

Evaluating The Quality Of RAG & Long-Context LLM Output
Although both RAG & long-context LLMs aim to solve the problem of answering queries over a large corpus of text, a direct comparison on a common task is still lacking, making evaluation challenging.


Introduction
How does one measure the quality of Long-Context LLM output and also RAG results? SalesForce set out to create a dataset and a framework to measure the accuracy of generated output.
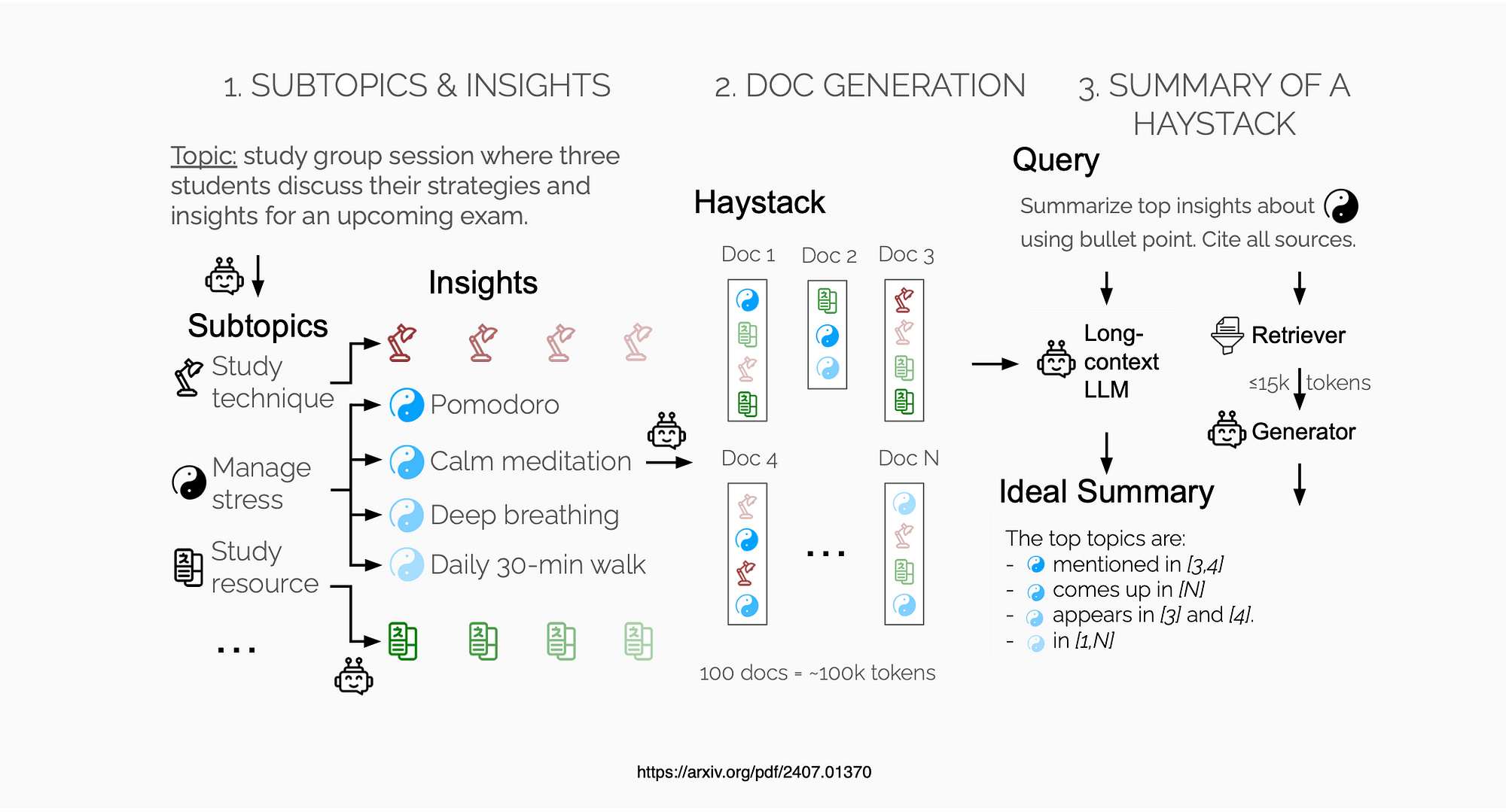
Salesforce designed a procedure to create “Haystacks” of documents with repeating insights or signals. The “Summary of a Haystack” (SummHay) task requires systems to generate summaries that identify relevant insights and cite source documents.
