Creating A Benchmark Taxonomy For Prompt Engineering
Benchmarking prompts presents challenges due to differences in their usage, level of detail, style, and purpose.

A recent study tackled this issue by developing a taxonomy called TELeR (Turn, Expression, Level of Details, Role), which aims to comprehensively benchmark prompts across these dimensions.
Introduction
The aim of this study is to allow future reporting on specific prompt categories and meaningful comparison between prompts.
Establishing a common standard through some kind of taxonomy will allow the taxonomy to act as a reference when measuring and comparing the performance of different LLMs against varying prompts.
There has also been the emergence of prompt hubs, the most notable open prompt hubs are from LangChain and Haystack. Establishing a standard taxonomy will help with categorising and sorting prompts. And afford users a template to use while navigating prompt hubs, ensuring the prompt fits the application they have in mind.
Prompt Engineering
The quality and effectiveness of the prompt can greatly influence the performance of Large Language Models (LLMs) for a particular task.
Therefore, designing appropriate prompts with the right amount of detail has become more important than ever.
What makes this study interesting, is that the researchers exclusively focus on understanding the potential of Large Language Models (LLMs) for performing complex tasks that are characterised by the following traits:
Ill-defined tasks
Abstract and goal-oriented
Highly dependent on subjective interpretation
Very hard to evaluate quantitatively.
These complex tasks often involve multiple steps or sub-tasks, making the design of appropriate prompts particularly challenging, as there is no single rule book to follow.
Added to this, the more complex the task, the larger the number of variances and possible permutations of the prompt.
More On TELeR (Turn, Expression, Level of Details, Role)
Goals
Setting clear goals helps the language model understand the task or question, increasing the likelihood of obtaining the desired output.
Avoiding vague or ambiguous terms is crucial to prevent inaccurate or irrelevant responses. Be explicit in terms of instructions.
Associated Data
Some prompts require LLMs to perform a task on data provided by the user in real-time (including RAG), while others rely solely on the pre-trained model to generate responses based on its background knowledge.
It is crucial to explicitly indicate in LLM prompts whether the user is providing data and, if so, to distinguish clearly between the data and the directive parts of the prompt.
Sub-Tasks
Complex tasks consist of multiple steps or sub-tasks. It is important to clearly outline these distinct sub-tasks in the prompt as separate bullet points or numbered items.
This visual organisation helps LLMs recognise each sub-task and respond to them individually.
Evaluation Criteria/Few-Shot Examples
LLMs can benefit from example-based learning, where prompts include specific examples of desired input-output pairs (few-shot examples). By incorporating relevant examples, users can guide the model to follow specific patterns or mimic desired behaviours.
RAG
Both Small & Large Language Models excel at in context learning (ICL), where the model abandon its pre-trained knowledge and rely on contextual reference data injected at inference.
Self-Explain
LLMs are capable not only of generating textual responses but also of providing explanations for their outputs if explicitly requested in the prompt.
Context & Role
Including relevant context and background information in the prompt can help the model generate more accurate responses.
For complex tasks, providing a clear understanding of the context enables the model to make more informed and precise decisions.
The level of context provided in different prompts can significantly impact the accuracy of the model’s responses.
Expression Style
Directives can be expressed primarily in two styles:
Questions
Instructions
For complex tasks, one may choose to frame directives as either a set of questions or instructions based on their preference or the specific needs of the application.
Interaction Style
Prompts for complex tasks typically consist of lengthy text descriptions, often containing details of associated sub-tasks to be performed step-by-step.
Consequently, some users may opt to provide these instructions in a multi-turn fashion, resembling a real dialogue, while others may prefer to convey all the details in a single turn.
This choice between one-turn and multi-turn prompting can significantly impact the performance of an LLM, as the dialogue history differs in generation time between these two approaches.
Turn
Based on the number of turns used while prompting LLMs in order to perform a complex task, prompts can be either single or multi-turn.
Expresion
Based on the expression style of the overall directive as well as the associated sub-tasks, prompts can be either question-style or instruction-style.
Role
Based on whether a proper system role is defined in the LLM system before providing the actual prompt, prompts can be categorised as either system-role defined or undefined.
