

Develop Generative Apps Locally
I wanted to create a complete Generative App ecosystem running on a MacBook & this is how I did it.

Introduction
For me at least, there is a certain allure to running a complete generative development configuration locally on CPU.
The process of achieving this was easier and much less technical than what I initially thought.
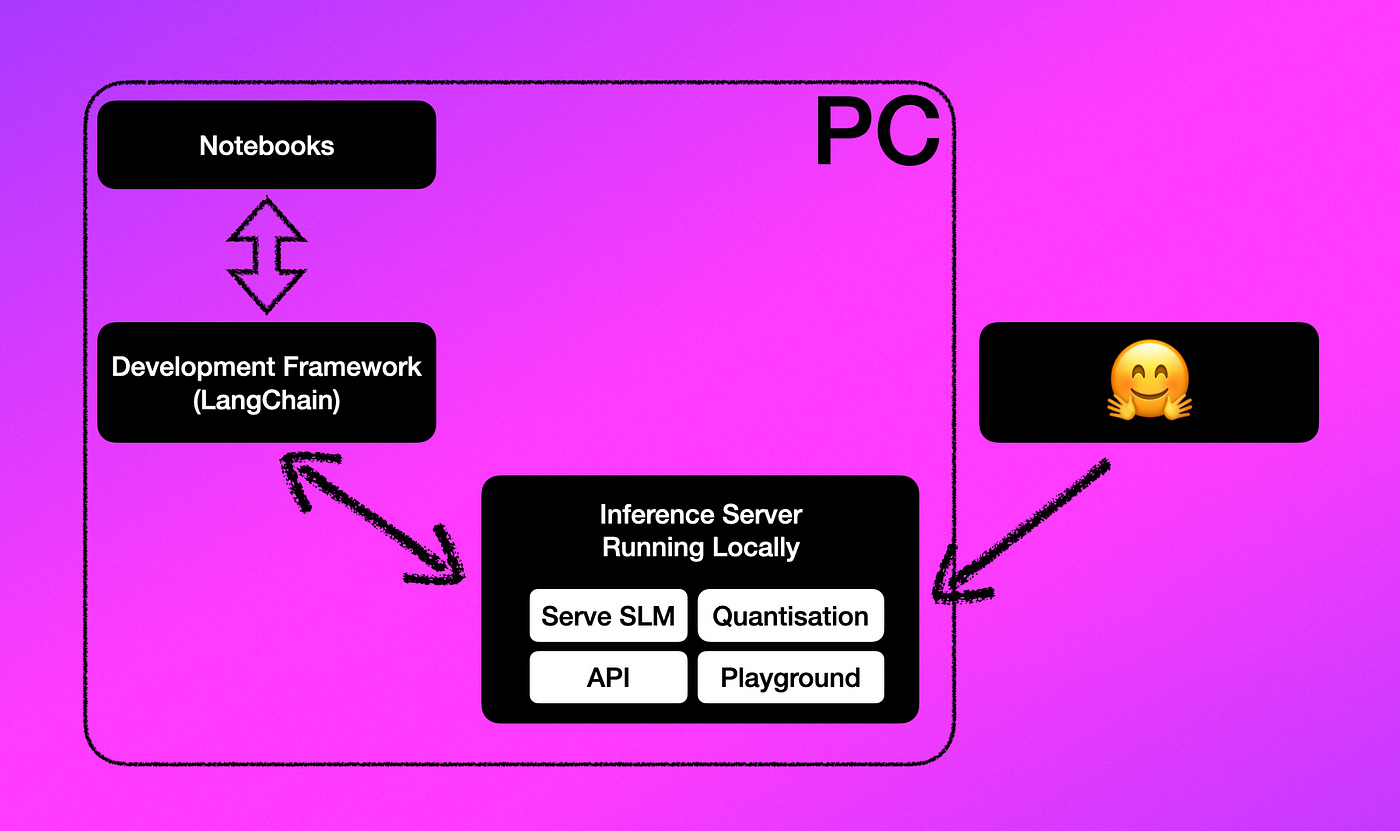
Small Language Models (SLMs) can be accessed via HuggingFace, and making use of an inference server like TitanML’s TakeOff Server the SLM can be served locally.
