Hierarchical Chunking in RAG In A Quick Guide
Building Agentic RAG with Hierarchical Chunking & Scratchpad Reasoning

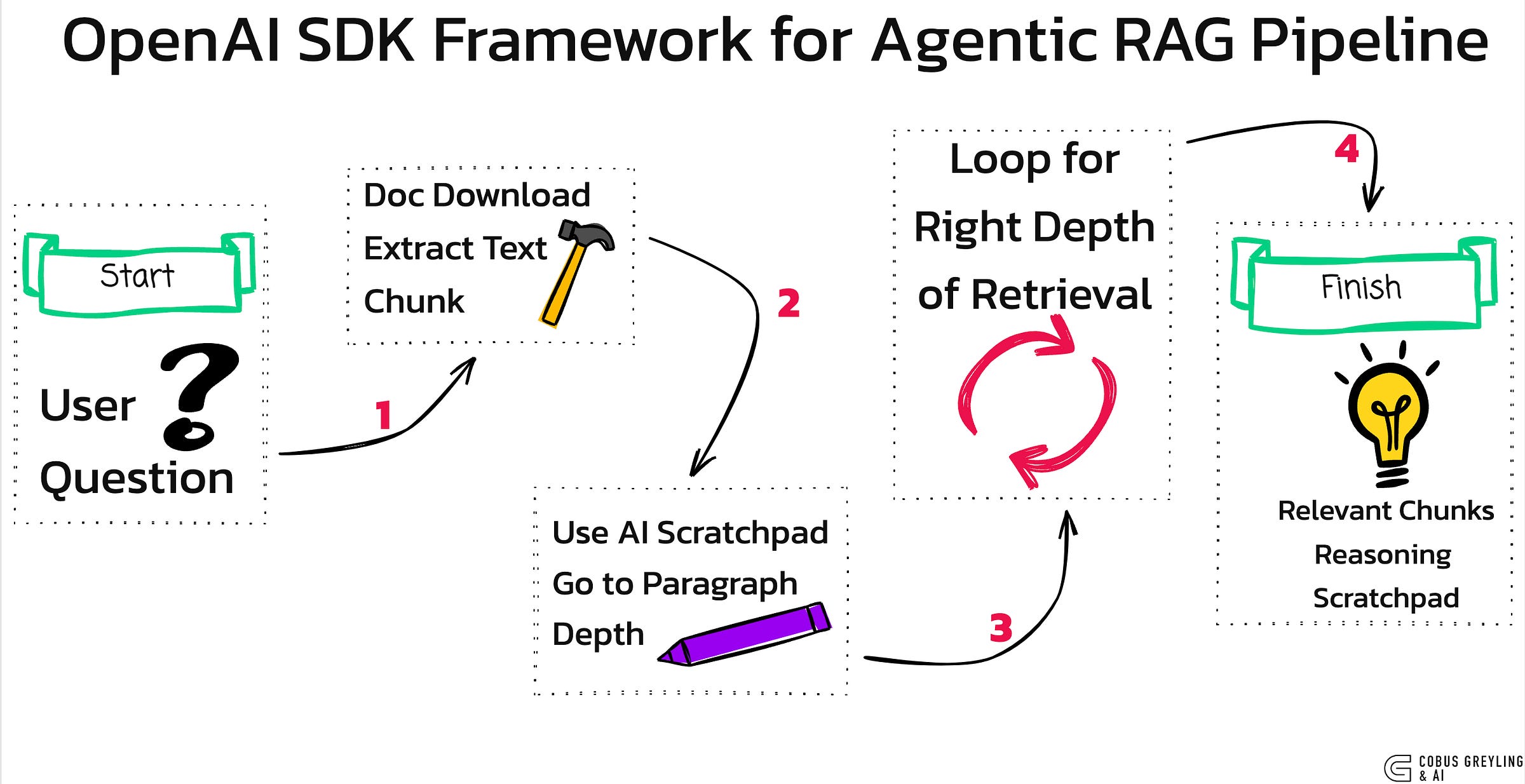
RAG systems retrieve and generate answers from large documents. The code below adds agentic traits… it autonomously navigates document chunks in a hierarchy, uses a AI scratchpad for step-by-step reasoning and refines searches iteratively.
