Considering Large Language Model Reasoning Step Length
When using Chain of Thought, what is the optimal number of steps to use?

Introduction
A recent study focused on understanding the impact of reasoning step length in Chain of Thought (CoT) implementations.
The research finds that lengthening reasoning steps, even without adding new information, significantly improves LLMs’ reasoning across various datasets.
The study also reveals that maintaining the necessary length of inference, rather than the correctness of rationales, contributes to favourable outcomes.
It was identified that the benefits of increasing reasoning steps are task-dependent, with simpler tasks requiring fewer steps and complex tasks benefiting significantly from longer inference sequences.
Considerations
This study also introduces an interesting and useful prompting technique.
Decomposing LLM input into a chain of thought needs to be automated in order to scale. Hence an automated process demands a level of complexity and logic which needs to be introduced.
Also, this process adds overhead to inference time and also token cost.
There as also a threshold in terms of the number of steps created and the improvement in accuracy.
Chain Of Thought
Since the introduction of Chain Of Thought prompting, it has proved as one of the key innovations regarding Large Language Models (LLMs). This is illustrated with the rise of something some refer to as the Chain of Xphenomenon.
Hence the effectiveness of Chain Of X raised an opportunity to delve deeper into the CoT’s underlying principles.
A recent study considers the underlying principles and anatomy of Chain of Thought Prompting.
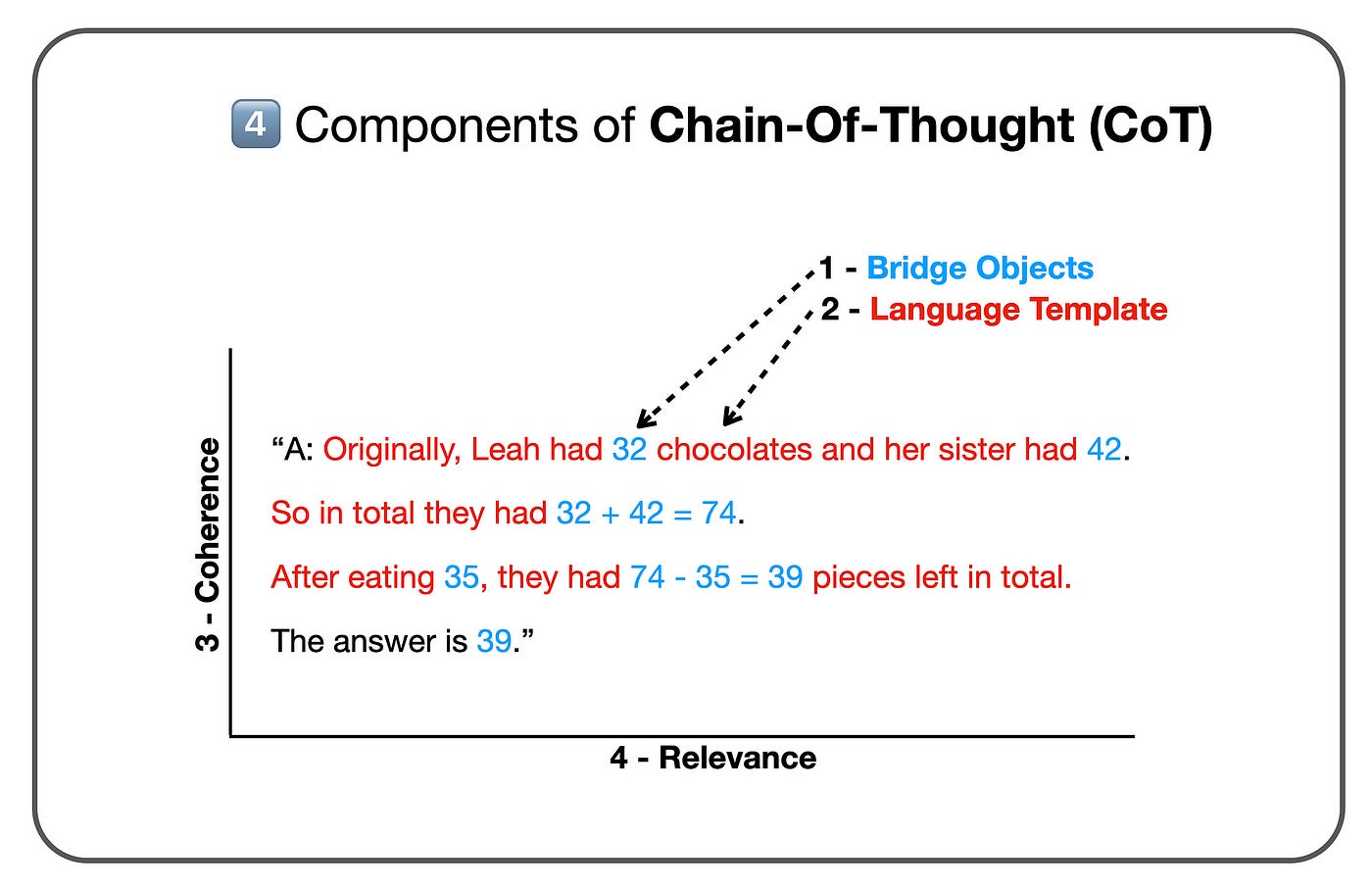
Key Findings To Improve CoT Performance