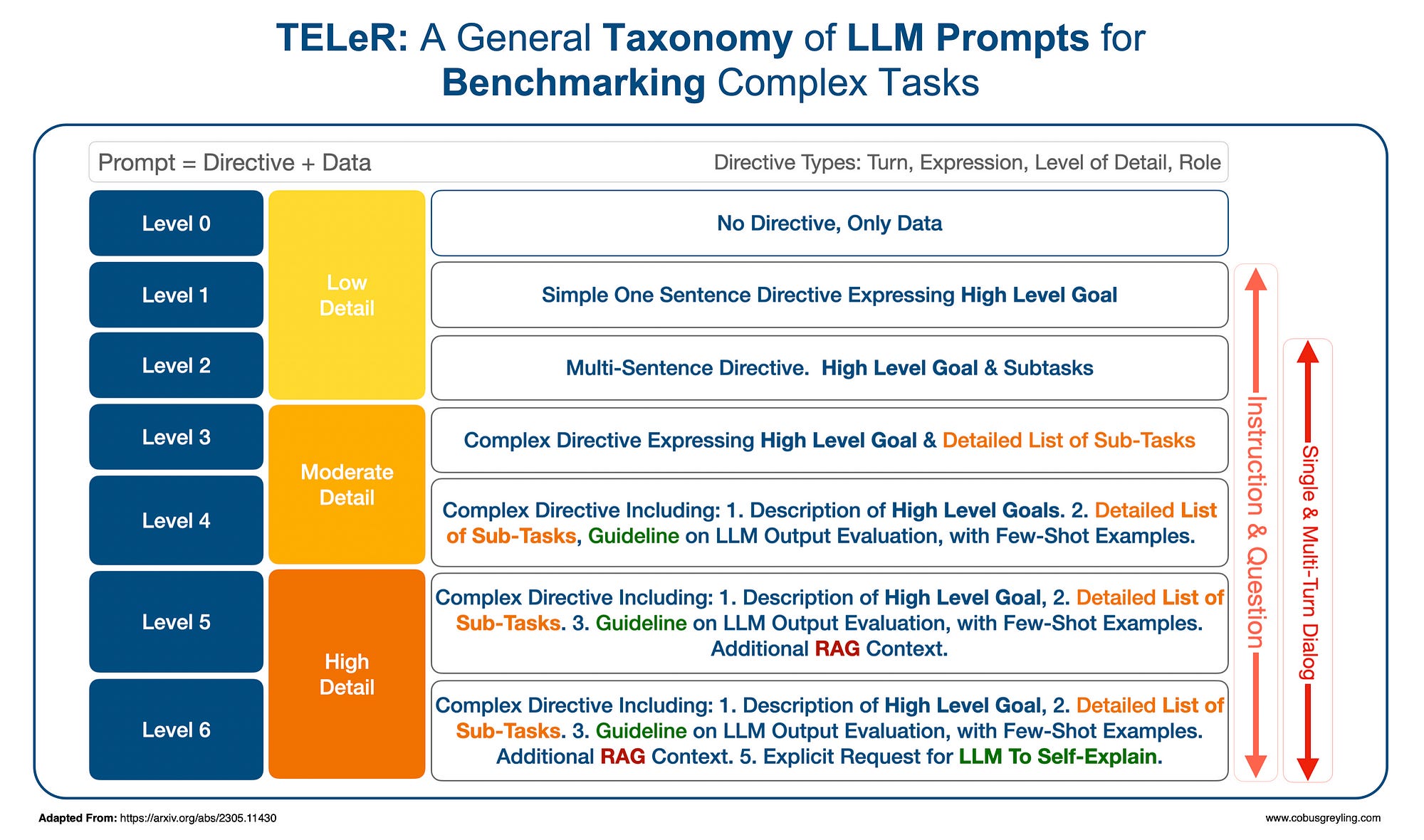
Level of Detail
Based on the degree of detail provided in the directive, the researchers divided prompts into seven distinct levels (levels 0–6).
In Conclusion
This paper emphasises the importance of a standardised taxonomy for LLM prompts aimed at solving complex tasks.
The TELeR taxonomy, which can serve as a unified standard for comparing and benchmarking the performances of LLMs as reported by multiple independent research studies.
Standardisation of comparison can enable more meaningful comparisons among LLMs and help derive more accurate conclusions from multiple independent studies.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.