Fine-Tuning LLMs With Retrieval Augmented Generation (RAG)
LlamaIndex recently published a notebook based on a study which explores Large Language Model fine-tuning with retrieval augmentation.

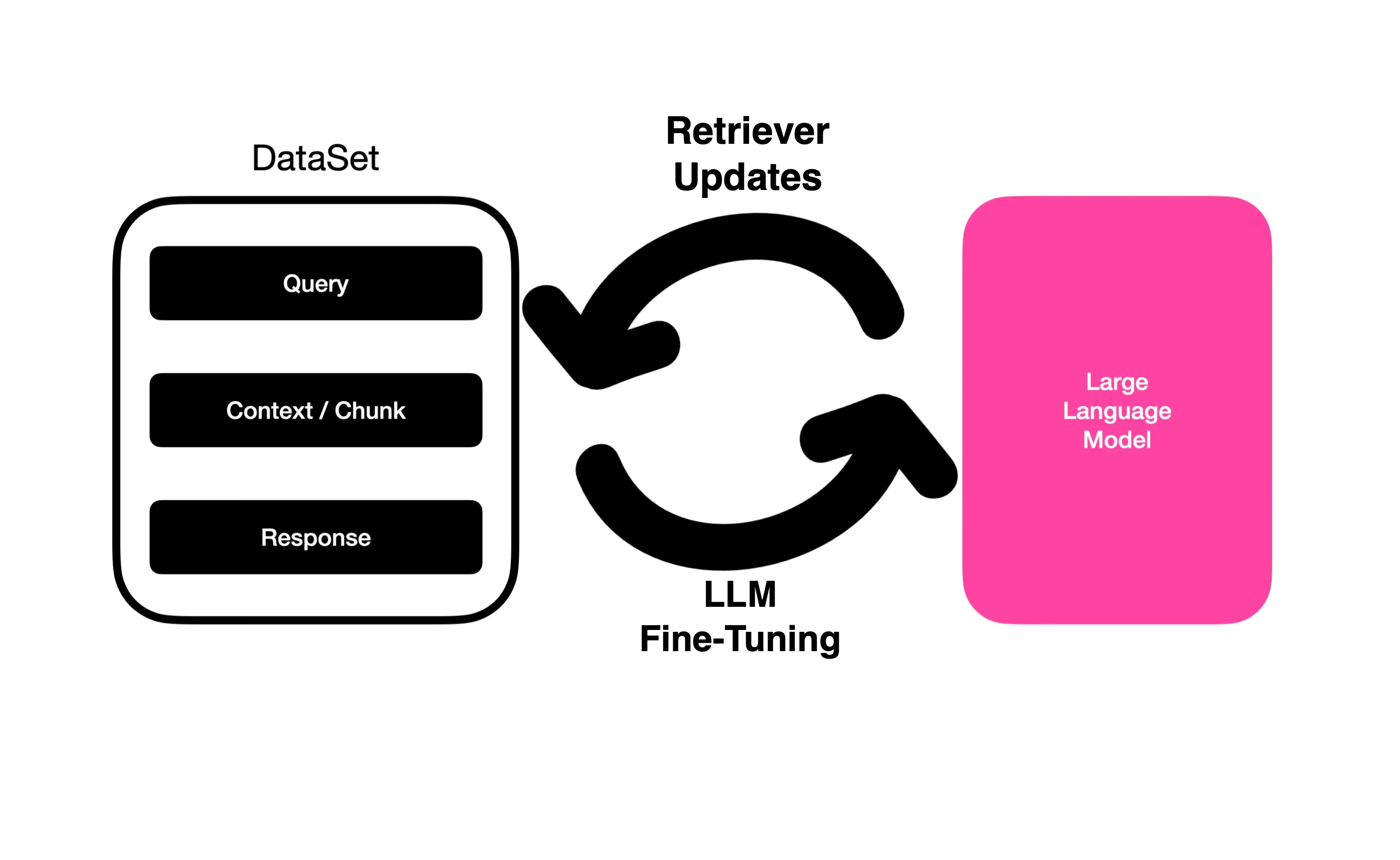
This approach is a novel implementation of RAG called RA-DIT (Retrieval Augmented Dual Instruction Tuning) where the RAG dataset (query, context retrieved and response) is used to to fine-tune a LLM. In turn retriever fine-tuning is performed via a supervised process with generated data from the LLM. The retriever training data can be generated via both supervised and unsupervised tasks, but supervision via an AI accelerated suite makes more sense.
This approach allows for the retriever to become more contextually relevant and aligned with the LLM.
The code snipped below shows how the context is fetched via a retriever for each datapoint.
from llama_index import VectorStoreIndex
from llama_index.prompts import PromptTemplate
qa_prompt_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query.\n"
"Query: {query_str}\n"
"Answer: "
)
qa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str)
vector_retriever = vector_index.as_retriever(similarity_top_k=1)And here the formatting of the training data for OpenAI’s fine-tuning endpoints.
def save_openai_data(dataset, out_path):
# out_fp = open("data_rag/qa_pairs_openai.jsonl", "w")
out_fp = open(out_path, "w")
# TODO: try with different system prompts
system_prompt = {
"role": "system",
"content": "You are a helpful assistant helping to answer questions about the Llama 2 paper.",
}
train_qr_pairs = dataset.qr_pairs
for line in train_qr_pairs:
query, response = line
user_prompt = {"role": "user", "content": query}
assistant_prompt = {"role": "assistant", "content": response}
out_dict = {
"messages": [system_prompt, user_prompt, assistant_prompt],
}
out_fp.write(json.dumps(out_dict) + "\n")
save_openai_data(train_dataset, "data_rag/qa_pairs_openai.jsonl")Fine-tuning with RAG, uses the RAG output as training data for LLM fine-tuning. And in turn the fine-tuning will teach the LLM to better interpret the use-case context.
The human-in-the-loop approach allows for a supervised approach where responses can be curated and the retriever in turn trains on this feedback.
Retrieval-augmented language models (RALMs) with human curation improve performance by addressing the long-tail of human interaction and up-to-date knowledge from external data stores.
The LLM is updated for improved use of retrieved information.
While the retriever is updated with relevant use-case examples.
This approach leads to both improved knowledge utilisation and enhanced contextual awareness.
In Conclusion
Fine-Tuning and RAG is not mutually exclusive, and using both in tandem is the ideal. Especially considering the simplicity introduced by OpenAI in terms of fine-tuning.
RA-DIT (Retrieval Augmented Dual Instruction Tuning) creates a symbiotic relationship between fine-tuning and RAG where RAG data is used for fine-tuning and in turn the retriever is updated with user data.
A human supervised process of curating data for retriever training requires an AI accelerated latent space or as HumanFirst refers to it, a natural language data productivity suite.
This dual instruction tuning approach makes for a supervised continuous improvement cycle and addresses the long-tail of user conversations.

The image above shows the RA-DIT approach which separately fine-tunes the LLM and the retriever. For a given example, the LM-ft component updates the LLM to maximise the likelihood of the correct answer given. The R-ft component updates the retriever to minimise the KL-Divergence between the retriever score distribution and the LLM preference.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.