The result is a system that acts independently to find precise answers, with the scratchpad providing memory and transparency.
In this article I try to break down the chunking process, its intelligence, model interactions, and how tools like OpenAI’’s SDK enable this setup.
There are use cases for on-the-fly chunking in RAG systems, especially in production where efficiency matters.
On-the-fly chunking means dynamically splitting documents based on the query or content, rather than pre-chunking everything upfront.
This pairs well with higher-order search, like hybrid (keyword + semantic) or multi-stage retrieval, to first select the most relevant documents or sections, then chunk them.
The Chunking Hierarchy
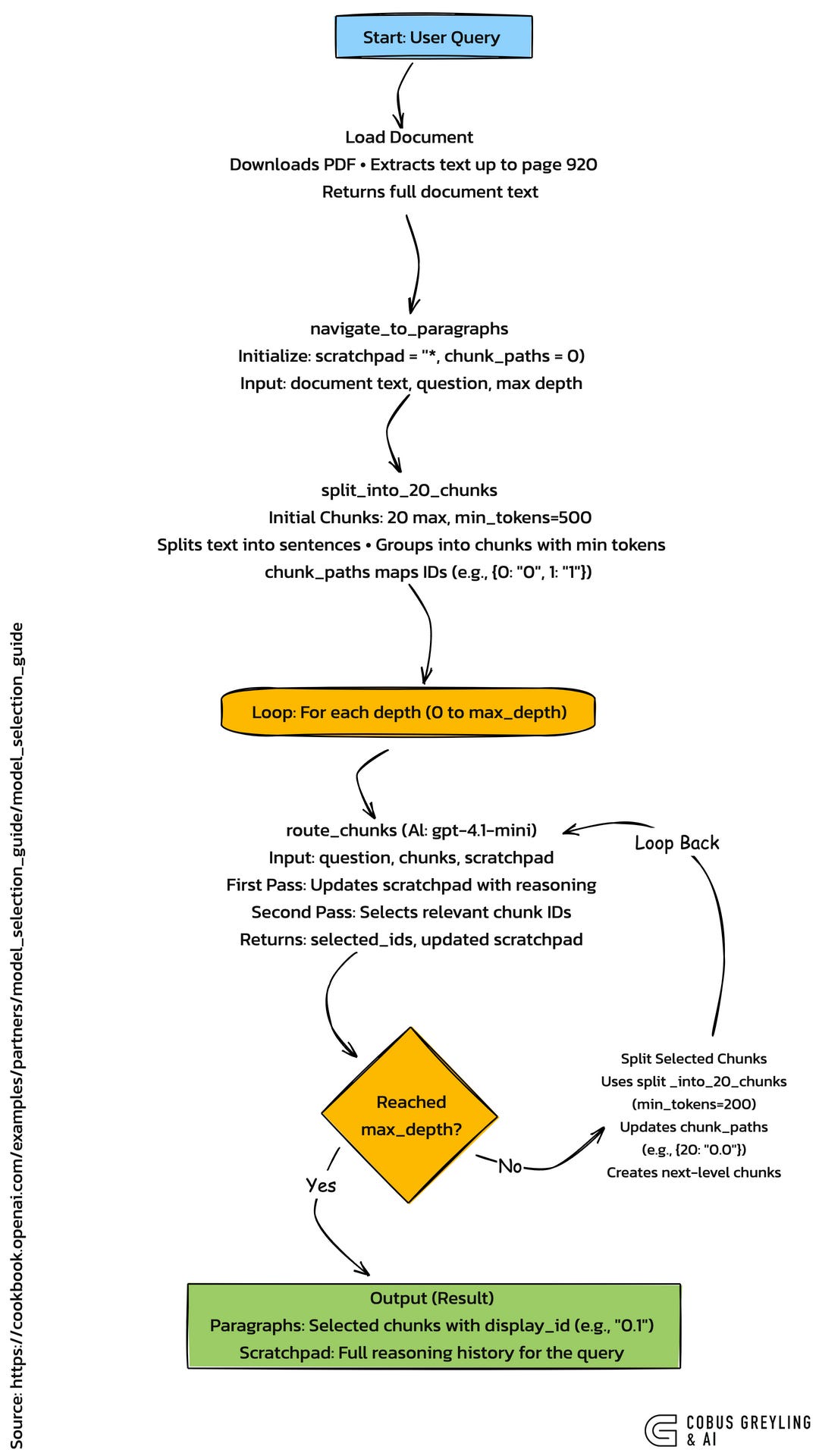
Chunking breaks a big document into smaller pieces for easier handling. In this code below with the image above shows ow it starts with the full text from the PDF, up to 920 pages.
