Flows Are So Back
Also known as graph data, defined by nodes and edges, this concept is becoming increasingly relevant in the context of Agentic Applications, also referred to as AI Agents.

Traditionally, people approach development through no-code, low-code, or pro-code methods. However, when it comes to AI Agents, there’s been a notable shift toward flow or graph representations. But why is that?
Introduction
Flows are essentially a graph representation of data, a concept that has gained popularity through the use of Knowledge Graphs in Retrieval-Augmented Generation (RAG) and data representation.
Recently, graph-based approaches have also become widely used for:
Creating AI pipelines and more complex APIs
Building Agent AI tools
Defining loops and steps in Agentic Applications
Developing conversational user interfaces
Graph representations offer several advantages, including:
Visualising complex data topologies in a graphic and interconnected manner (A)
Developing flows through code while visualising nodes and edges graphically (B)
Enabling the creation and execution of nodes and edges via a no-code GUI (C)
Three Different Approaches
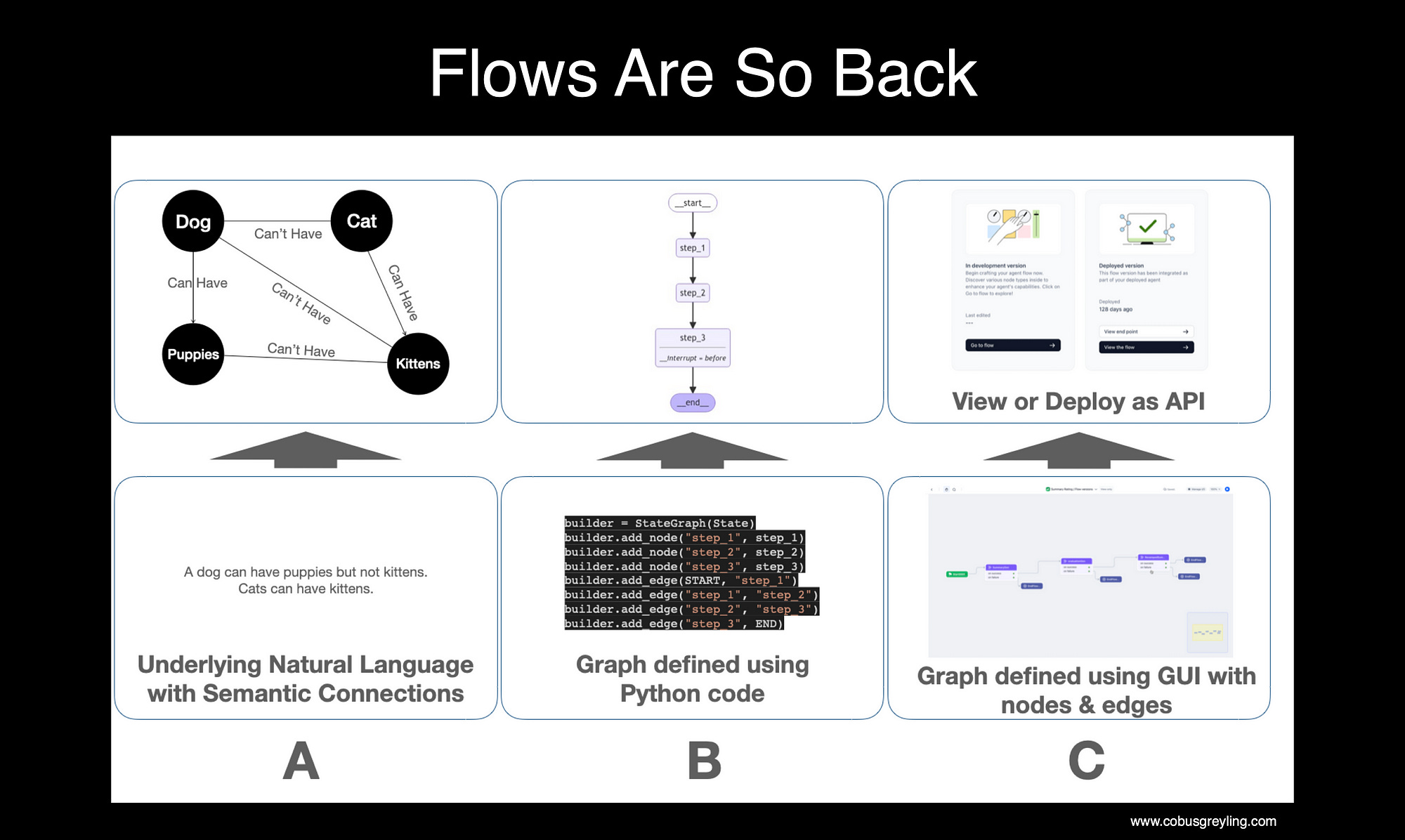
Considering the image below, there are three different approaches to leveraging a graph approach to organising data for a visual representation or a flow.
(A) Visualising complex data topologies in a graphic and interconnectedmanner allows for an intuitive understanding of intricate relationships and patterns within the data.
By representing data as nodes and edges, users can easily identify connections, dependencies, and clusters that might be difficult to discern through traditional data representations.
This approach enables a more holistic view, making it easier to analyse, explore, and make informed decisions based on the underlying structure of the data which also shows the semantic relation and similarity of data.
(B) Developing flows through code while visualising nodes and edges graphically provides a powerful way to design and manage complex systems.
This approach allows developers to write code while simultaneously seeing the logic flows in a visual format, where each node represents a specific function, task, or data point, and the edges illustrate the connections between them.
For both cases A and B, in most cases, it is not possible to change the underlying data by changing or manipulating the graphic view. There are instances where the graphic representation is merely a view, or where varying levels of data manipulation or changes are possible via the graphics.
The image below is an example from the LangChain LangGraph Studio environment, where Python code is visualised in a graphical representation.
This visual layout can be adjusted and manipulated both in terms of arrangement and execution. However, changes to the graph representation do not alter the underlying Python code directly.
When code is handcrafted and later automatically updated or refactored through a graphical UI, it often results in poorly structured code that becomes difficult, if not impossible, to maintain.
While transformations between graphical representations work seamlessly in both directions, transitioning from code to a graphic interface is typically a one-way process, with changes in the graphic view not effectively translating back into clean, maintainable code.

