Chain-Of-Note (CoN) Retrieval For LLMs
Chain-of-Note (CoN) is aimed at improving RAG implementations by solving for noisy data, irrelevant documents and out of domain scenarios.

The Gist Of CoN
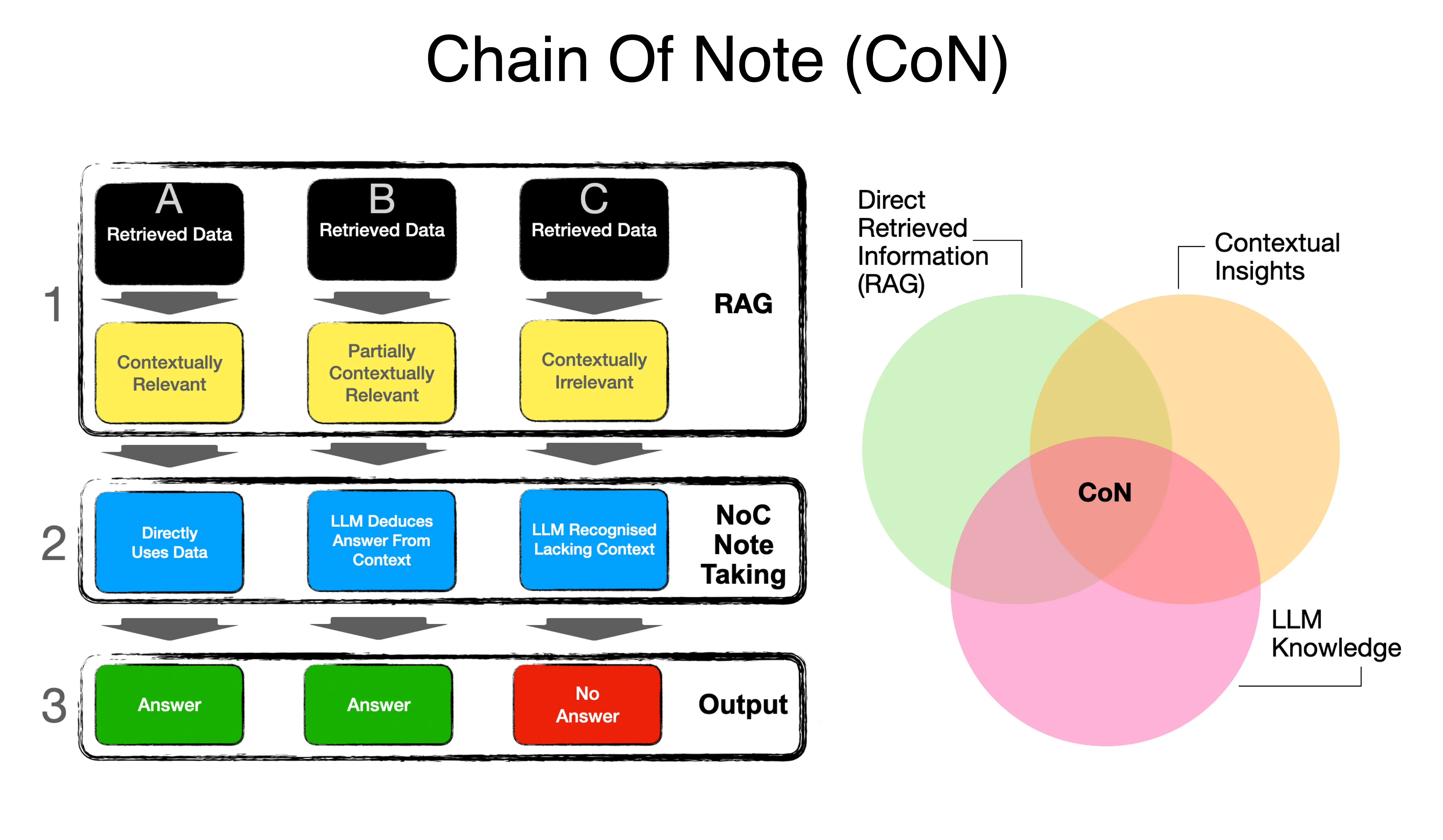
The CoN framework is made up of three different types, what the study calls, reading notes.