The Inference server pulls a model from the HuggingFace Hub, and defining the model to use is very easy with the TitanML inference server. The inference server goes off, finds the model and downloads it locally.
The Inference Server serves the language model, makes APIs available, offers a playground and performs quantisation.
Small Language Model
In a previous article on quantisation, I made use of TinyLlama as the SLM. TinyLlama is a compact 1.1B Small Language Model (SLM) pre-trained on around 1 trillion tokens for approximately 3 epochs.
Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes.
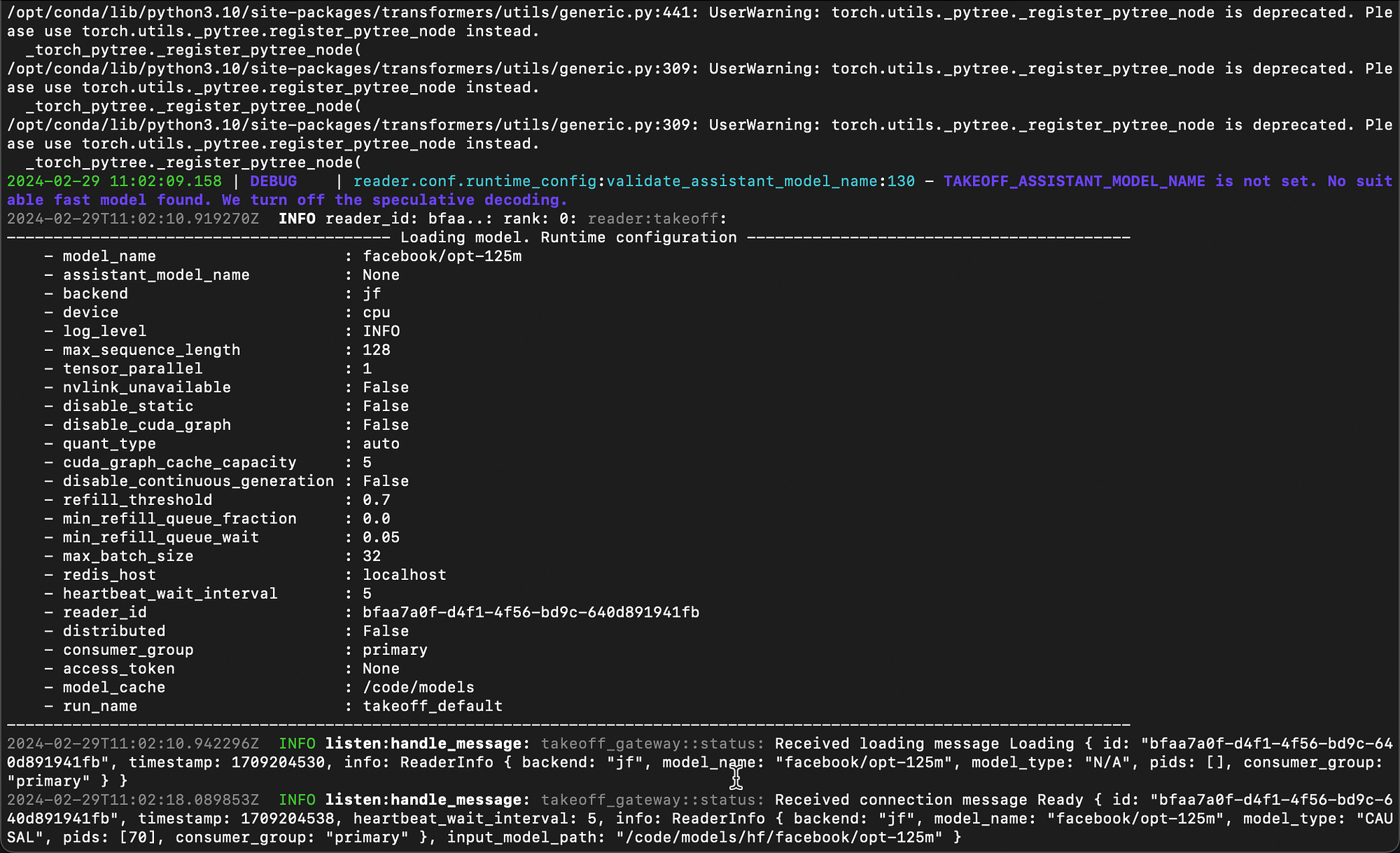
In this prototype, I used Meta AI’s opt-125m Small Language Model. The pretrained only model can be used for prompting for evaluation of downstream tasks as well as text generation. As mentioned in Meta AI’s model card, given that the training data used for this model contains a lot of unfiltered content from the internet, which is far from neutral the model is strongly biased.