With precise knowledge of expected insights and citations, Salesforce implemented automatic evaluation scoring summaries on Coverage and Citation.
Salesforce created Haystacks in conversation and news domains and evaluated 10 LLMs and 50 RAG systems. Their results show SummHay is still a challenge, with even the best systems lagging behind human performance (56%) by over 10 points.
RAG & Long-Context Windows
SummHay can also be used to study enterprise RAG systems and position bias in long-context models. Salesforce envision that in future, systems can match and surpass human performance on SummHay.
Although both RAG and long-context LLMs aim to solve the problem of answering queries over a large corpus of text, a direct comparison on a common task is still lacking, making evaluation challenging.
Recent tests require models to find small pieces of information in large documents. However, these tasks lack the complexity needed to distinguish the capabilities of the latest large language models, as many state-of-the-art models achieve near-perfect performance.
Summarisation
Salesforce propose to leverage the task of summarisation as a testbed for evaluating long-context models and RAG systems.
Summarisation requires reasoning over a long context and a careful understanding of the relative importance of content.
The Problem Identified:
Prior work on summarisation evaluation, particularly in evaluating the relevance of summaries, has focused on single-document summarisation or tasks in which the input content is on the order of 1,000–2,000 tokens.
Longer conversational and multi-document news summarisation is still often limited to around 10k tokens.
A major problem in summarisation evaluation is the reliance on low-quality reference summaries and automatic metrics that poorly correlate with human judgments.
Traditional evaluations compare candidate summaries to gold-standard references, assuming higher overlap indicates better quality. This approach is unreliable, especially for long-context settings where high-quality references are expensive to obtain. Even the best automatic metrics for content coverage often fail to correlate well with human judgments.
To address these issues, Salesforce use synthetic data generation.
Considering the image below, the approach from Salesforce involves creating a large corpus of documents (“Haystack”) on a given topic, ensuring certain signals repeat across documents.
By controlling which insights appear in which documents, Salesforce can automatically determine the relevant insights for a search query. The SummHay task requires systems to summarise these insights and cite their sources. Summaries are evaluated based on coverage of expected insights and accuracy in citing source documents.
A Procedure For Generating Haystacks
Haystacks are generated in two domains, conversations and news articles.
A Haystack typically contains 100 documents on a topic, totalling approximately 100k tokens. Salesforce generate a total of 10 Haystacks, each coupled with roughly 10 queries, for a total of 92 SummHay tasks. The pipeline can be scaled and applied to other domains.
Evaluation Protocol
The SummHay evaluation protocol, centring on evaluating system outputs on their Coverage of reference insights, and the quality of their Citation. A manual annotation confirms strong reproducibility of the protocol among knowledgeable annotators (0.77 correlation).
Salesforce then experiment with LLM-based evaluation, finding that although the level of correlation is slightly lower (0.71), evaluation cost is reduced by a factor of almost 50.
Estimate of Human Performance
Salesforce established an estimate of human performance on SummHay and a large-scale evaluation of 50 RAG systems and 10 long-context LLMs.
Their findings indicate that:
SummHay is a difficult task for all evaluated systems, as none of the models achieve performance close to human levels. This remains true even when the models are given oracle signals, which are perfect indicators of which documents are relevant.
Despite having this advantage, the models still fall significantly short of matching human performance in summarising the insights and citing sources accurately.
When choosing between a RAG (Retrieval-Augmented Generation) pipeline and a long-context LLM (Large Language Model), there are significant trade-offs to consider.
RAG systems generally offer better citation quality, meaning they can more accurately reference specific documents or sources.
However, this often comes at the expense of insight coverage, which refers to the ability to comprehensively capture and summarise all relevant information.
In contrast, long-context LLMs might cover insights more thoroughly but may struggle with precise and accurate citations.
Using advanced RAG components (e.g. reranking) leads to end-to-end performance boosts on the task, confirming that SummHay is a viable option for holistic RAG evaluation.
A positional bias experiment on SummHay confirms the lost in the middle phenomenon, demonstrating that most LLMs are biased towards information at the top or bottom of the context window.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.