Creating Training Data For Text Classification In Google Cloud Vertex AI
In the coming posts I will be doing a few deep dives on Google Vertex AI. This post focusses on data engineering and following a data-centric approach to AI.


Datasets is the first step in the Vertex AI workflow.
In a previous post on Vertex AI I gave an overview of Vertex AI within the context of LLMs and Generative AI. In this post I consider the practicalities around engineering training data.
Data-centric AI is the discipline of systematically engineering the data used to build an AI system.
~ DCAI
A data-centric approach to training data for AI, and in this case text classification, demands a continuous life-cycle as described in the image below.
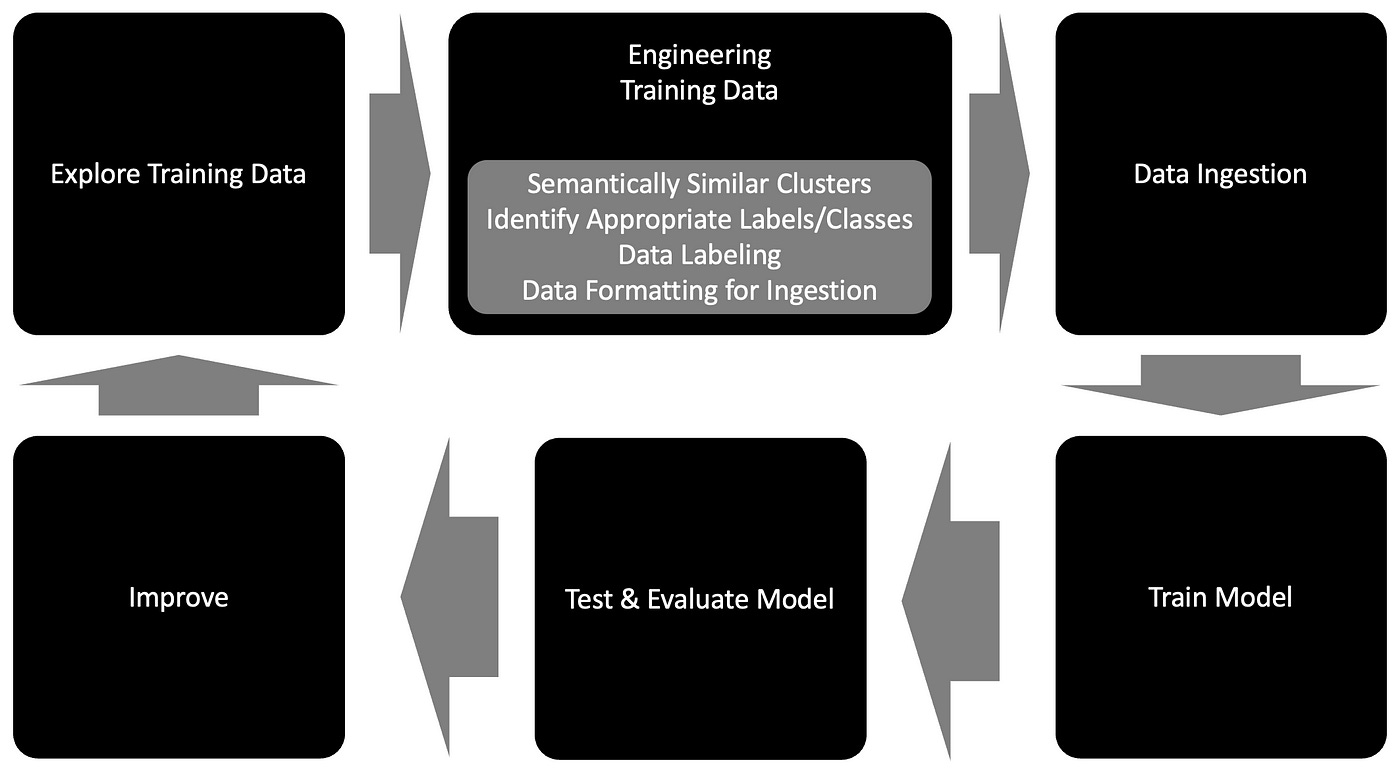
Starting with the ability to explore training data via a latent space. A latent space can be described as an environment where data is compressed in such a way that patterns, clusters and other insights emerge from the data.
Following exploration, a human-in-the-loop process with weak supervision is required for identifying classes and applying those class label to the data.