Considering the mage above, type (A) shows where the retrieved data or document answers the query. So the LLM merely uses NLG to format the answer from the data supplied.
Type (B) is where the retrieved document does not directly answer the query, but the contextual insights are enough of an enabler for the LLM to combine the retrieved document with its own knowledge to deduce an answer.
Type (C) is where the retrieved document is irrelevant and the LLM does not have the relevant knowledge to respond which results in the framework not giving a false or wrong answer.
CoN is an adaptive process, or logic and reasoning layer, where direct information is balanced with contextual inference and LLM-knowledge recognition.
The Four Sides Of Data
To equip the model with the ability to generate NoC reading notes, fine-tuning is required.
We trained a LLaMa-2 7B model to incorporate the note-taking ability integral to CON.
CoN is not only a prompt template, but also incorporates a model fine-tuned for note-taking. Hence CoN can be seen as a combination of RAG and Fine-Tuning.
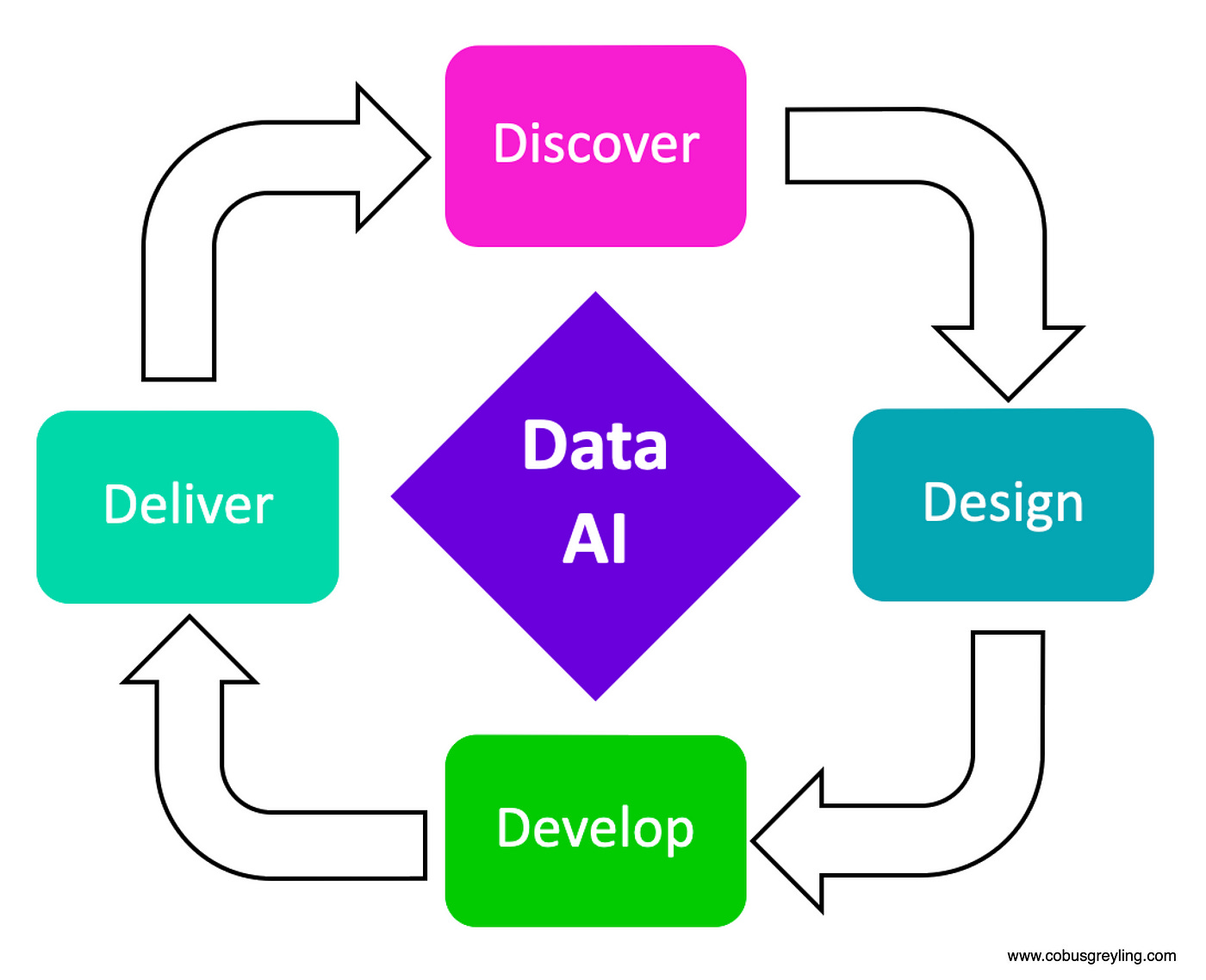
This comes back to the notion of Data AI and the four sides of data, being Data Discovery, Data Design, Data Development and Data Delivery.
RAG in general, and CoN in specific can be seen as part of the Data Delivery process. But in order to train the NoC model, a process of data discovery is required, data design and data development.
For this study, it was essential to gather appropriate training data.
Manual annotation for each reading note is resource-intensive, so the research team employ a state-of- the-art language model to generate notes.
