Enterprise Prompt Engineering Practices
By analysing sessions of prompt editing behaviour, IBM identified patterns in prompt refinement, including the aspects users iterate on and the types of modifications they make.


This analysis sheds light on prompt engineering practices and suggests design implications and future research topics.
Introduction
Interacting with Large Language Models (LLMs) relies heavily on prompts, in essence prompts are natural language instructions aiming to prompt (elicit) specific behaviour or output from the model.
While prompts theoretically enable non-experts to access LLMs, crafting effective prompts for complex or specific tasks is challenging.
It demands skill, knowledge, and iterative refinement to guide the model towards desired outcomes.
IBM Research has studied how users iterate on prompts and this research offer insights into the understanding of
Prompt usage and
Model behaviour, and
The necessary support required for efficient prompt engineering.
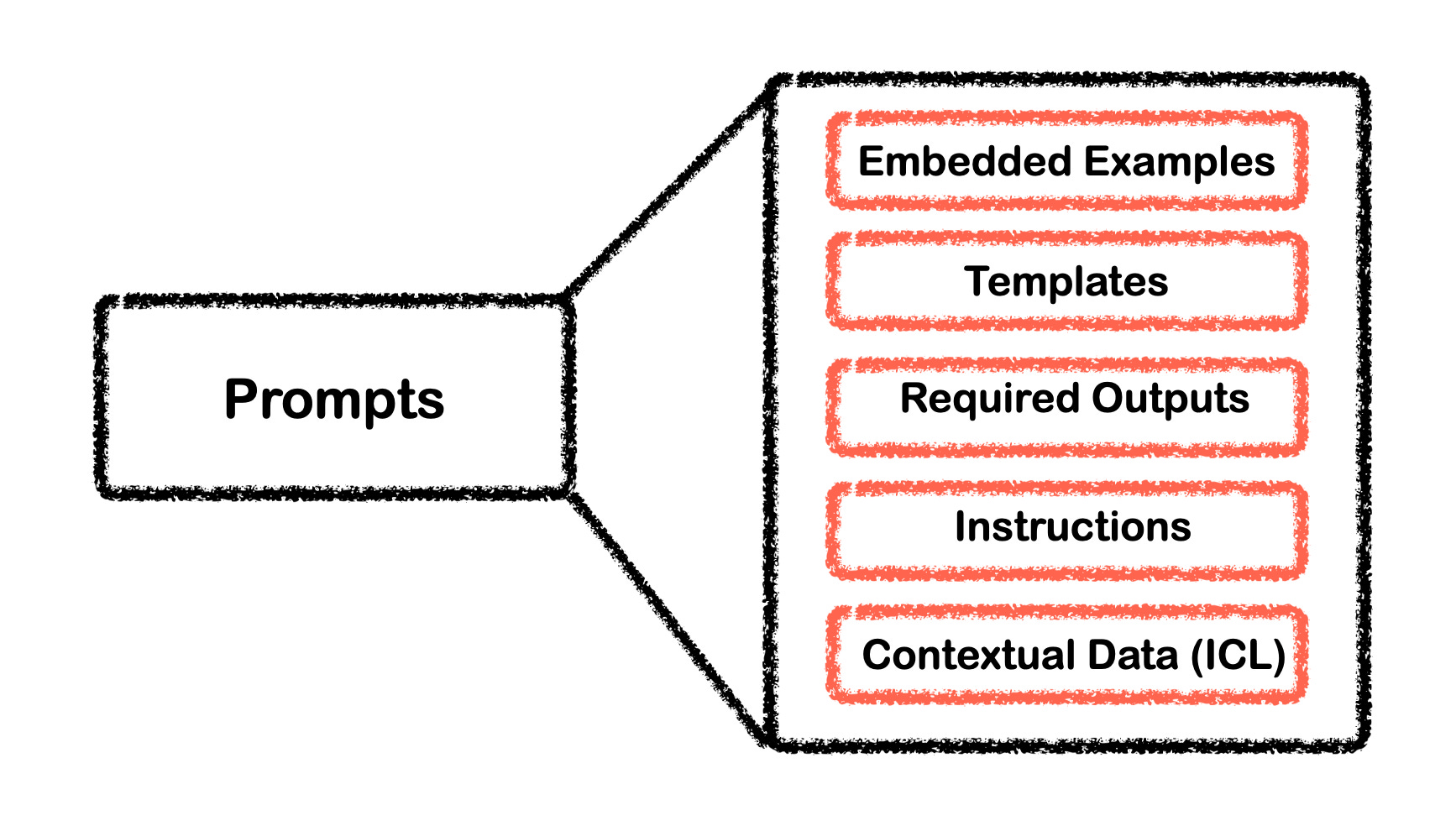
In general prompts can contain embedded examples, templates, a description of the required outputs, instructions and contextual Data for In-Context Learning.