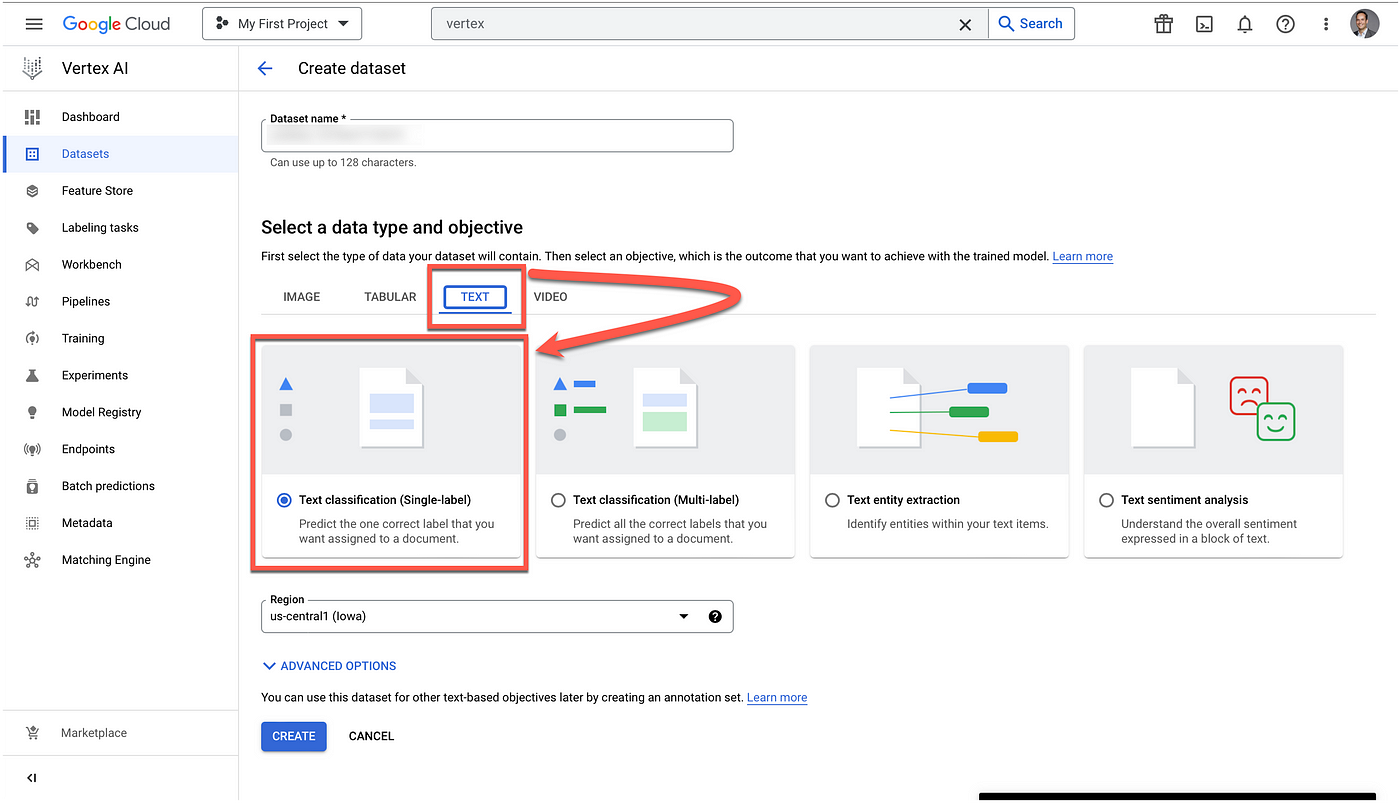
A big vulnerability and current void within Vertex AI is this process of Data Centric AI. The data presented to Vertex AI needs to be already engineered and structured for training.
The Vertex AI formatting requirements for JSON & CSV data files is highly complex and takes effort to produce. As seen in the JSON formatting below:
{"textGcsUri":"gs://cloud-ai-platform-cbb21882-3e0b-4f11-88b9-21bd2fb3a35e/dataset-3591873590502359040/preprocessed_example/4214918245292965888/75173735366921/text.txt",
"languageCode":"",
"classificationAnnotation":{"displayName":"achievement",
"annotationResourceLabels":{"aiplatform.googleapis.com/annotation_set_name":"2418892595758366720"}},"dataItemResourceLabels":{}}With the path pointing to the text below, which is labeled as: achievement
My eldest son who is 27 just got word he has a new job after finishing his bachelors degree. This made me very happy!The JSON portion above is only for one labeled record, below is a text file view of a file which contains thousands of records.