The process uses a function called split_into_20_chunks.
It first splits the text into sentences with NLTK. Then, it groups sentences into chunks, ensuring each has at least 500 tokens (using TikToken for counting).
If a chunk gets too big (over 1000 tokens) and meets the minimum, it starts a new one.
The last chunk can be smaller.
It caps at 20 chunks. If more form, it recombines and redistributes sentences evenly into 20.
This keeps things uniform.
The hierarchy comes in during navigation.
The code runs up to depth 2.
At depth 0, it splits the document into 20 chunks (min 500 tokens).
Selected chunks get split again at depth 1 (min 200 tokens), and so on. Each sub-chunk gets an ID like “0.1” to track its parent.
This setup lets the system zoom in…
Start broad, then focus on relevant sub-parts. It respects sentence boundaries, so chunks stay coherent.
Intelligence in Chunking
The intelligence comes from the AI model picking relevant chunks. It’s not random splitting — the code uses GPT-4o-mini to evaluate.
In route_chunks, the model gets the question, chunks and scratchpad.
It must reason why chunks matter, then select IDs. It does this in two passes:
Update the scratchpad with thoughts,
Output selections as JSON.
This adds intelligence, the model thinks about the query and picks chunks that match. At deeper levels, it refines on sub-chunks.
The hierarchy builds intelligence by iterating. Depth 0 picks broad chunks; depth 1 narrows to specifics. This mimics human search: scan, then dive in.
Model Touch Points & Orchestration
The code uses one model: GPT-4o-mini.
It handles all tasks — reasoning, scratchpad updates & chunk picks. Touch points are in route_chunks: system prompt for instructions, user message with query and chunks, tool for scratchpad, and structured output for IDs.
No multiple models orchestration . It’s single-model for simplicity. But you can orchestrate multiples for better results.
For example:
Use an embeddings model (like OpenAI’s
text-embedding-ada-002) to vectorise chunks and query for quick similarity search. This pre-filters before the main model.A ranking model could score chunks post-retrieval.
Orchestrate with a larger model (
GPT-4o) for final generation, while using mini for selection.
In this code, it’s basic: one model does it all. Adding multiples cuts costs (mini for light tasks) and boosts accuracy.
The Scratchpad
The scratchpad is a string that logs the model’s reasoning. It starts empty per query.
In route_chunks, the model must use a tool to write thoughts). It adds “DEPTH X REASONING” entries.
It serves two roles:
Gives users insight into decisions, and
Lets the model reference past thoughts in later depths.
For example, depth 0 notes guide depth 1 picks.
It’s query-specific — resets for each new question. This keeps focus but could be extended for multi-query chats.
Why OpenAI Makes These Available
Leading language model providers, such as OpenAI, are expanding into application development to enhance user engagement through SDKs and streamlined code frameworks.
As model capabilities grow — showing advanced features like vision and computer interaction — there is a critical need for intuitive frameworks to effectively showcase and integrate these functionalities.
The frameworks also enable providers to simplify prototyping and offer scalable scaffolding for creating impactful demos.
Coming to a close…
This RAG setup shows smart chunking, which hierarchical splits with AI selection for targeted answers.
Single-model now, but future orchestration can and performance.
The scratchpad tracks thoughts simply and surfaces it at the end.
OpenAI’s tools lower barriers, making advanced AI practical.
If building similar systems, start with basics and layer on models for efficiency.