Results
The findings are divided into two sections.
Initially, the study provides a broad quantitative analysis of the observed prompt editing sessions.
Subsequently, the study delves into more comprehensive results stemming from review and annotation processes, incorporating qualitative observations.
The prompt editing sessions typically lasted for a considerable duration, with an average session spanning approximately 43.4 minutes.
Users often focus on editing prompts alongside or instead of adjusting other model parameters.
Users tend to not be erratic in their prompt refinement iterations, choosing to make smaller iterative changes to prompts in order to reach the desired outcome.
Users frequently adjusted inference parameters while refining their prompts, with 93% of observed sessions incorporating one or more changes to these parameters.
The most frequently altered parameter was the target language model (
model id), followed by adjustments to themax new tokensandrepetition penaltyparameters.
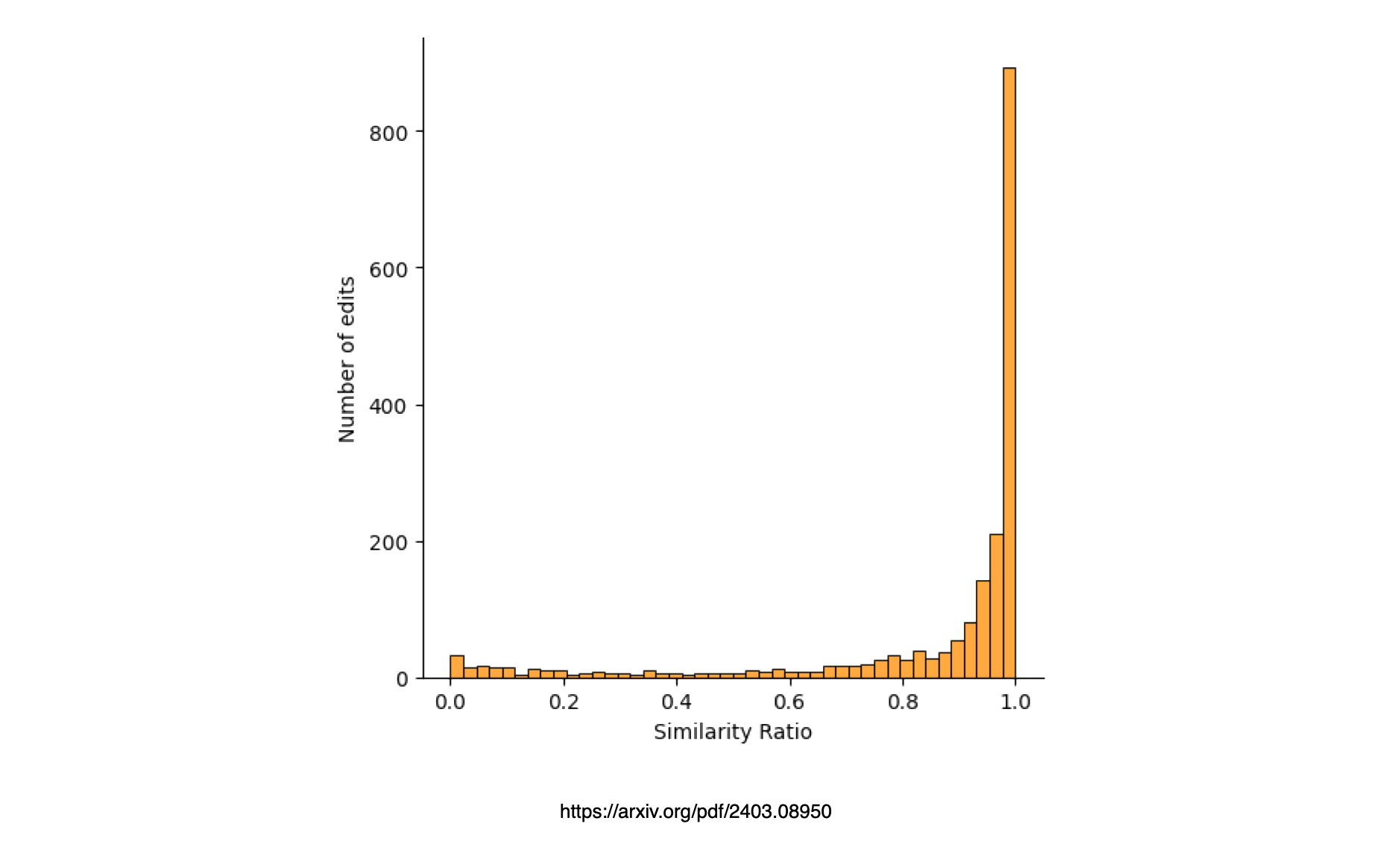
The magnitude of change between successive prompts was quantified using a similarity ratio.
Values approaching 1 signify a high degree of similarity between successive prompts, with 1 indicating an exact match, while a ratio of 0 indicates no common elements between prompts.
From this graph it does seem like users tend to make smaller iterative changes to prompts in order to reach the desired outcome.
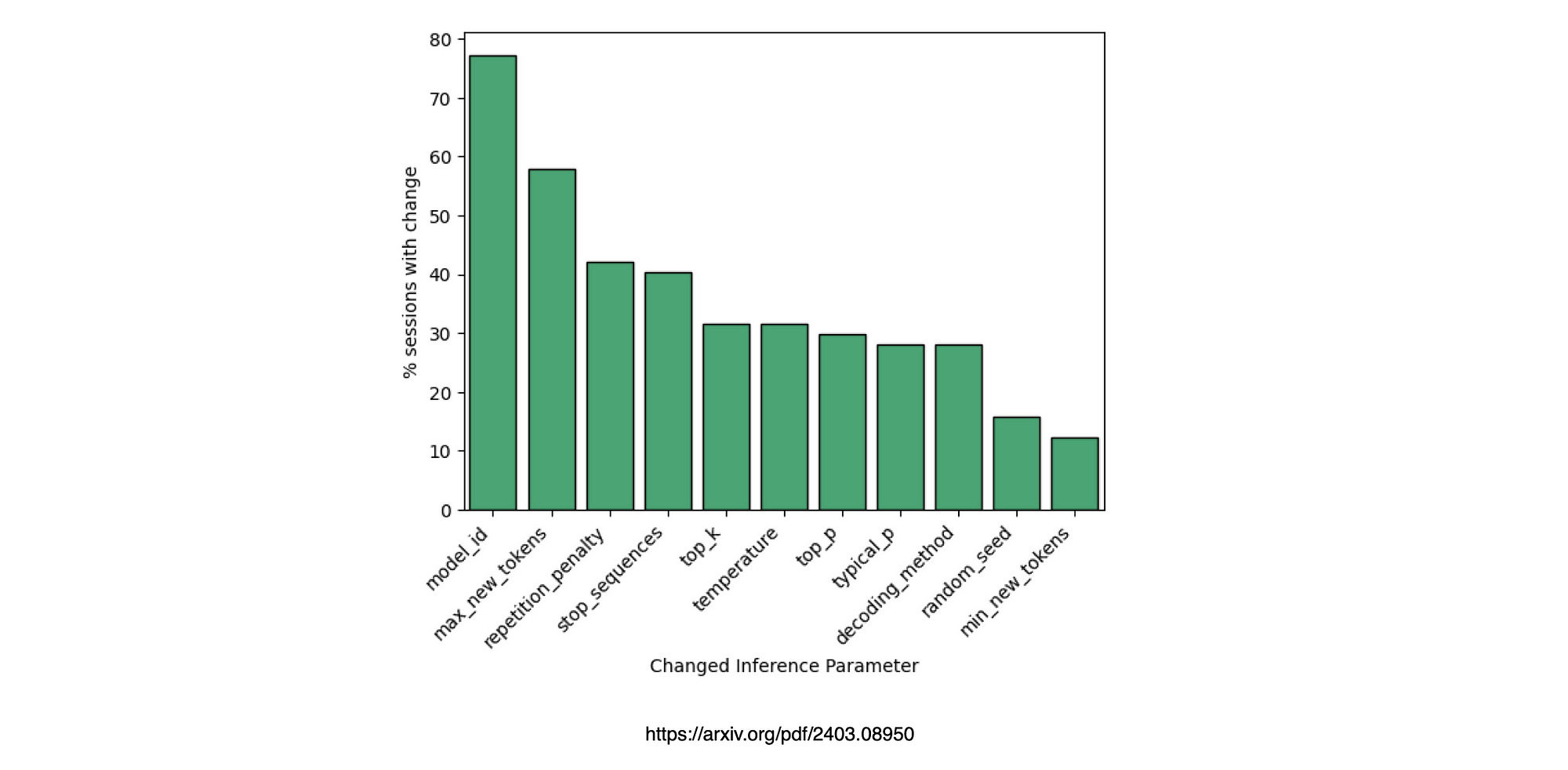
Parameter changes were recorded as a percentage of sessions in which the change occurred.
Users predominantly modified the target language model, adjusted the maximum number of tokens to generate, and fine-tuned the repetition penalty. Additionally, changes to the stop sequence, temperature, and decoding method were frequently observed.
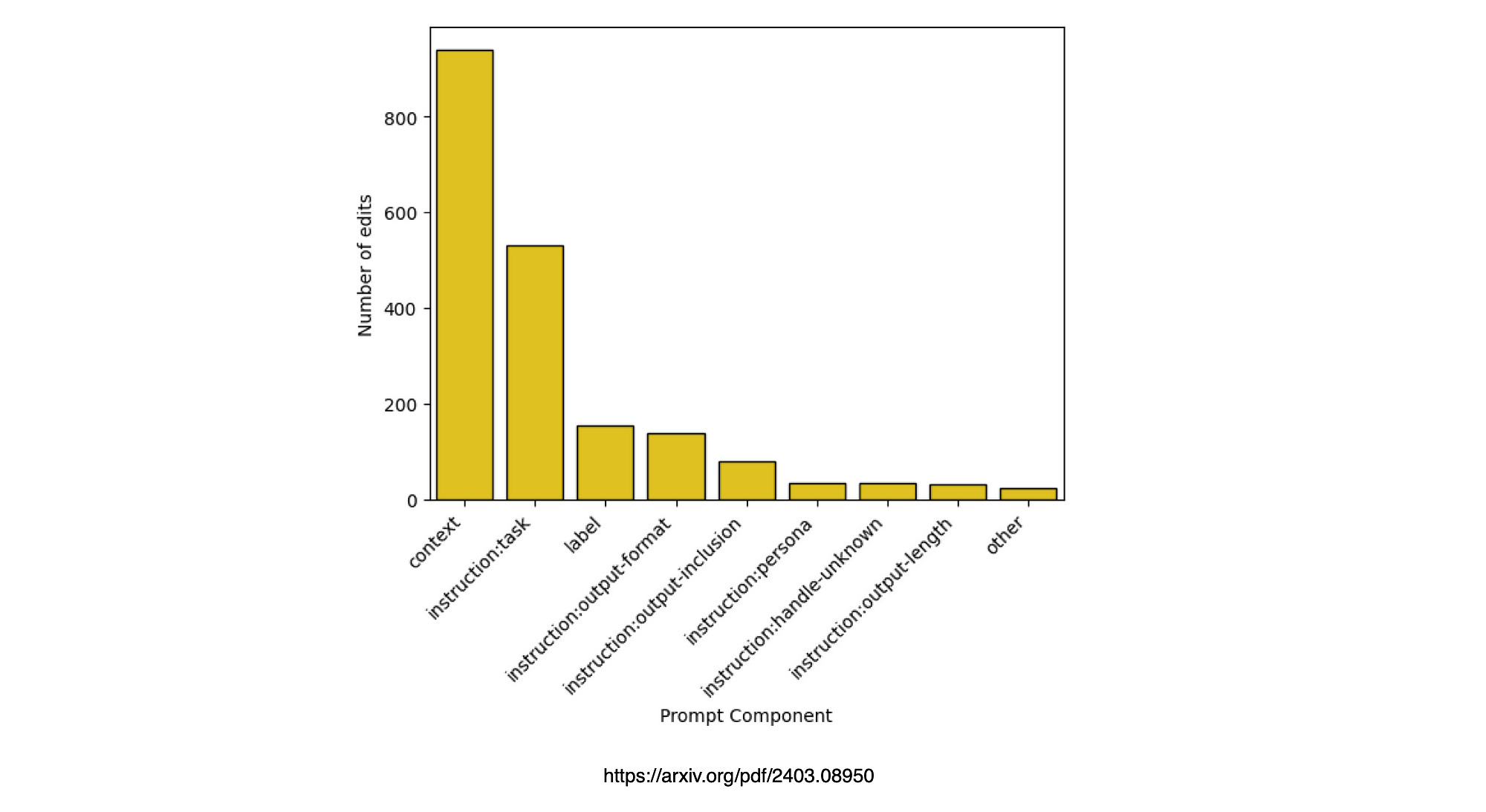