(C) Enabling the creation and execution of nodes and edges via a no-code GUI empowers users, including those without programming skills, to design and implement complex workflows visually.
This has been the standard approach for chatbot development frameworks, where a design canvas approach was followed in most cases.
This approach democratises development, allowing users to drag and drop components, define relationships, and configure logic directly through an intuitive interface.
By simplifying the process of building and executing workflows, it reduces the time and effort required to bring ideas to life, making it easier to iterate and refine solutions. It promotes collaboration among diverse teams, as via this approach design and development are merged.

What Makes Graph Intuitive?
In computer science, an abstract data type (ADT) serves as a mathematical model for data types, defined by its behaviour (semantics) from the user’sperspective.
This means that the ADT focuses on the possible values, operations, and behaviours that a user can expect when interacting with the data, emphasising usability and meaning. Graph representation of data is an ADT…and because semantic meaning, links and clusters are part and parcel of the Graph representation, it is so easy for us as humans to interpret this representation of data.
Graph is in start contrast with other data structures which provide concrete representations of data from the implementer’s point of view, detailing how data is structured, organised and manipulated. All dictated by elements like storage, memory, software design and the like.
And, while the implementer focuses on the technical construction and efficiency of these structures, other parties must grasp and interpret the underlying structure on their own, translating it into meaningful interactions.
Graph = User Perspective
Other Data Types = Implementers Perspective
Why I’m saying Flows Are Back
Most, if not virtually all, AI Agent and Agentic Application implementations have been developed through conversational UIs. Generative AI, particularly language models, are typically accessed via prompting — a natural language interface where input and output data are inherently unstructured.
The landscape of large language models (LLMs) is approached from two distinct perspectives. On one side, chatbot and voicebot veterans are integrating their expertise with the evolving world of generative AI and language models.
On the other side, AI and ML experts, who are new to the realm of flows and conversational UIs, are adapting to these interfaces. Flows are designed to orchestrate a sequence of events, which may involve chaining prompts or creating a pipeline of actions. These sequences can be executed with or without human intervention, depending on the application’s requirements.

Recently, Kore.ai introduced an AI Productivity Suite that offers a range of features, including the ability to select and host open-source models, integrate with commercial models, implement guardrails, and perform no-code fine-tuning, among other capabilities.
A key component of this suite is the Agent Flow Builder, which adheres to a no-code approach, enabling users to easily create and deploy flows without needing extensive coding knowledge.
This tool streamlines the process of building complex AI-driven workflows, making advanced functionality accessible to a broader audience.

Deepset also recently released a no-code Studio environment for building pipelines. Their open-sourced product called Haystack have been one of the leaders in creating generative AI / LLM pipelines to execute a whole host of tasks.
Add to this list Flowise, LangFlow, and many more…
In Conclusion
As seen below, considering the current market architecture for Large Language Models, there has been an oversupply of flow engineering tools, which allow users to design and manage individual workflows.
However, the real need lies in the development of a robust orchestration tool that can seamlessly integrate and coordinate all these disparate elements. Such an orchestration tool would provide a unified framework for managing multiple flows, models, and processes, ensuring that they work together efficiently and effectively, rather than operating in isolation.
This would address a critical gap in the market, facilitating more cohesive and scalable AI-driven solutions.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.