Local Inference Server
The TitanML Inference Server is managed via Docker, and can easily be setup with only two commands; once Docker is installed.
docker pull tytn/takeoff-pro:0.11.0-cpu
and
docker run -it \
-e TAKEOFF_MODEL_NAME=TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
-e TAKEOFF_DEVICE=cpu \
-e LICENSE_KEY=<INSERT_LICENSE_KEY_HERE> \
-e TAKEOFF_MAX_SEQUENCE_LENGTH=128 \
-p 3000:3000 \
-p 3001:3001 \
-v ~/.model_cache:/code/models \
tytn/takeoff-pro:0.11.0-cpu
Below is a screenshot of the inference server starting, notice the model detail being shown…
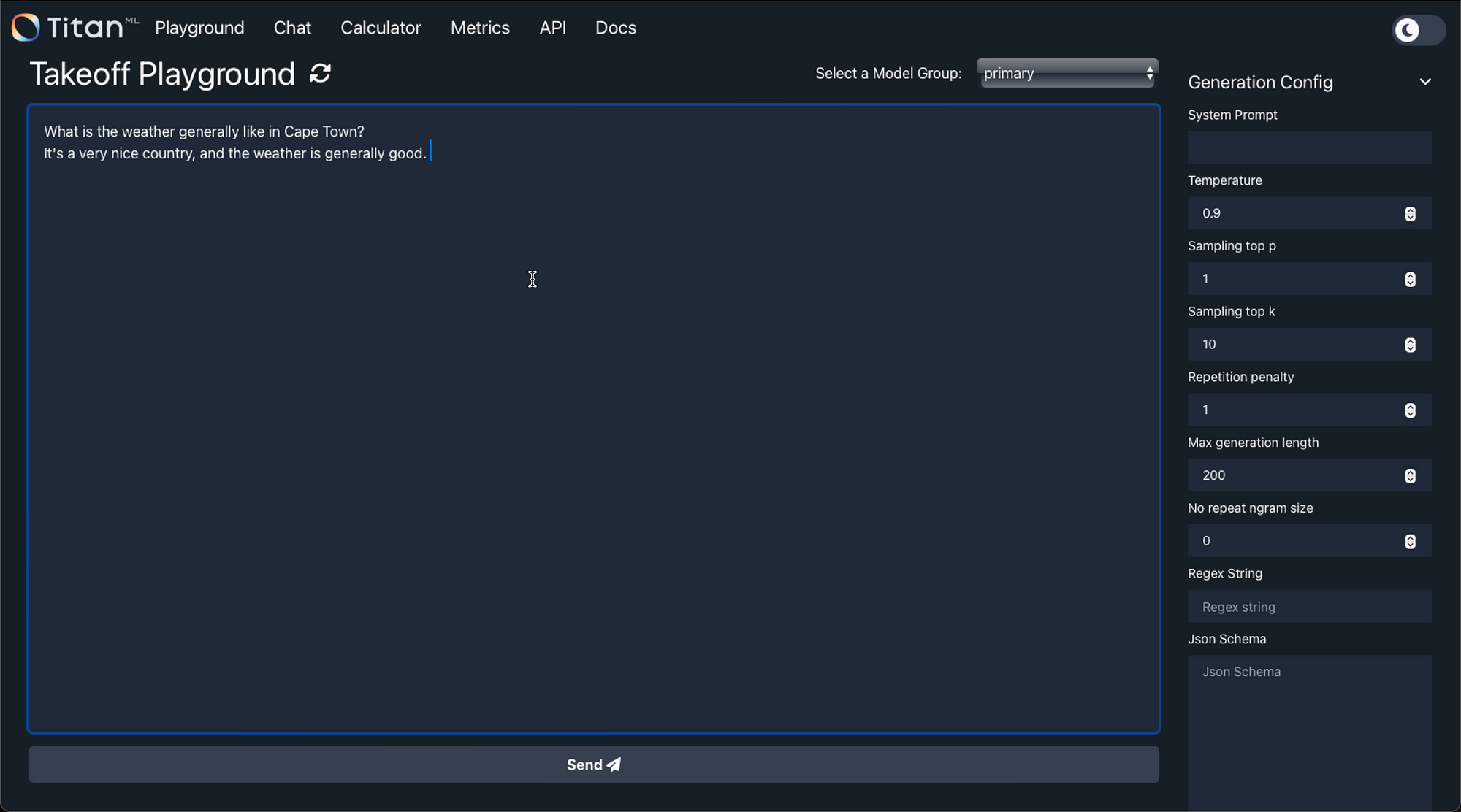
And by accessing the url
http://localhost:3000/#/playground
the playground can be accessed, all offline and running locally.
Below is a link to the model I made use of in HuggingFace. I was surprised by the ease with which models can be referenced, downloaded and run all very seamlessly managed by the inference server.
facebook/opt-125m · Hugging Face
We're on a journey to advance and democratize artificial intelligence through open source and open science.
Notice how the model name is defined within the script to start and run the inference server instances.
docker run -it \
-e TAKEOFF_MODEL_NAME=facebook/opt-125m \
-e TAKEOFF_DEVICE=cpu \
-e LICENSE_KEY=KGNHZ-TOILC-HVUWI-PVZIS \
-e TAKEOFF_MAX_SEQUENCE_LENGTH=128 \
-p 3000:3000 \
-p 3001:3001 \
-v ~/.model_cache:/code/models \
tytn/takeoff-pro:0.11.0-cpuNotebook
As seen in the image below, the Jupyter notebook instance was also running locally, where LangChain was installed with the TitanML libraries.
LangChain Applications
Here is the most simple version of a LangChain application posing a question to the LLM.
