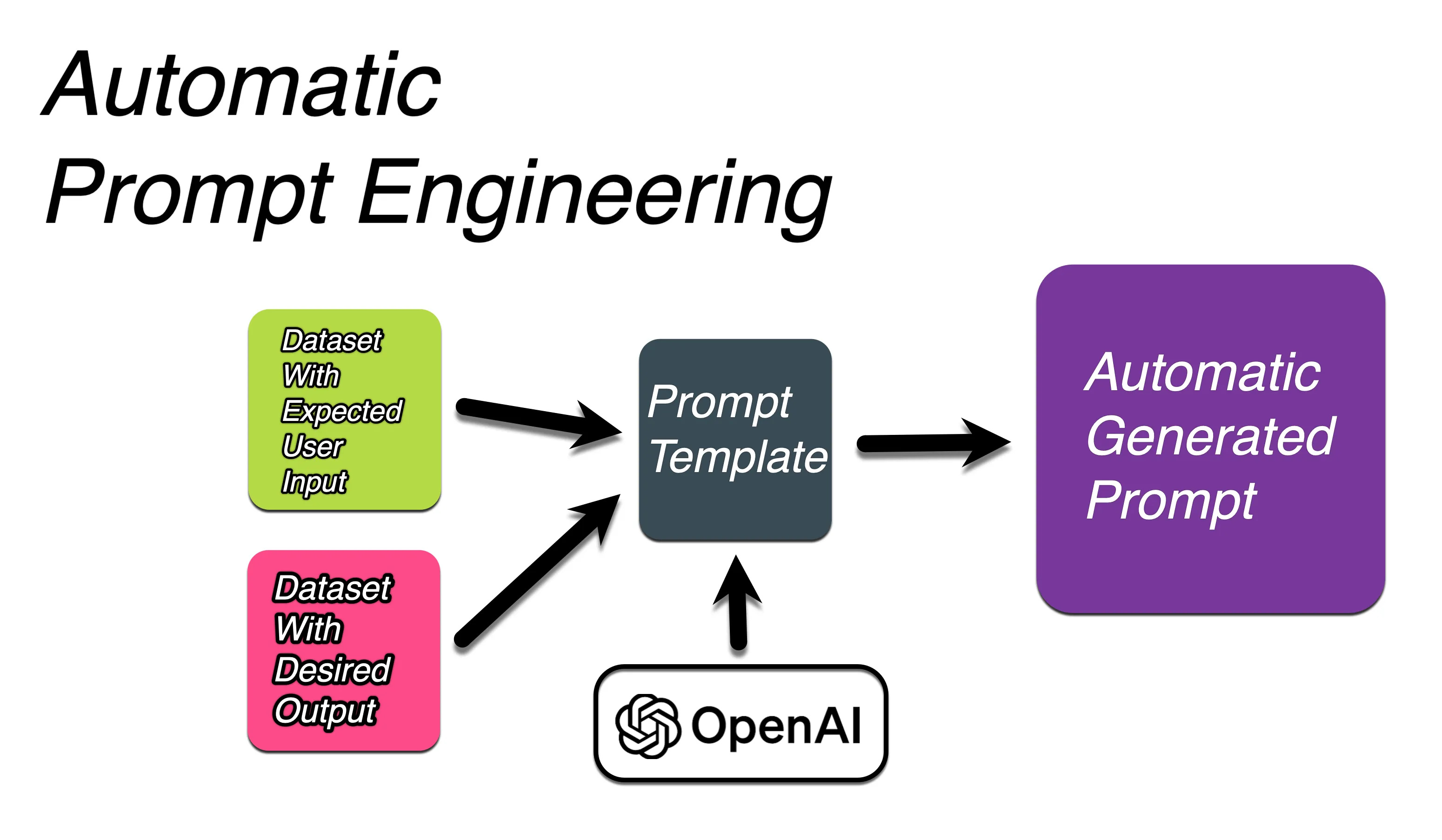
Automatic Prompt Engineering (APE) generates optimised prompts for text generation, based on three inputs; the expected input data, the desired output & a prompt template.