The data is formatted in such a way, that it is tightly integrated with the Google Cloud data bucket structure which adds complexity.
Vertex AI is a no-code studio environment to build, deploy & scale machine learning (ML) models. Managed ML tools are available for a myriad of use-cases.
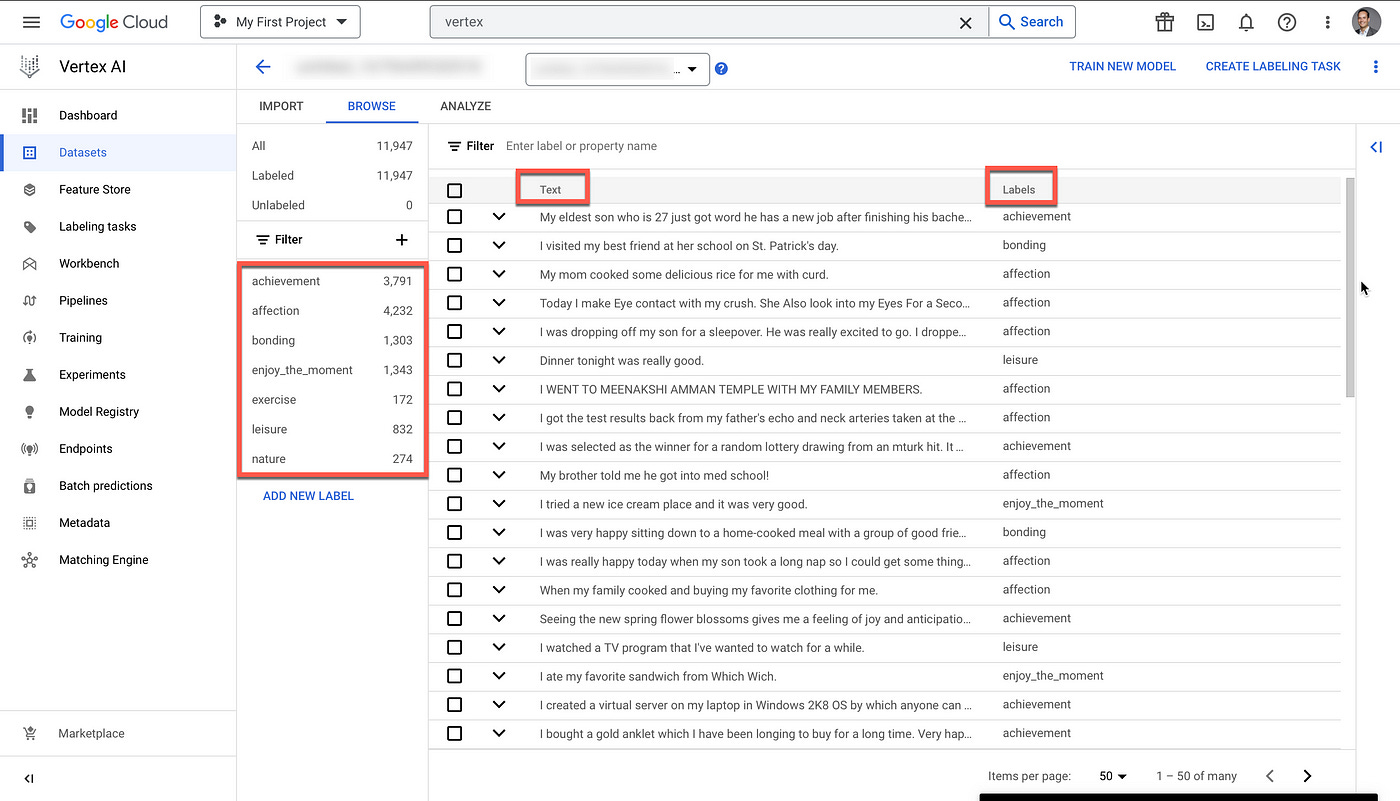
As seen below, once the data is imported the text is visible with each label assigned to the text. Basic functionality is available like filtering, searching and editing the training data.
Something I found curious, is the fact the via Vertex AI it is possible to request human labellers add labels to data.
According to Google, Vertex AI data labelling tasks allow you to work with human labellers to generate highly accurate labels for your collection of data.