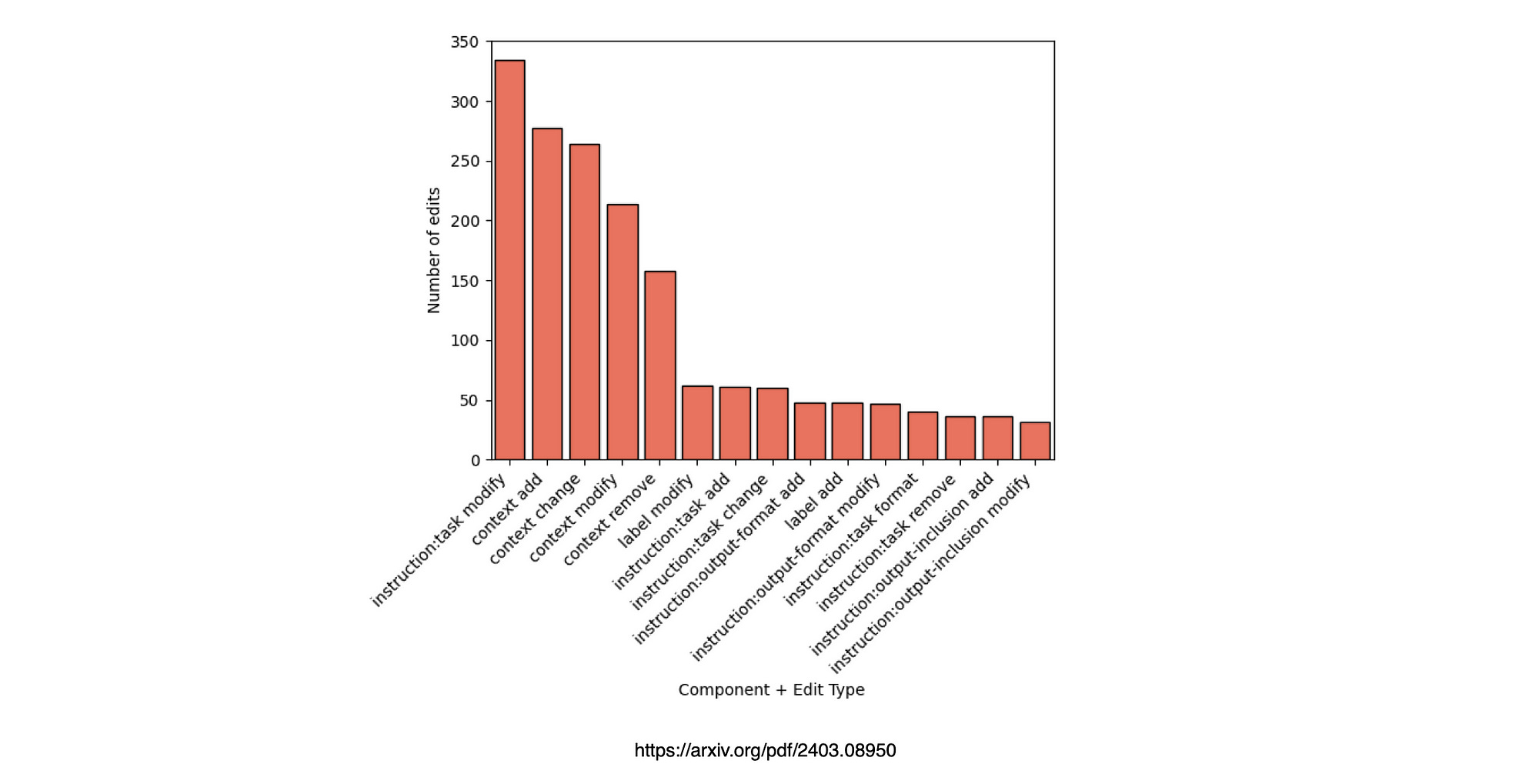
Number of edits that focused on each of the prompt components. Users primarily edited context, and task instructions to a lesser extent.
This goes to show again that context in terms of leveraging in-context learning (ICL) is very important, followed by instruction.
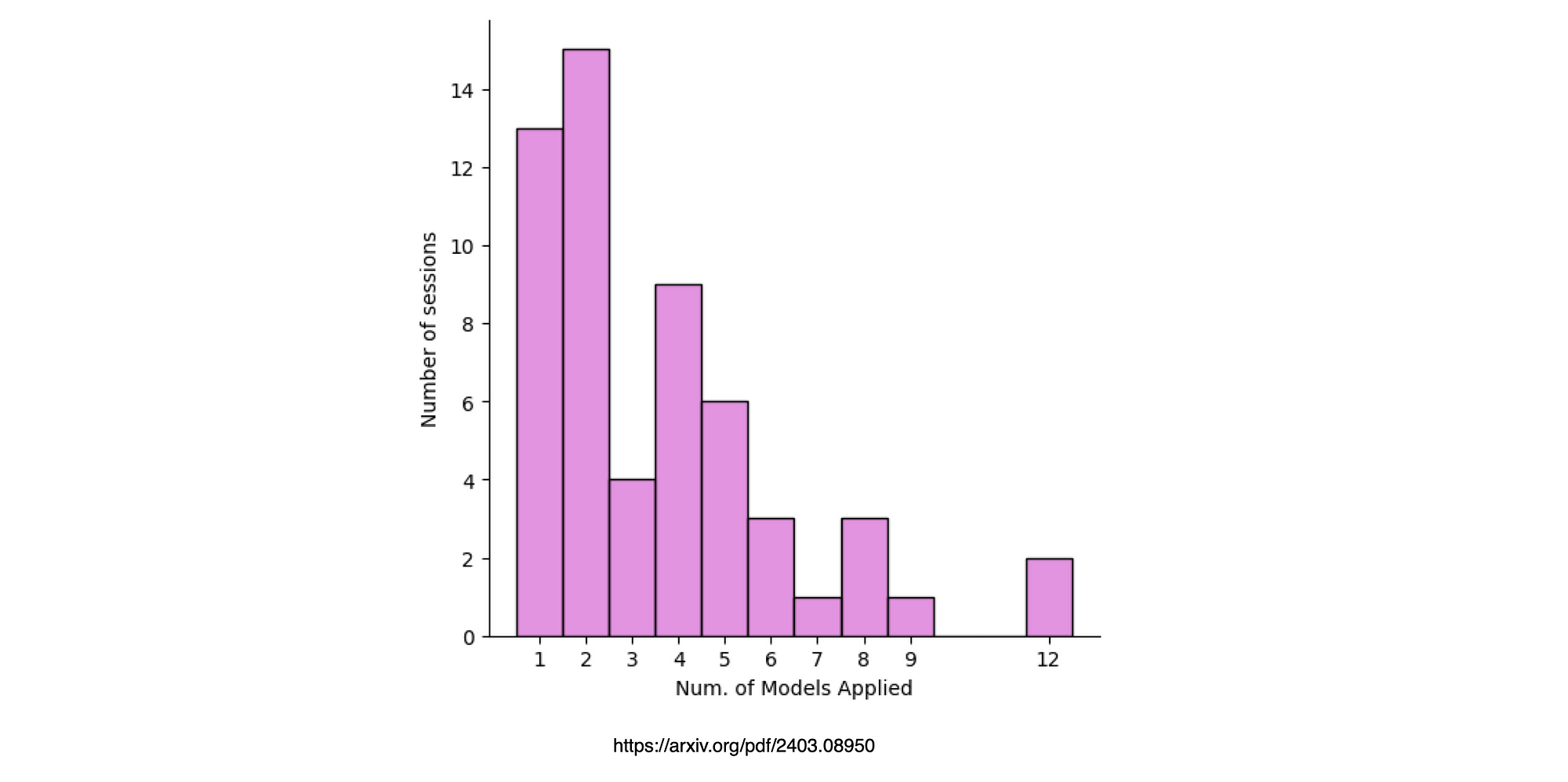
The graph below shows the number of models used, interesting that most sessions looked at two models, probably performing an easy A/B testing approach.
The edit types which were the most used were modify tasks and also tasks where the context of the text haded to be augmented, changed, modified or removed.
Context
The majority of analysed prompts and use-cases were context-based.
Input, grounding data, or examples were integrated within the prompt itself, distinct from task instructions.
Notably, context emerged as the most frequently edited component across all analysed sessions, underscoring its significance for enterprise tasks.