I’m currently the Chief Evangelist @ HumanFirst. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.
This study from March 2023 takes a simple yet novel approach to prompt engineering by automatically generating prompts based on the desired input and output.
In a recent article I considered the future of prompt engineering, and the possibility of soft prompts (prompt tuning). I argued that user context, ambiguity and user intent all play an important role in any conversational UI.
User intent, context, ambiguity and disambiguationare all part and parcel of any conversation.
The question is, can this approach accelerate the process where manually wording prompts fade into the background and interaction with the LLM is based on contextual example input and output datasets?
What I like about this approach, is that context, and user intent can be mapped, while also taking into consideration possible ambiguity.
Yet manually crafting prompts is tedious in the sense of trying to word a prompt in such a way to engender a desired response from the LLM. Focussing on prompt engineering also does not take into consideration an array of possible user inputs.
Data Management will always be part of LLM applications.
APE offers an alternative approach to prompt engineering, where via input and matching output examples, prompts can be generated on the fly.
We define “prompt engineering” as optimising the language in a prompt in order to elicit the best possible performance. Notably, this does not include prompts that chain multiple LLM queries together or give the LLM access to external tools. ~ Source
The basic notebook below shows how Automatic Prompt Engineering (APE) can be used to generate prompts based on a small input data set, a list of expected outputs and a prompt template.
APE performs this in two steps:
A LLM is used to generate a set of candidate prompts.
A prompt evaluation function considers the quality of each candidate prompt; returning the prompt with the highest evaluation score. A practical implementation is, via a human-in-the-loop approach, prompts can be marked up and marked down for use on terms of accuracy and correctness.
Below is a complete notebook example to run APE, all you will need to run this, is your own OpenAI API key. The input dataset is defined as words, and the output dataset is defined as antonyms. The template is defined as eval_template.
#@title Install Dependencies
! pip install git+https://github.com/keirp/automatic_prompt_engineer
pip install openai
import openai
openai.api_key = 'xxxxxxxxxxxxxxxxxxx'
# First, let's define a simple dataset consisting of words and their antonyms.
words = ["sane", "direct", "informally", "unpopular", "subtractive", "nonresidential",
"inexact", "uptown", "incomparable", "powerful", "gaseous", "evenly", "formality",
"deliberately", "off"]
antonyms = ["insane", "indirect", "formally", "popular", "additive", "residential",
"exact", "downtown", "comparable", "powerless", "solid", "unevenly", "informality",
"accidentally", "on"]
# Now, we need to define the format of the prompt that we are using.
eval_template = \
"""Instruction: [PROMPT]
Input: [INPUT]
Output: [OUTPUT]"""
# Now, let's use APE to find prompts that generate antonyms for each word.
from automatic_prompt_engineer import ape
result, demo_fn = ape.simple_ape(
dataset=(words, antonyms),
eval_template=eval_template,
)
# Let's see the results.
print(result)And below is the list of possible prompts listed according to a score.
score: prompt
----------------
-0.24: give the opposite of the word provided.
-0.25: produce an antonym for each word provided.
-0.27: produce an antonym (opposite) for each word given.
-0.28: "change all adjectives to their antonyms."
-0.29: produce an antonym for each word given.
-0.31: produce an input-output pair in which the output is the opposite of the input.
-0.33: use an online thesaurus to find a word with the opposite meaning.
-0.51: produce the opposite of the input.
-0.63: make a list of antonyms.
-0.85: "find the opposite of each word."The code below can be used to score a human or manually entered prompt.
from automatic_prompt_engineer import ape
manual_prompt = "Write an antonym to the following word."
human_result = ape.simple_eval(
dataset=(words, antonyms),
eval_template=eval_template,
prompts=[manual_prompt],
)
print(human_result)And the score of the human entered prompt.
log(p): prompt
----------------
-0.24: Write an antonym to the following word.In Conclusion
APE is an approach where the LLM is given the desired input and output, and the prompt is generated from these examples.
This approach reduces the human effort involved in creating and validating prompts. This algorithm uses LLMs to generate and select prompts automatically.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ HumanFirst. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.