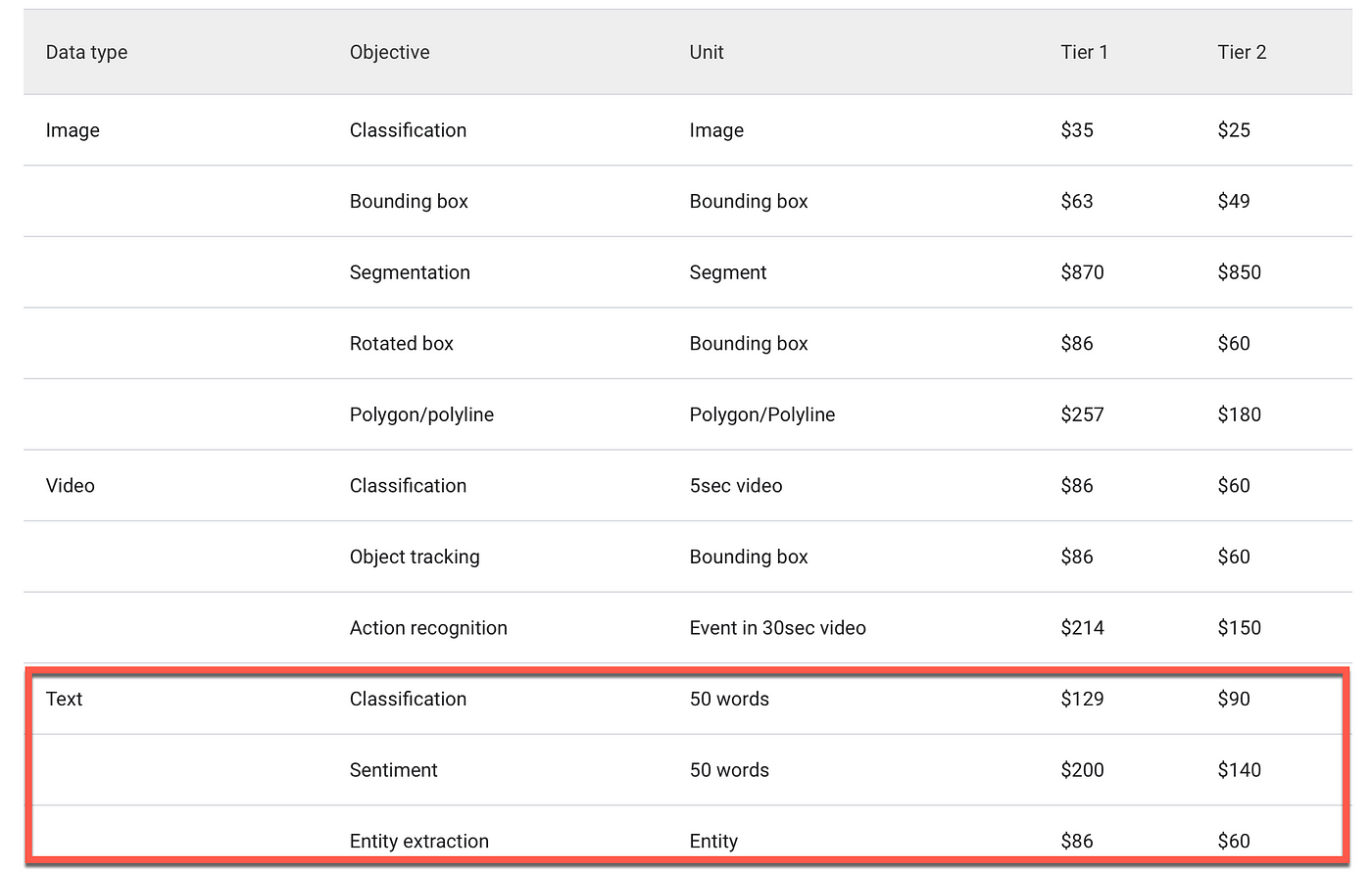
Prices for the service are computed based on the type of labelling task.
For a text classification task, units are determined by text length (every 50 words is a price unit) and the number of human labellers.
For example, one piece of text with 100 words and 3 human labellers counts for 100 / 50 * 3 = 6 units. The price for single-label and multi-label classification is the same.
In Closing
A hallmark of so-called traditional NLU Engines is the ease with which data can be entered. This is definitely not the case with Vertex AI.
Functionality for a continuous process of data exploration, curation, structuring (engineering) of data and ingestion is not defined or enabled.
Shipping data off to independent human labellers seems counterintuitive and I would rather opt for an automated process with human supervision.
The multi-modal nature of Vertex AI bodes well for the future of Foundation Models with the inclusion of text, tabular data, images and video.

⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.

