

Can LLMs Outperform Humans At Prompt Engineering?
A recent study found that LLMs are better at prompt engineering than what humans are…

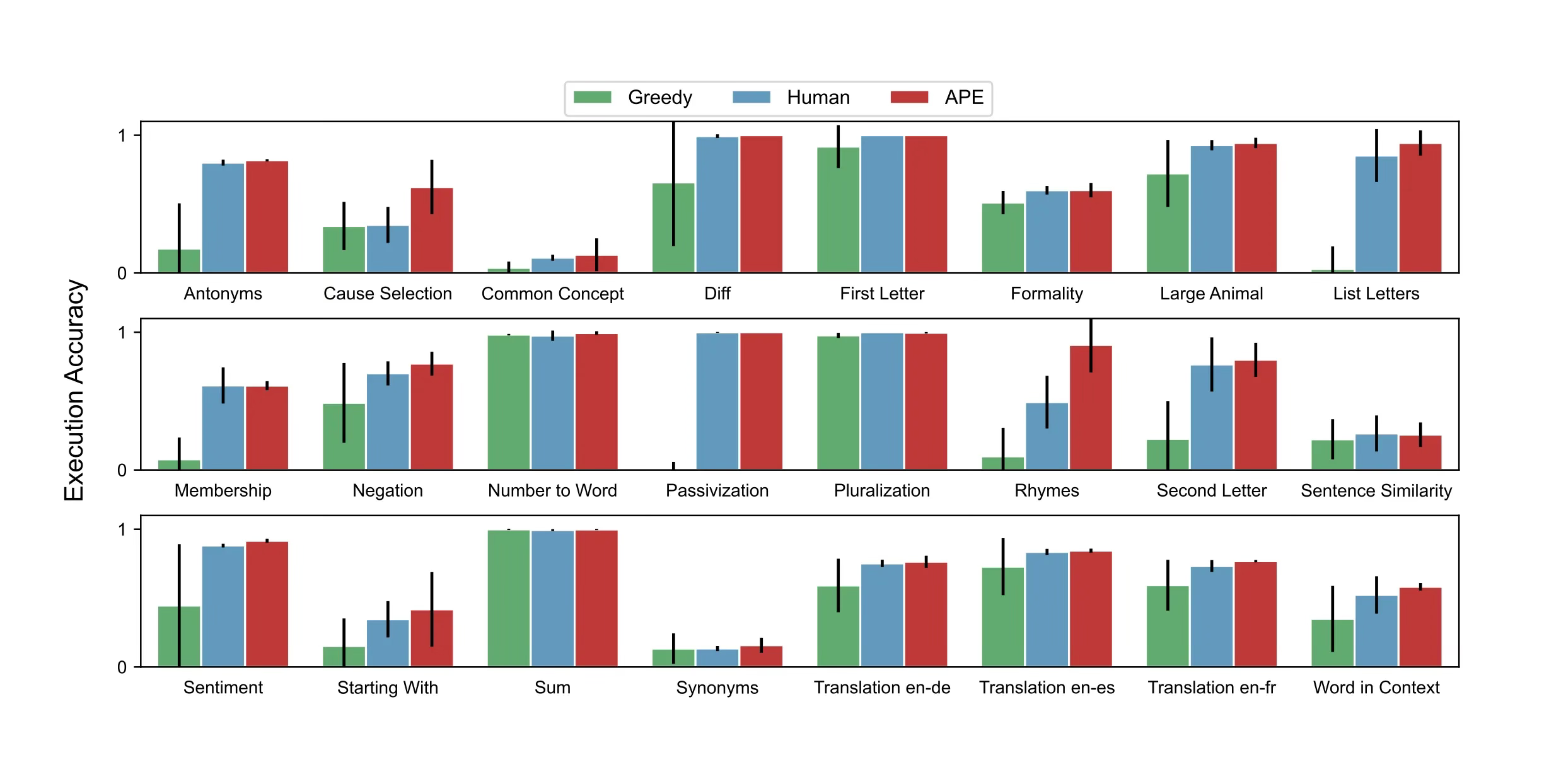
In the image above, zero-shot test accuracy is shown over 24 instruction tasks, and in these tasks, Automatic Prompt Engineering (APE) equaled or surpassed human-level prompts!
The APE process has three inputs:
A basic prompt template.
A dataset of input sentences.
A matching dataset of outputs expected.
The APE process takes the input and the expected output and creates prompts to perform those tasks. Hence the LLM writes the prompts which will produced the given and defined output dataset.