The working code:
%pip install tiktoken pypdf nltk openai pydantic --quiet
################################
import requests
from io import BytesIO
from pypdf import PdfReader
import re
import tiktoken
from nltk.tokenize import sent_tokenize
import nltk
from typing import List, Dict, Any
# Download nltk data if not already present
nltk.download('punkt_tab')
def load_document(url: str) -> str:
"""Load a document from a URL and return its text content."""
print(f"Downloading document from {url}...")
response = requests.get(url)
response.raise_for_status()
pdf_bytes = BytesIO(response.content)
pdf_reader = PdfReader(pdf_bytes)
full_text = ""
max_page = 920 # Page cutoff before section 1000 (Interferences)
for i, page in enumerate(pdf_reader.pages):
if i >= max_page:
break
full_text += page.extract_text() + "\n"
# Count words and tokens
word_count = len(re.findall(r'\b\w+\b', full_text))
tokenizer = tiktoken.get_encoding("o200k_base")
token_count = len(tokenizer.encode(full_text))
print(f"Document loaded: {len(pdf_reader.pages)} pages, {word_count} words, {token_count} tokens")
return full_text
# Load the document
tbmp_url = "https://www.uspto.gov/sites/default/files/documents/tbmp-Master-June2024.pdf"
document_text = load_document(tbmp_url)
# Show the first 500 characters
print("\nDocument preview (first 500 chars):")
print("-" * 50)
print(document_text[:500])
print("-" * 50)
################################
[nltk_data] Downloading package punkt_tab to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt_tab.zip.
Downloading document from https://www.uspto.gov/sites/default/files/documents/tbmp-Master-June2024.pdf...
Document loaded: 1194 pages, 595197 words, 932964 tokens
Document preview (first 500 chars):
--------------------------------------------------
TRADEMARK TRIAL AND
APPEAL BOARD MANUAL
OF PROCEDURE (TBMP)
June 2024
June 2024
United States Patent and Trademark Office
PREFACE TO THE JUNE 2024 REVISION
The June 2024 revision of the Trademark Trial and Appeal Board Manual of Procedure is an update of the
June 2023 edition. This update is moderate in nature and incorporates relevant case law issued between March
3, 2023 and March 1, 2024.
The title of the manual is abbreviated as “TBMP.” A citation to a section of the manual may be written
--------------------------------------------------# Global tokenizer name to use consistently throughout the code
TOKENIZER_NAME = "o200k_base"
def split_into_20_chunks(text: str, min_tokens: int = 500) -> List[Dict[str, Any]]:
"""
Split text into up to 20 chunks, respecting sentence boundaries and ensuring
each chunk has at least min_tokens (unless it's the last chunk).
Args:
text: The text to split
min_tokens: The minimum number of tokens per chunk (default: 500)
Returns:
A list of dictionaries where each dictionary has:
- id: The chunk ID (0-19)
- text: The chunk text content
"""
# First, split the text into sentences
sentences = sent_tokenize(text)
# Get tokenizer for counting tokens
tokenizer = tiktoken.get_encoding(TOKENIZER_NAME)
# Create chunks that respect sentence boundaries and minimum token count
chunks = []
current_chunk_sentences = []
current_chunk_tokens = 0
for sentence in sentences:
# Count tokens in this sentence
sentence_tokens = len(tokenizer.encode(sentence))
# If adding this sentence would make the chunk too large AND we already have the minimum tokens,
# finalize the current chunk and start a new one
if (current_chunk_tokens + sentence_tokens > min_tokens * 2) and current_chunk_tokens >= min_tokens:
chunk_text = " ".join(current_chunk_sentences)
chunks.append({
"id": len(chunks), # Integer ID instead of string
"text": chunk_text
})
current_chunk_sentences = [sentence]
current_chunk_tokens = sentence_tokens
else:
# Add this sentence to the current chunk
current_chunk_sentences.append(sentence)
current_chunk_tokens += sentence_tokens
# Add the last chunk if there's anything left
if current_chunk_sentences:
chunk_text = " ".join(current_chunk_sentences)
chunks.append({
"id": len(chunks), # Integer ID instead of string
"text": chunk_text
})
# If we have more than 20 chunks, consolidate them
if len(chunks) > 20:
# Recombine all text
all_text = " ".join(chunk["text"] for chunk in chunks)
# Re-split into exactly 20 chunks, without minimum token requirement
sentences = sent_tokenize(all_text)
sentences_per_chunk = len(sentences) // 20 + (1 if len(sentences) % 20 > 0 else 0)
chunks = []
for i in range(0, len(sentences), sentences_per_chunk):
# Get the sentences for this chunk
chunk_sentences = sentences[i:i+sentences_per_chunk]
# Join the sentences into a single text
chunk_text = " ".join(chunk_sentences)
# Create a chunk object with ID and text
chunks.append({
"id": len(chunks), # Integer ID instead of string
"text": chunk_text
})
# Print chunk statistics
print(f"Split document into {len(chunks)} chunks")
for i, chunk in enumerate(chunks):
token_count = len(tokenizer.encode(chunk["text"]))
print(f"Chunk {i}: {token_count} tokens")
return chunks
# Split the document into 20 chunks with minimum token size
import os
# Set the API key as an environment variable
os.environ['API_KEY'] = 'your-api-key-here'document_chunks = split_into_20_chunks(document_text, min_tokens=500)Chunk processing..