pip install langchain-community
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.prompts import PromptTemplate
from langchain_community.llms import TitanTakeoffPro
# Example 1: Basic use
llm = TitanTakeoffPro()
output = llm("What is the weather in London in August?")
print(output)And two different questions can be asked simultaneously.
llm = TitanTakeoffPro()
rich_output = llm.generate(["What is Deep Learning?", "What is Machine Learning?"])
print(rich_output.generations)And lastly, using LangChain’s LCEL:
llm = TitanTakeoffPro()
prompt = PromptTemplate.from_template("Tell me about {topic}")
chain = prompt | llm
chain.invoke({"topic": "the universe"})Conclusion
Advantages of local inference includes:
Reduced Latency
Local inference eliminates the need to communicate with remote servers, leading to faster processing times and lower latency. This is especially beneficial for applications requiring real-time responses or low-latency interactions. This is especially true when SLMs are made use of.
Improved Privacy and Security
By keeping data on the local device, local inference minimises the risk of exposing sensitive information to external parties. This enhances privacy and security, as user data is not transmitted over networks where it could potentially be intercepted or compromised.
Offline Functionality
Local inference enables applications to function even without an internet connection, allowing users to access language models and perform tasks offline. This is advantageous in scenarios where internet access is limited or unreliable, ensuring uninterrupted functionality and user experience.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.