In few-shot Chain of Thought (COT), there is a direct and quantifiablelinear correlation between step count and accuracy, offering a measurable means to optimise CoT prompting for complex reasoning.
Lengthening reasoning steps in prompts significantly enhances LLMs’ reasoning abilities across diverse datasets, while shortening steps, even while preserving key information, diminishes model reasoning.
Even incorrect rationales can yield favourable outcomes if they maintain the required length of inference, as seen in tasks like mathematical problems, where errors in intermediate numbers have minimal impact due to their process-oriented nature.
The benefits of increasing reasoning steps are linked to the task: simpler tasks require fewer steps, whereas more complex tasks substantially benefit from longer inference sequences.
In zero-shot Chain of Thought, augmenting reasoning steps significantly improves LLM accuracy.
A prompt modification from “Let’s think step by step” to “Let’s think step by step, you must think more steps” noticeably enhances LLM reasoning abilities, particularly in datasets involving mathematical problems.
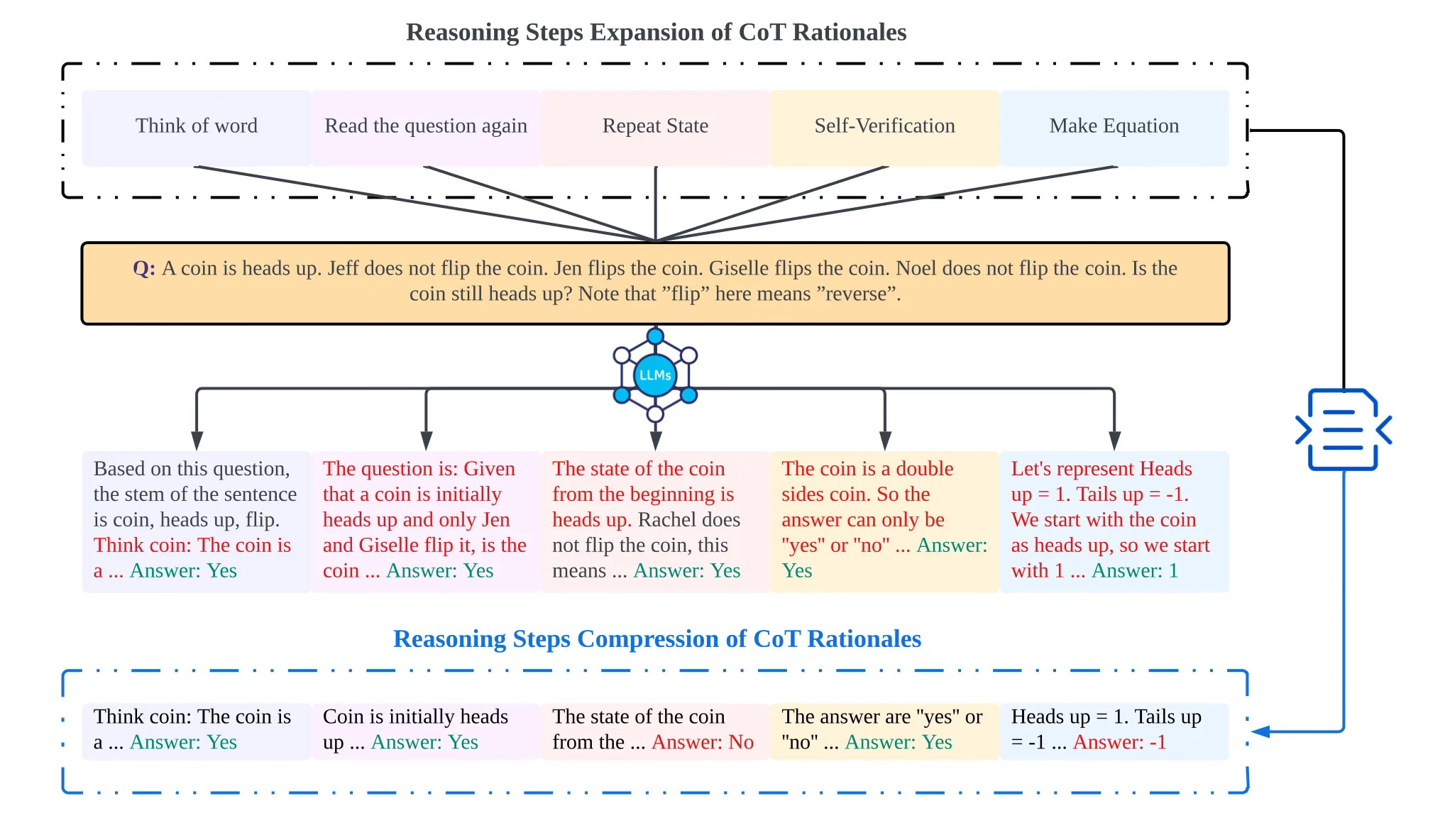
Considering the image above, the increase in length of the reasoning step chain, the accuracy of problem-solving increases too.
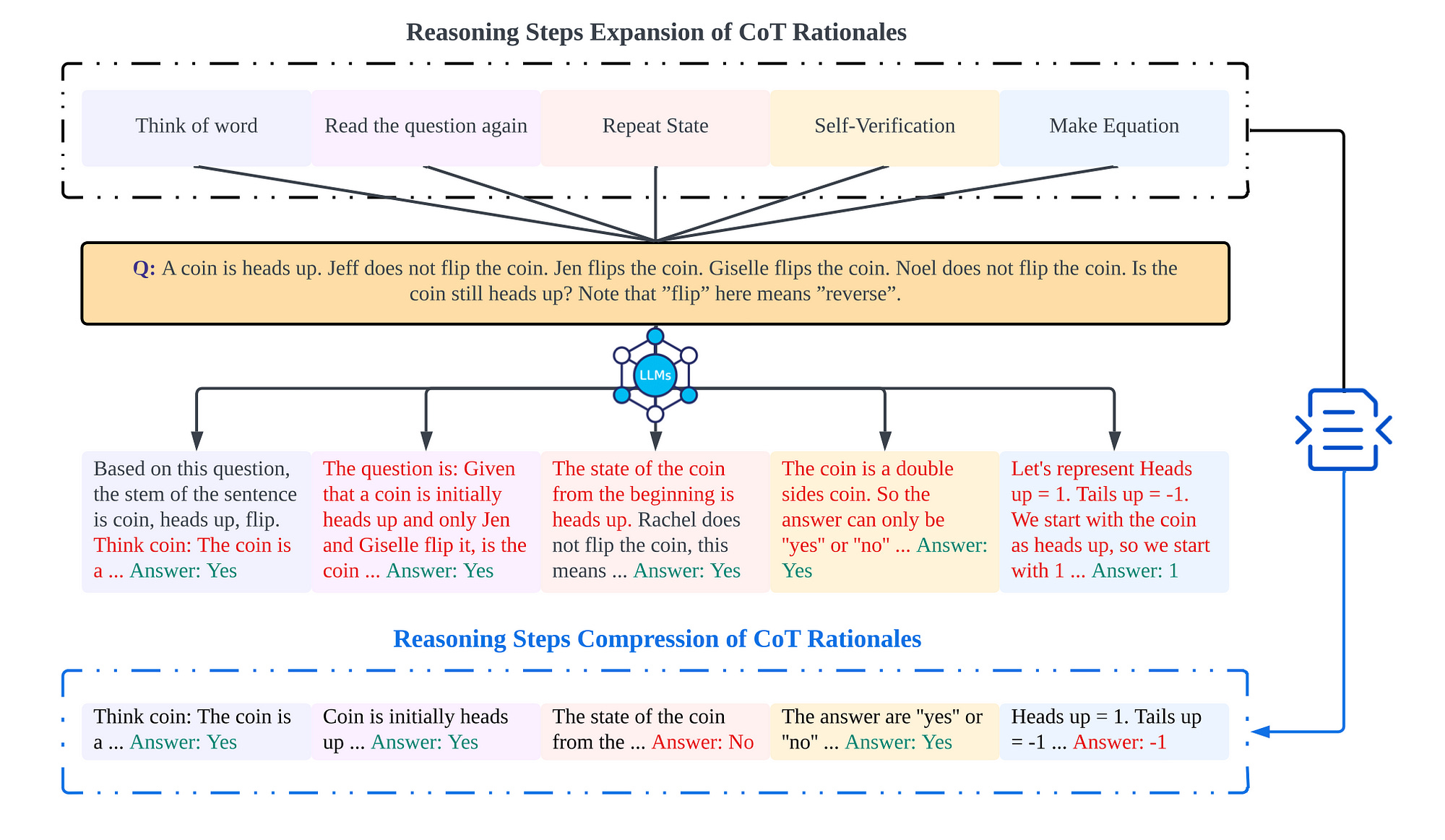
Considering the image above, the increase in length of the thinking chain through the method in the figure, and compress the thinking chain without losing information as much as possible.
Below the five general prompt strategies from the study…

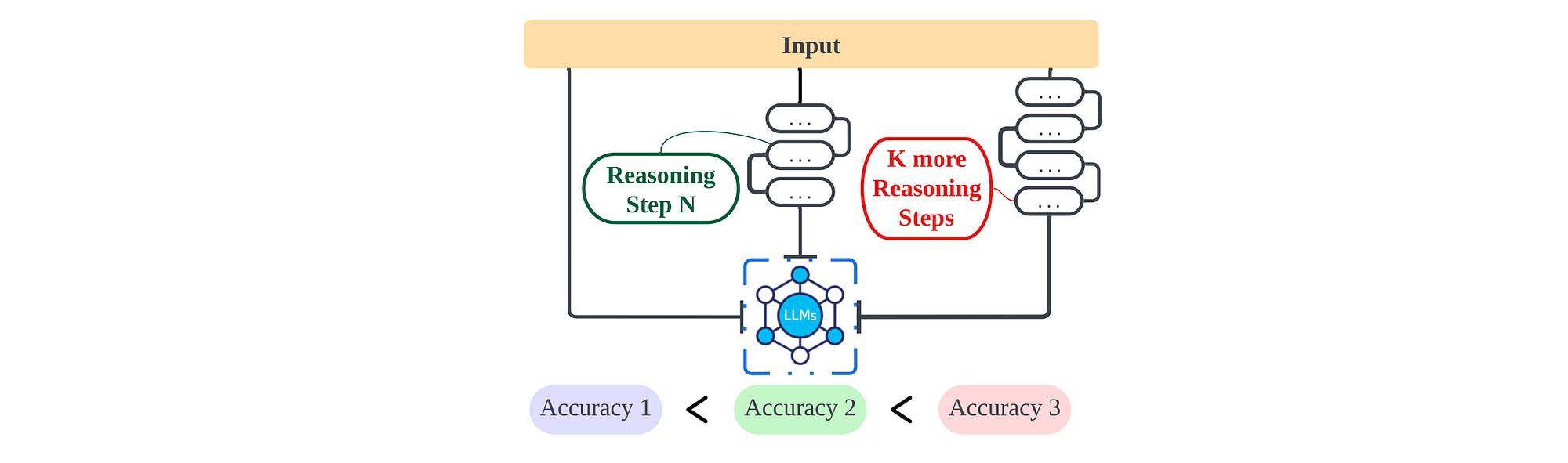
Again considering the image below, the accuracy with different size models on dataset GSM8K shown. It is interesting how there is an optimal number or steps in terms of accuracy.
