Example Code & Implementation Considerations For GPT 3.5 Turbo, ChatML & Whisper
OpenAI released the API for The LLM gpt-3.5-turbo, which is the same model used in ChatGPT as we all know it.


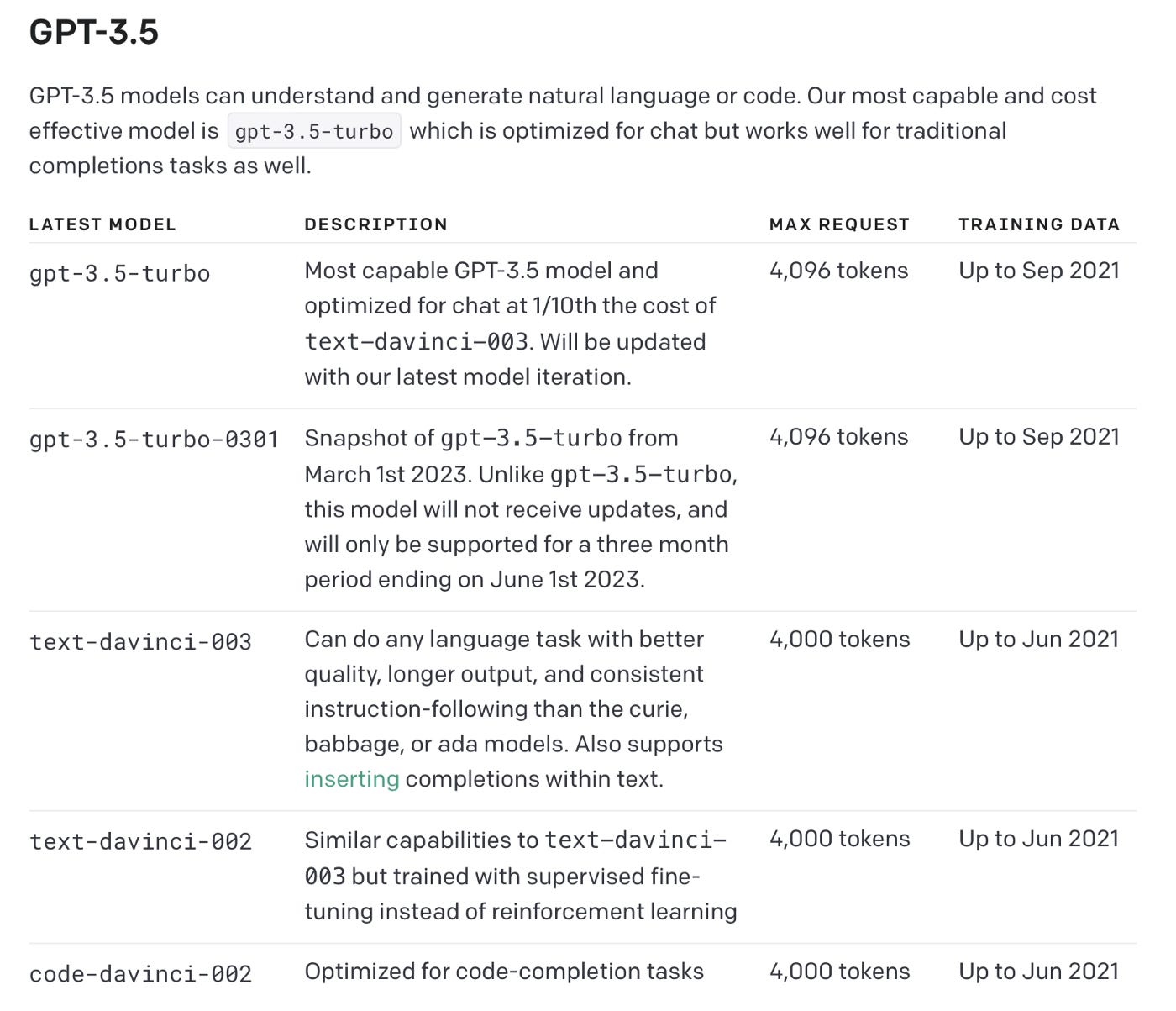
GPT 3.5 Turbo & Chat Markup Language (ChatML)
The ChatGPT models are available via API, in the examples below I used gpt-3.5-turbo, but OpenAI also reference a model named gpt-3.5-turbo-0301.
The OpenAI model page is a good resource for up to date model information.
What must always be kept in mind is that OpenAI models are non-deterministic. This means that identical inputs and various times, even submitted sequentially, can yield varying or different results.
OpenAI states that temperature to 0 will make the outputs mostly deterministic, but a small amount of variability may remain.
The ChatGPT web interface we are all accustomed to, manages conversational context quite well…

But I hasten to stress that the ChatGPT model (gpt-3.5-turbo) accessed via the API does not manage conversational context, as is evident per the example below:

