Context-Aware Meta-Learning For Foundation Models
Large Language Models (LLMs) have the capability to learn at inference via a one-shot or few-shot approach without any fine-tuning. This study focusses on how this ability unique to language and text

Personally, I’m much more interested in the text and audio side of Foundation Models, with Conversational AI allowing humans to have conversations with machines.
However, imagery is growing in importance and will play an important role in conversation in general.
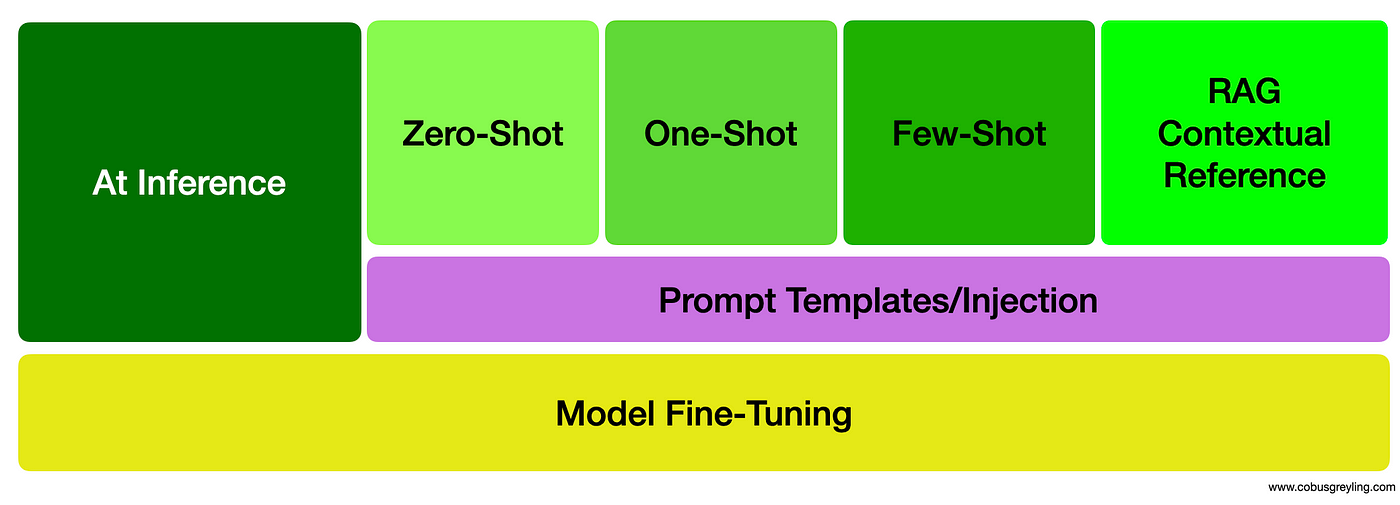
Text based Conversational AI offers two basic levels of learning:
Base Model Fine-Tuning
At inference.
The discipline of images and visual concepts have been lagging behind text in the ability to learn new visual concepts at inference time, without any fine-tuning or meta-tuning.
The study identified that if visual implementations could emulate LLMs and the power of real-time implementations can be unlocked for images, a new category of applications will be possible.
So imagine of a system could detect new visual classes during inference via a few-shot learning approach…
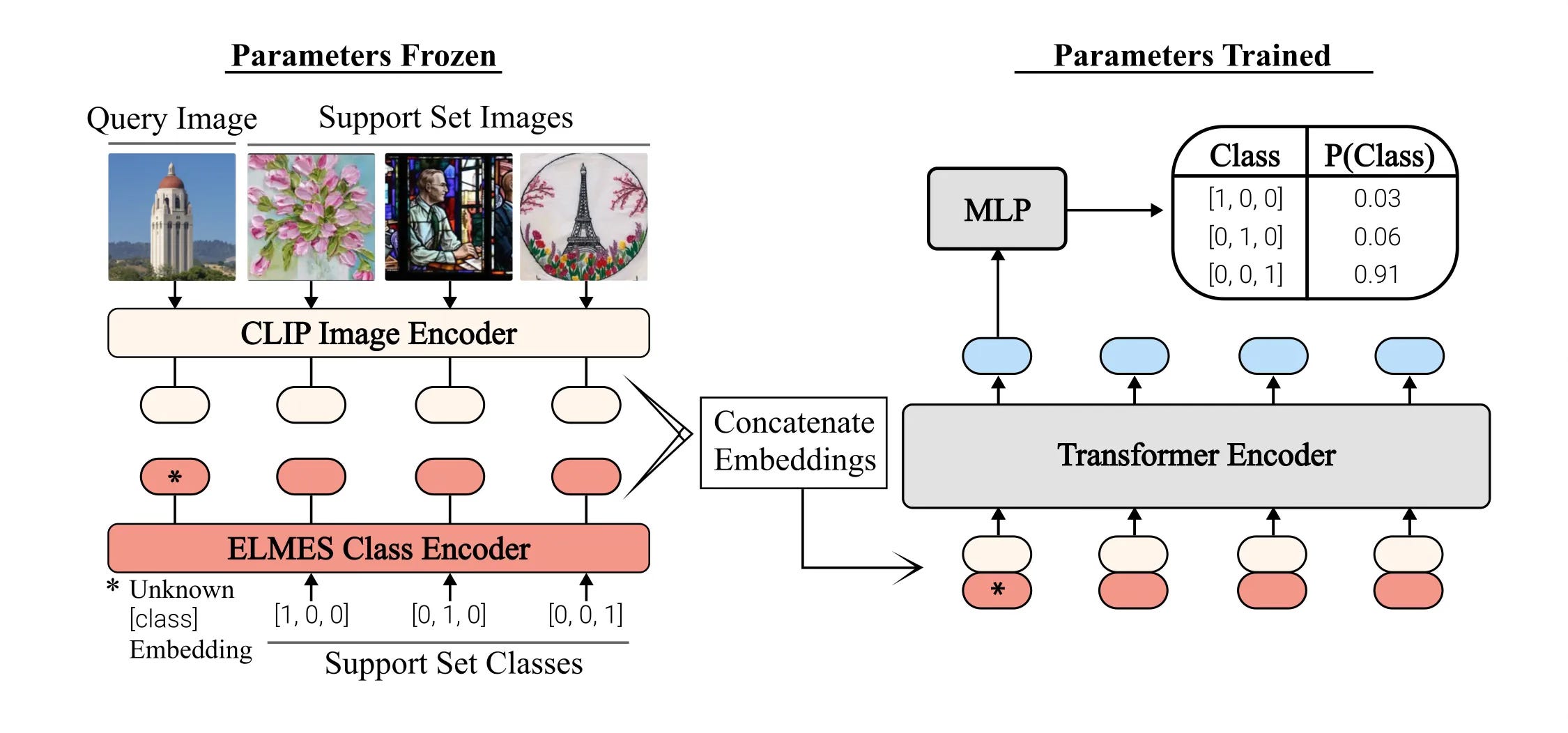
This study developed a meta-learning approach which emulates LLMs, learning new visual concepts at inference time without the need for any fine-tuning. This can then be described as a in-context learning approach for visual foundation models.
Due to its capacity to learn visual information “in-context”, we term our approach Context-Aware Meta-Learning (CAML). — Source
The study found, that with the CAML approach, without any meta-training or fine-tuning improved performance can be achievable compared to current meta-learning and fine-tuning approaches.
With the possibility to deploy visual models in a similar way than LLMs, the way is pathed for the implementation of multi-modal models and a closer alignment of data and training implementations.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.