Split document into 20 chunks
Chunk 0: 42326 tokens
Chunk 1: 42093 tokens
Chunk 2: 42107 tokens
Chunk 3: 39797 tokens
Chunk 4: 58959 tokens
Chunk 5: 48805 tokens
Chunk 6: 37243 tokens
Chunk 7: 33453 tokens
Chunk 8: 38644 tokens
Chunk 9: 49402 tokens
Chunk 10: 51568 tokens
Chunk 11: 49586 tokens
Chunk 12: 47722 tokens
Chunk 13: 48952 tokens
Chunk 14: 44994 tokens
Chunk 15: 50286 tokens
Chunk 16: 54424 tokens
Chunk 17: 62651 tokens
Chunk 18: 47430 tokens
Chunk 19: 42507 tokensimport os
# Set the API key as an environment variable
os.environ['OPENAI_API_KEY'] = '<Your API Key>'from openai import OpenAI
import json
from typing import List, Dict, Any
# Initialize OpenAI client
client = OpenAI()
def route_chunks(question: str, chunks: List[Dict[str, Any]],
depth: int, scratchpad: str = "") -> Dict[str, Any]:
"""
Ask the model which chunks contain information relevant to the question.
Maintains a scratchpad for the model's reasoning.
Uses structured output for chunk selection and required tool calls for scratchpad.
Args:
question: The user's question
chunks: List of chunks to evaluate
depth: Current depth in the navigation hierarchy
scratchpad: Current scratchpad content
Returns:
Dictionary with selected IDs and updated scratchpad
"""
print(f"\n==== ROUTING AT DEPTH {depth} ====")
print(f"Evaluating {len(chunks)} chunks for relevance")
# Build system message
system_message = """You are an expert document navigator. Your task is to:
1. Identify which text chunks might contain information to answer the user's question
2. Record your reasoning in a scratchpad for later reference
3. Choose chunks that are most likely relevant. Be selective, but thorough. Choose as many chunks as you need to answer the question, but avoid selecting too many.
First think carefully about what information would help answer the question, then evaluate each chunk.
"""
# Build user message with chunks and current scratchpad
user_message = f"QUESTION: {question}\n\n"
if scratchpad:
user_message += f"CURRENT SCRATCHPAD:\n{scratchpad}\n\n"
user_message += "TEXT CHUNKS:\n\n"
# Add each chunk to the message
for chunk in chunks:
user_message += f"CHUNK {chunk['id']}:\n{chunk['text']}\n\n"
# Define function schema for scratchpad tool calling
tools = [
{
"type": "function",
"name": "update_scratchpad",
"description": "Record your reasoning about why certain chunks were selected",
"strict": True,
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "Your reasoning about the chunk(s) selection"
}
},
"required": ["text"],
"additionalProperties": False
}
}
]
# Define JSON schema for structured output (selected chunks)
text_format = {
"format": {
"type": "json_schema",
"name": "selected_chunks",
"strict": True,
"schema": {
"type": "object",
"properties": {
"chunk_ids": {
"type": "array",
"items": {"type": "integer"},
"description": "IDs of the selected chunks that contain information to answer the question"
}
},
"required": [
"chunk_ids"
],
"additionalProperties": False
}
}
}
# First pass: Call the model to update scratchpad (required tool call)
messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": user_message + "\n\nFirst, you must use the update_scratchpad function to record your reasoning."}
]
response = client.responses.create(
model="gpt-4.1-mini",
input=messages,
tools=tools,
tool_choice="required"
)
# Process the scratchpad tool call
new_scratchpad = scratchpad
for tool_call in response.output:
if tool_call.type == "function_call" and tool_call.name == "update_scratchpad":
args = json.loads(tool_call.arguments)
scratchpad_entry = f"DEPTH {depth} REASONING:\n{args.get('text', '')}"
if new_scratchpad:
new_scratchpad += "\n\n" + scratchpad_entry
else:
new_scratchpad = scratchpad_entry
# Add function call and result to messages
messages.append(tool_call)
messages.append({
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": "Scratchpad updated successfully."