The question is, does APE pave the way, or at least serve as an indicator of future LLM UIs and demise of humans writing prompts?
Imagine a future where prompts are not engineered, but the LLM is supplied with a set of inputs and outputs; each consisting of 10 examples. And the LLM generates instructions (prompt engineering) from comparing the input and output examples; and deducing what needs be achieved.
With Sam Altman stating that the idea of prompt engineering as we currently know it, will not be around in a few years time…and also considering OpenAI’s new approach to fine-tuning where the input and output datasets are defined with a minimum of 10 lines of input and output examples.
At the end of the day human authored prompts are just explicit expressions of intent and there can be implicit intent that can be inferred from other parts of the context.
Another advantage of the LLM generating the prompts, is that human users do not need to experiment with a wide range of prompts to elicit desired behaviours. Whilst not being fully aware of how compatible the instructions are with the referenced model.
The study defined “prompt engineering” as the process of optimising the wording in a prompt to elicit the desired and best response.
It was noted that this does not include prompt chaining or Autonomous Agents making use of external tools.
Considering the image below, the workflow for APE is shown on the left, and on the right is the performance of each model making use of APE, and how close it comes to Human Prompt Engineering.
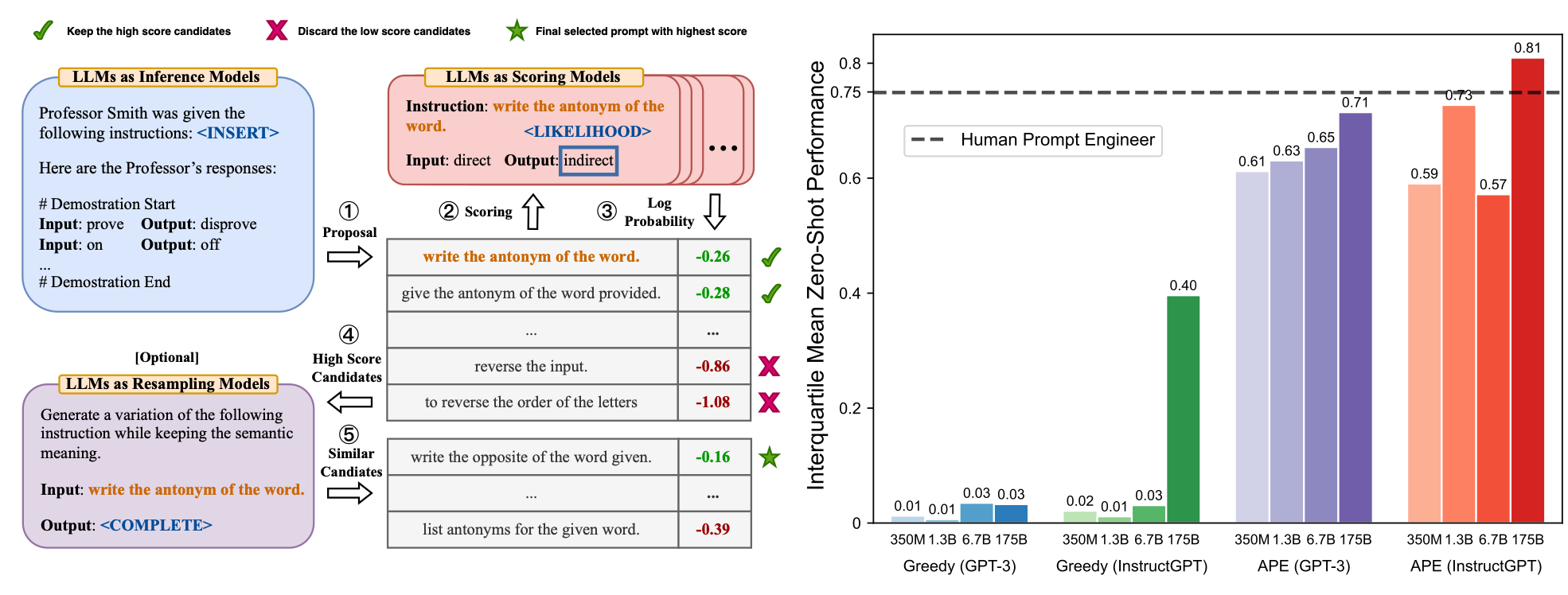
There is also a case to be made for using APE with a human-in-the-loop approach, where generated prompts are inspected and improved where necessary.
This approach can also be used to optimise prompts for specific LLMs, where a LLM is given the desired input and output and a model specific prompt can be generated.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️