I hasten to mention here, that should NoC be implemented in an enterprise setting, an AI accelerated data productivity studio would be crucial. This process of human-in-the-loop is important for relevant training data with a clear signal.
CoN Template
Below a CoN template is shown from the LangSmith playground. In this example, given a question, Wikipedia is queried and uses OpenAI with the Chain-of-Note prompt to extract an answer.
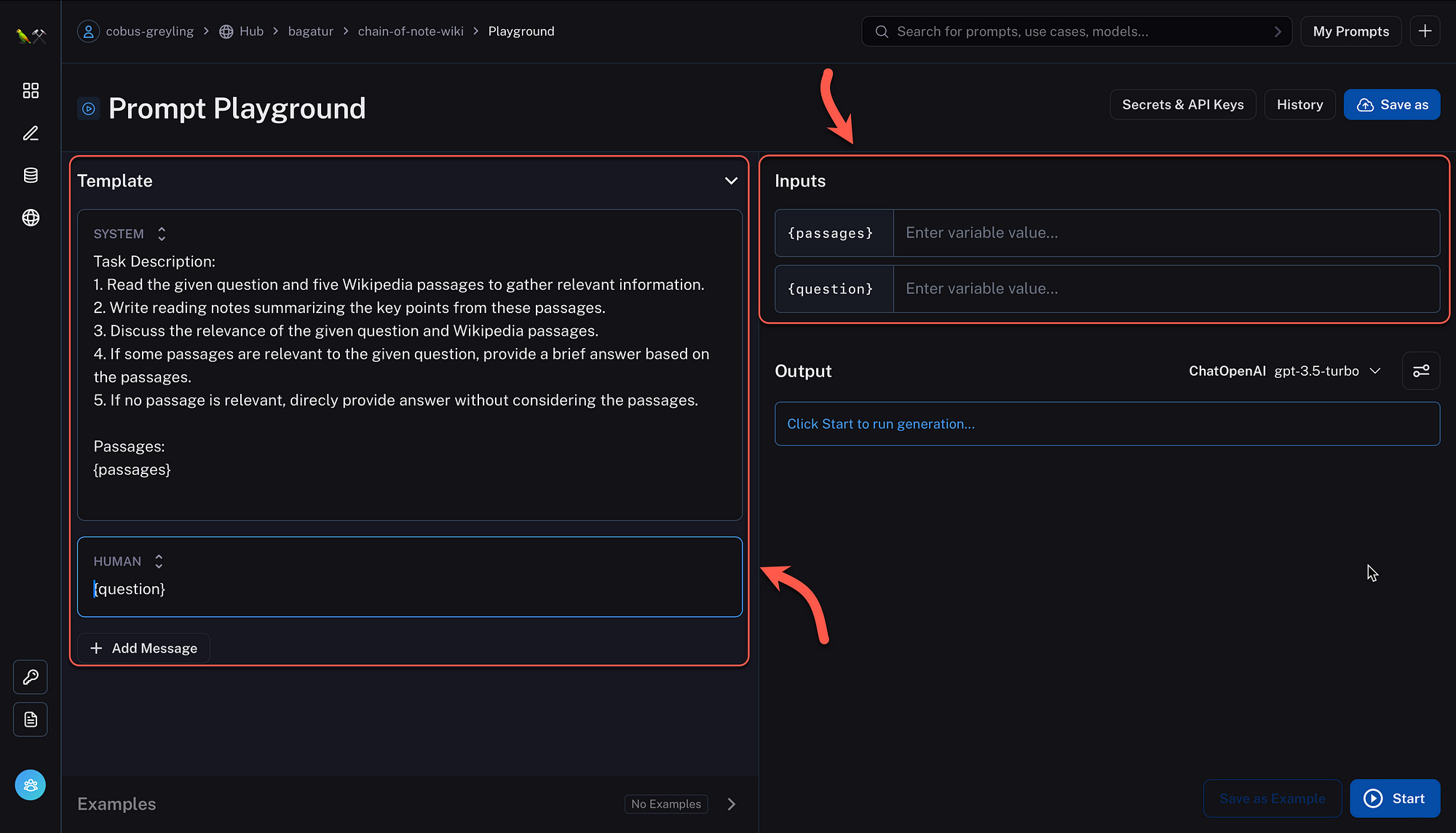
For standard RAG, the instruction is:
Task Description: The primary objective is to briefly answer a specific
question.For RALM with CON, the instruction is:
Task Description:
1. Read the given question and five Wikipedia passages to gather relevant
information.
2. Write reading notes summarizing the key points from these passages.
3. Discuss the relevance of the given question and Wikipedia passages.
4. If some passages are relevant to the given question, provide a brief
answer based on the passages.
5. If no passage is relevant, direcly
provide answer without considering the passages.RAG
Retrieval-Augmented Generation has served as a significant enabler for LLMs. Most notably, model hallucination has been curbed considerably with the introduction of RAG and RAG has also served as an equaliser in model performance. Read more about this, here.
The challenge with RAG is to ensure that accurate, highly succinct and contextually & relevant data is presented to the LLM at inference tine.
The retrieval of irrelevant data can lead to misguided responses, and potentially causing the model to overlook its inherent knowledge, even when it possesses adequate information to address the query.
Hence the aim of Chain-of-Note (CoN) as a new approach, is aimed to improve RAG resilience. Especially in instances where the RAG data does not contain a clear signal pertaining to the query context.
The image below from the study illustrates in more detail the implementation of NoC. The framework primarily constructs three types of reading notes…

The CoN framework generates sequential reading notes for the retrieved documents, which enables a systematic evaluation of the relevance and accuracy of information retrieved from external documents.
By creating sequential reading notes, the model not only assesses the pertinence of each document to the query but also identifies the most critical and reliable pieces of information within these documents.
This process helps in filtering out irrelevant or less trustworthy content, leading to more accurate and contextually relevant responses.
Finally
Balance
The answer to resilient enterprise grade LLM-based Generative AI implementations is not RAG or model fine-tuning. But rather a combination of both, of which NoC is a good example.
Context
Secondly, a contextual reference is very important and the clearer the signal is within the data extract to reference, the better. The fine-tuned model provides additional context, coupled with the retrieved documents and the NoC prompt template.
Data
Going forward, data will become increasingly important together with efficient and effective methods of data discovery and design. I would love to have more insight into the structure of the training data.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.