})
# Second pass: Get structured output for chunk selection
messages.append({"role": "user", "content": "Now, select the chunks that could contain information to answer the question. Return a JSON object with the list of chunk IDs."})
response_chunks = client.responses.create(
model="gpt-4.1-mini",
input=messages,
text=text_format
)
# Extract selected chunk IDs from structured output
selected_ids = []
if response_chunks.output_text:
try:
# The output_text should already be in JSON format due to the schema
chunk_data = json.loads(response_chunks.output_text)
selected_ids = chunk_data.get("chunk_ids", [])
except json.JSONDecodeError:
print("Warning: Could not parse structured output as JSON")
# Display results
print(f"Selected chunks: {', '.join(str(id) for id in selected_ids)}")
print(f"Updated scratchpad:\n{new_scratchpad}")
return {
"selected_ids": selected_ids,
"scratchpad": new_scratchpad
}def navigate_to_paragraphs(document_text: str, question: str, max_depth: int = 1) -> Dict[str, Any]:
"""
Navigate through the document hierarchy to find relevant paragraphs.
Args:
document_text: The full document text
question: The user's question
max_depth: Maximum depth to navigate before returning paragraphs (default: 1)
Returns:
Dictionary with selected paragraphs and final scratchpad
"""
scratchpad = ""
# Get initial chunks with min 500 tokens
chunks = split_into_20_chunks(document_text, min_tokens=500)
# Navigator state - track chunk paths to maintain hierarchy
chunk_paths = {} # Maps numeric IDs to path strings for display
for chunk in chunks:
chunk_paths[chunk["id"]] = str(chunk["id"])
# Navigate through levels until max_depth or until no chunks remain
for current_depth in range(max_depth + 1):
# Call router to get relevant chunks
result = route_chunks(question, chunks, current_depth, scratchpad)
# Update scratchpad
scratchpad = result["scratchpad"]
# Get selected chunks
selected_ids = result["selected_ids"]
selected_chunks = [c for c in chunks if c["id"] in selected_ids]
# If no chunks were selected, return empty result
if not selected_chunks:
print("\nNo relevant chunks found.")
return {"paragraphs": [], "scratchpad": scratchpad}
# If we've reached max_depth, return the selected chunks
if current_depth == max_depth:
print(f"\nReturning {len(selected_chunks)} relevant chunks at depth {current_depth}")
# Update display IDs to show hierarchy
for chunk in selected_chunks:
chunk["display_id"] = chunk_paths[chunk["id"]]
return {"paragraphs": selected_chunks, "scratchpad": scratchpad}
# Prepare next level by splitting selected chunks further
next_level_chunks = []
next_chunk_id = 0 # Counter for new chunks
for chunk in selected_chunks:
# Split this chunk into smaller pieces
sub_chunks = split_into_20_chunks(chunk["text"], min_tokens=200)
# Update IDs and maintain path mapping
for sub_chunk in sub_chunks:
path = f"{chunk_paths[chunk['id']]}.{sub_chunk['id']}"
sub_chunk["id"] = next_chunk_id
chunk_paths[next_chunk_id] = path
next_level_chunks.append(sub_chunk)
next_chunk_id += 1
# Update chunks for next iteration
chunks = next_level_chunks# Run the navigation for a sample question
question = "What format should a motion to compel discovery be filed in? How should signatures be handled?"