Two prevalent patterns of context additions:
Simulating dialog &
Adding examples.
The prompt development interface facilitated this by directly appending generated output to the input prompt text, simplifying the generation of conversation turns.
However, since each turn adds to the context, users often needed to remove surplus context before testing other edits.
Users typically employed a specific context to craft and fine-tune their task instructions. Then they would assess the effectiveness of these instructions by substituting different contexts and observing model output variations. Also, users frequently directly edited existing context, such as modifying contextual queries or input data examples.
Multiple Edits
22% of edits were multi-edits, where users made several changes at once before submitting the prompt again.
On average, these multi-edits included about 2.29 changes, with most involving edits to the context.
Around 68% of multi-edits involved context changes.
While multi-edits might seem efficient, they can complicate tracking the impact on the output. Additionally, about 1/5 of edits were accompanied by a change in inference parameters, suggesting a need for more systematic approaches to managing changes and understanding their effects on model behaviour.
Rollbacks
Around 11% of prompt edits involved undoing or redoing a previous change, despite still being counted as individual edits.
This behaviour might suggest difficulties in remembering past outcomes or uncertainty about which edits could enhance the output.
Interestingly, less frequently edited prompt components tended to have higher rates of undoing edits.
For instance, 40% of edits for instructions:handle-unknown were rolled back, along with 25% for instruction:output-length, 24% for labels, and 18% for instruction:persona edits.
In Conclusion
The study analysed 57 prompt editing sessions, comprising 1523 individual prompts, using an enterprise LLM tool that facilitates prompt experimentation and development.
Users often focus on editing prompts alongside or instead of adjusting other model parameters.
Many of these edits are minor tweaks or iterations to a single prompt rather than complete overhauls.
The qualitative analysis highlights that users primarily modify prompt context, including examples, grounding documents, and input queries.
Surprisingly, context edits outnumber instruction edits, which involve describing the task or its elements such as output format, length, or persona.
Edits to labels, defining prompt components, are also common.
These insights shed light on current prompt editing practices and guide future directions for more effective prompt engineering support.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.