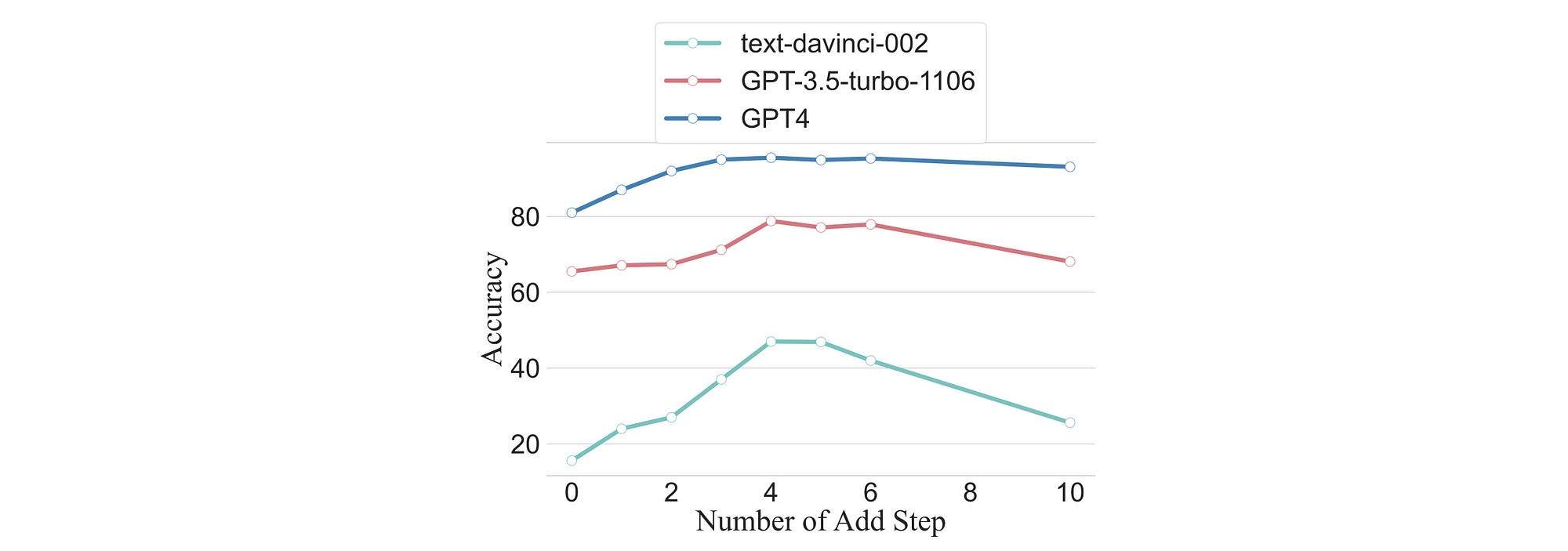
Finally
Manual-CoT prompting relies on a few manually designed demonstrations, each composed of a question and a reasoning chain leading to an answer, to improve language models’ reasoning performance.
Auto-CoT eliminates the need for manual demonstration design by automatically constructing demonstrations through clustering test questions to select diverse examples and generating reasoning chains using the language model’s own zero-shot reasoning capability.
This work significantly contributes to understanding and optimising Chain of Thought (CoT) in Large Language Models (LLMs), especially concerning complex reasoning tasks.
The research, conducted on LLMs like GPT-3, GPT-3.5, and GPT-4, reveals a noteworthy correlation between the length of the reasoning chain and model performance.
Surprisingly, longer reasoning chains enhance performance, even with misleading information, emphasising the importance of chain length over factual accuracy for effective problem-solving in complex Natural Language Processing (NLP) tasks.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.