navigation_result = navigate_to_paragraphs(document_text, question, max_depth=2)
# Sample retrieved paragraph
print("\n==== FIRST 3 RETRIEVED PARAGRAPHS ====")
for i, paragraph in enumerate(navigation_result["paragraphs"][:3]):
display_id = paragraph.get("display_id", str(paragraph["id"]))
print(f"\nPARAGRAPH {i+1} (ID: {display_id}):")
print("-" * 40)
print(paragraph["text"])
print("-" * 40)The raw output of the code (chunk texts with IDs and scratchpad) is functional but technical and fragmented.
A second pass with a Language Model, using the OpenAI SDK, can synthesise and polish the response, making it concise, cohesive and user-friendly.
This leverages the existing chunking and scratchpad mechanisms while addressing the need for a presentation layer.
Split document into 20 chunks
Chunk 0: 42326 tokens
Chunk 1: 42093 tokens
Chunk 2: 42107 tokens
Chunk 3: 39797 tokens
Chunk 4: 58959 tokens
Chunk 5: 48805 tokens
Chunk 6: 37243 tokens
Chunk 7: 33453 tokens
Chunk 8: 38644 tokens
Chunk 9: 49402 tokens
Chunk 10: 51568 tokens
Chunk 11: 49586 tokens
Chunk 12: 47722 tokens
Chunk 13: 48952 tokens
Chunk 14: 44994 tokens
Chunk 15: 50286 tokens
Chunk 16: 54424 tokens
Chunk 17: 62651 tokens
Chunk 18: 47430 tokens
Chunk 19: 42507 tokens
==== ROUTING AT DEPTH 0 ====
Evaluating 20 chunks for relevance
Selected chunks: 0, 5, 10, 12
Updated scratchpad:
DEPTH 0 REASONING:
The user's question concerns the format and signature requirements for a motion to compel discovery in Trademark Trial and Appeal Board proceedings.
The relevant information would likely be found in sections discussing motions, service of papers, signature requirements, and the form of submissions and motions in TBMP. Most applicable sections are in chunks discussing general procedure (chunk 0), motions (chunks 10, 11, 12), signatures and service (chunk 0, 5), and discovery (chunks 4, 5, 6, 7, 8, 9).
Specific focus should be on:
- 37 C.F.R. rules cited in the text for motions and service.
- Signature requirements for filing motions (chunk 0 especially § 106.02).
- Service requirements and certificate of service for motions (chunk 0 § 113 and chunk 5).
- Form of motions and briefs including page limit and format rules (chunk 10 and 12).
- Motion to compel filing requirements and motion content requirements (chunk 12 § 523).
- Discovery rules concerning motions to compel (chunks 4,5,6,7,8,9).
- Special motions content in TBMP chapters 500 and 520.
I will select excerpts from these chunks that cover the above areas to answer the question about the appropriate format and signature handling for a motion to compel discovery.
