Comparing Human, LLM & LLM-RAG Responses
A recent study, focusing on the healthcare & preoperative medicine compared expert human feedback with LLM generation and RAG enhanced responses.


Introduction
Usually I do not read research on very narrow fields, however this paper offers a very insightful research in comparing question answering. And comparing human feedback, to LLM-only responses, and LLM-RAG responses.
During the study, an LLM-RAG model was developed using 35 preoperative guidelines and tested it against human-generated responses.
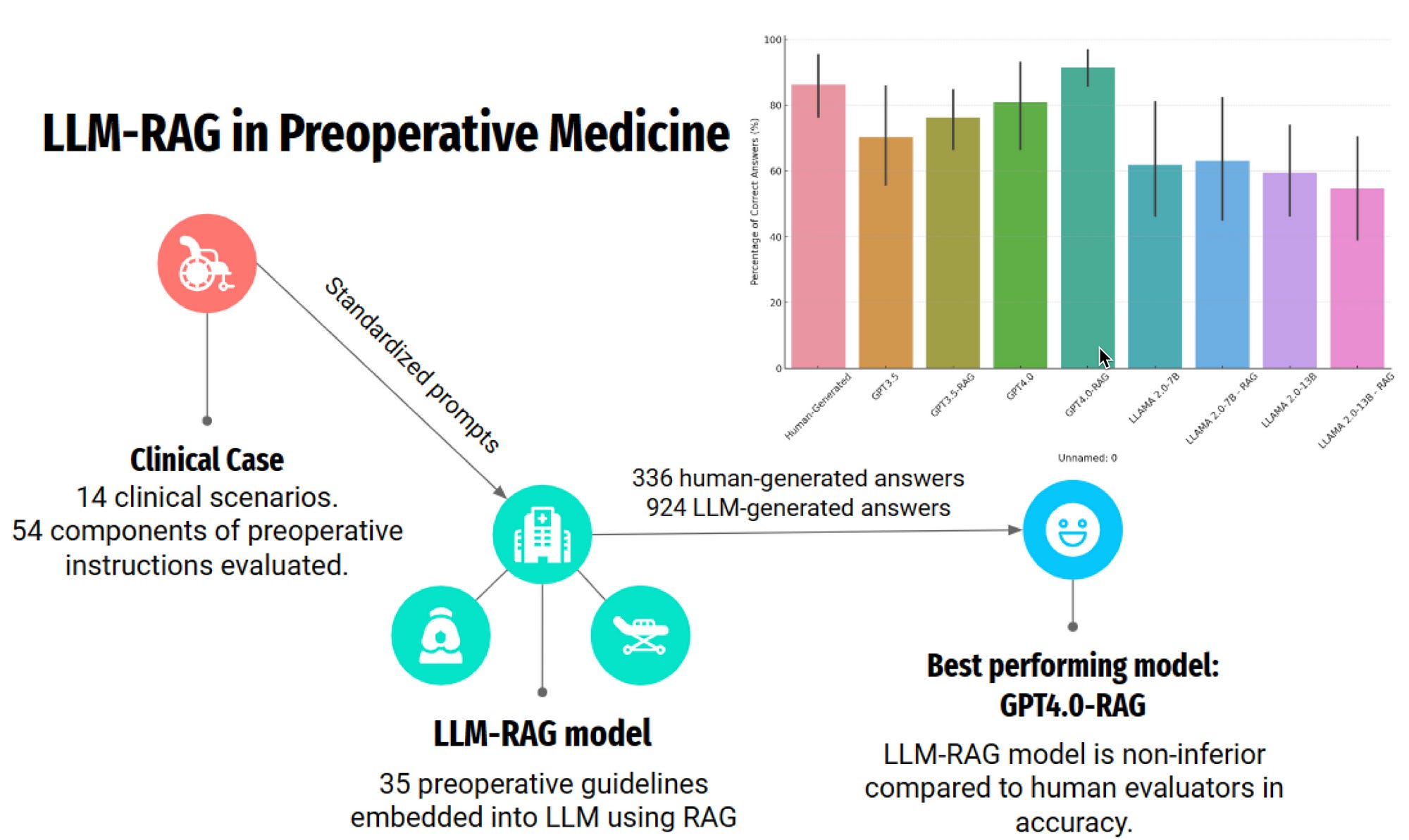
After evaluating a total number of 1260 responses, comprising of 336 human-generated, 336 LLM-generated, and 588 LLM-RAG-generated responses.
For the RAG pipeline clinical documents were converted into text using Python-based frameworks like LangChain and LlamaIndex, and processing these texts into chunks for embedding and retrieval.
Evaluated LLMs including GPT3.5, GPT4.0, Llama2–7B, llama2–13B, together with a RAG implementation.
The correctness of responses were determined based on established guidelines and expert panel reviews. The human-generated answers were provided by junior doctors for comparison.
Inference Time & Accuracy
The LLM-RAG pipeline model responded in an average time of 15–20 seconds, significantly quicker than the 10 minutes typically needed by humans.
Among the basic LLMs, GPT4.0 achieved the highest accuracy of 80.1%.
With RAG enhancement, GPT4.0’s accuracy improved to 91.4%.
The human-generated instructions, had an accuracy of 86.3%.
The pipeline underscores the benefits of grounded knowledge, upgradability, and scalability as crucial elements in deploying LLMs for healthcare purposes.
Results
Below is a basic diagram of the RAG pipeline, with the performance graphed in the top right.
And considering the graph, I was astonished just how high the GPT4.0 model scored without RAG support. Also, note that GPT3.5 sans RAG, outscores other models with RAG.
Operational Framework
The diagram below shows the operational framework from the study.
The LLM-RAG model with GPT4.0 shows great potential in creating precise and safe preoperative instructions, matching junior doctors’ performance.
This study highlights how LLMs can enhance preoperative medicine, emphasising that its use should complement human expertise, requiring continuous oversight and cautious implementation.

In Closing
It would be interesting to see this study which focusses on a very narrow and specialised domain, compared to a more general question answering domain.
The study shows clearly that human and GPT 4.0 + RAG is on par, with the only difference being response times. With humans taking much longer to respond to questions, and still not exceeding LLM/RAG performance.
This makes a good case for AI assisting humans; where physicians can make use of the RAG pipeline to get quick and accurate responses, which then in turn can be reviewed.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.