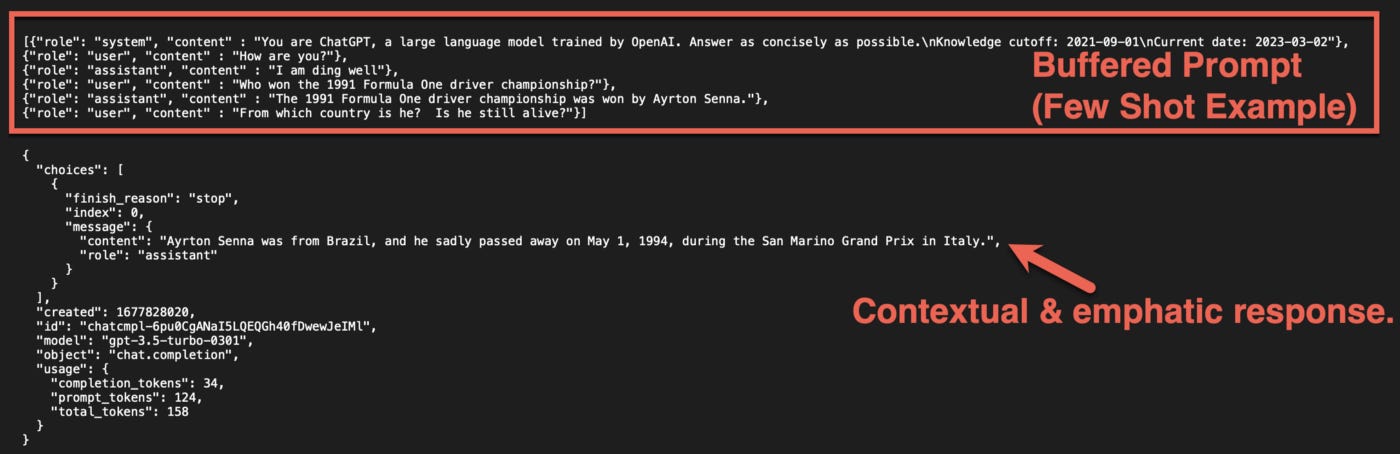
Conversational context can be maintained with a few-shot approach by buffering the prompts.
This is most probably the same way OpenAI managed context via the initial web interface.
Below is a few-shot learning prompt example in action, with a very contextual and empathetic response from the ChatGPT model:
Considering Chat Markup Langauge, below is an example ChatML JSON file with defined roles of system, user & assistant.
The main security vulnerability and avenue of abuse for LLMs has been prompt injection attacks. ChatML is aimed at protection against these types of attacks.
[{"role": "system",
"content" : "You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible.\nKnowledge cutoff: 2021-09-01\nCurrent date: 2023-03-02"},
{"role": "user",
"content" : "How are you?"},
{"role": "assistant",
"content" : "I am doing well"},
{"role": "user",
"content" : "What is the mission of the company OpenAI?"}]Let’s put the ChatML file to work in a working example where a completion request is sent to the gpt-3.5-turbo model.
Below the working Python code snippet which you can run in a Colab Notebook:
pip install openaiimport os
import openai
openai.api_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages = [{"role": "system", "content" : "You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible.\nKnowledge cutoff: 2021-09-01\nCurrent date: 2023-03-02"},
{"role": "user", "content" : "How are you?"},
{"role": "assistant", "content" : "I am doing well"},
{"role": "user", "content" : "What is the mission of the company OpenAI?"}]
)
#print(completion)
print(completion)And again below is the output from the completion request. Notice the role which is defined, the model detail which is gpt-3.5-turbo-0301 and other more.
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "The mission of OpenAI is to ensure that artificial intelligence (AI) benefits humanity as a whole, by developing and promoting friendly AI for everyone, researching and mitigating risks associated with AI, and helping shape the policy and discourse around AI.",
"role": "assistant"
}
}
],
"created": 1677751157,
"id": "chatcmpl-6pa0TlU1OFiTKpSrTRBbiGYFIl0x3",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 50,
"prompt_tokens": 84,
"total_tokens": 134
}
}OpenAI Whisper large-v2 Model
Considering accessing the OpenAI Whisper AI via a Colab Notebook:
pip install openaiimport os
import openai
openai.api_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"from google.colab import files
uploaded = files.upload()The result from uploading the MP3 audio file.
OpenAIWhisper.mp3
OpenAIWhisper.mp3(audio/mpeg) - 252672 bytes, last modified: 02/03/2023 - 100% done
Saving OpenAIWhisper.mp3 to OpenAIWhisper.mp3The lines of Python code to transcribe the audio:
file = open("OpenAIWhisper.mp3", "rb")
transcription = openai.Audio.transcribe("whisper-1", file)print(transcription)And below is the output result…
{
"text": "Hier is een opname in Afrikaans om OpenAI Whisper te toets."
}Notice that Whisper detects the language of the recording prior to transcription.
You can read more about the available Whisper models, languages and Word Error Rates (WER) here. What I find interesting is that the WER for Spanish (3) and Italian (4) are respectively best and second best. With English coming in at third with a WER of 4.2.

⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.