Split document into 20 chunks
Chunk 0: 3539 tokens
Chunk 1: 2232 tokens
Chunk 2: 1746 tokens
Chunk 3: 3078 tokens
Chunk 4: 1649 tokens
Chunk 5: 2779 tokens
Chunk 6: 2176 tokens
Chunk 7: 1667 tokens
Chunk 8: 1950 tokens
Chunk 9: 1730 tokens
Chunk 10: 1590 tokens
Chunk 11: 1964 tokens
Chunk 12: 1459 tokens
Chunk 13: 2070 tokens
Chunk 14: 2422 tokens
Chunk 15: 1976 tokens
Chunk 16: 2335 tokens
Chunk 17: 2694 tokens
Chunk 18: 2282 tokens
Chunk 19: 982 tokens
Split document into 20 chunks
Chunk 0: 1468 tokens
Chunk 1: 1946 tokens
Chunk 2: 2020 tokens
Chunk 3: 3384 tokens
Chunk 4: 2458 tokens
Chunk 5: 3535 tokens
Chunk 6: 3059 tokens
Chunk 7: 2027 tokens
Chunk 8: 2417 tokens
Chunk 9: 2772 tokens
Chunk 10: 1913 tokens
Chunk 11: 2674 tokens
Chunk 12: 2131 tokens
Chunk 13: 1409 tokens
Chunk 14: 3256 tokens
Chunk 15: 2827 tokens
Chunk 16: 2547 tokens
Chunk 17: 4187 tokens
Chunk 18: 1527 tokens
Chunk 19: 1246 tokens
Split document into 20 chunks
Chunk 0: 2743 tokens
Chunk 1: 4298 tokens
Chunk 2: 4270 tokens
Chunk 3: 2640 tokens
Chunk 4: 2143 tokens
Chunk 5: 1217 tokens
Chunk 6: 2100 tokens
Chunk 7: 1814 tokens
Chunk 8: 2445 tokens
Chunk 9: 2303 tokens
Chunk 10: 2086 tokens
Chunk 11: 3101 tokens
Chunk 12: 2921 tokens
Chunk 13: 2326 tokens
Chunk 14: 1985 tokens
Chunk 15: 2473 tokens
Chunk 16: 1891 tokens
Chunk 17: 1881 tokens
Chunk 18: 3833 tokens
Chunk 19: 3099 tokens
Split document into 20 chunks
Chunk 0: 1630 tokens
Chunk 1: 2311 tokens
Chunk 2: 2362 tokens
Chunk 3: 3294 tokens
Chunk 4: 2576 tokens
Chunk 5: 2645 tokens
Chunk 6: 2378 tokens
Chunk 7: 2055 tokens
Chunk 8: 1843 tokens
Chunk 9: 1999 tokens
Chunk 10: 2540 tokens
Chunk 11: 3064 tokens
Chunk 12: 1892 tokens
Chunk 13: 3698 tokens
Chunk 14: 2071 tokens
Chunk 15: 2685 tokens
Chunk 16: 1838 tokens
Chunk 17: 2729 tokens
Chunk 18: 2252 tokens
Chunk 19: 1856 tokens
==== ROUTING AT DEPTH 1 ====
Evaluating 80 chunks for relevance
Selected chunks: 5, 6, 7, 8, 9, 44, 45, 46, 47, 523, 524, 525, 526, 527, 65, 66, 67, 68, 69, 70, 71, 72, 73
Updated scratchpad:
DEPTH 0 REASONING:
The user's question concerns the format and signature requirements for a motion to compel discovery in Trademark Trial and Appeal Board proceedings.
The relevant information would likely be found in sections discussing motions, service of papers, signature requirements, and the form of submissions and motions in TBMP. Most applicable sections are in chunks discussing general procedure (chunk 0), motions (chunks 10, 11, 12), signatures and service (chunk 0, 5), and discovery (chunks 4, 5, 6, 7, 8, 9).
Specific focus should be on:
- 37 C.F.R. rules cited in the text for motions and service.
- Signature requirements for filing motions (chunk 0 especially § 106.02).
- Service requirements and certificate of service for motions (chunk 0 § 113 and chunk 5).
- Form of motions and briefs including page limit and format rules (chunk 10 and 12).
- Motion to compel filing requirements and motion content requirements (chunk 12 § 523).
- Discovery rules concerning motions to compel (chunks 4,5,6,7,8,9).
- Special motions content in TBMP chapters 500 and 520.
I will select excerpts from these chunks that cover the above areas to answer the question about the appropriate format and signature handling for a motion to compel discovery.
DEPTH 1 REASONING:
The user's question concerns the format and signature requirements for a motion to compel discovery in Trademark Trial and Appeal Board (TTAB) proceedings. Relevant information likely lies in sections on motions, particularly motions to compel discovery, signature and form of submissions, service of papers and certificates of service, discovery procedures, and filing requirements.
Chunk 5, 6, 7, 8, 9, 44, 45, 46, and 47 provide detailed information about form and signature of submissions, including motions, their filing via ESTTA, paper filing exceptions, signatures including electronic signatures, service requirements, certificates of service and mailing, length, and formatting.
Chunks 523, 524, 525, 526, 527 (including 65 to 73) discuss motions to compel discovery, special requirements for motions to compel, time for filing motions to compel discovery, failure to file a motion to compel, motion to test sufficiency of responses to requests for admission, motion to withdraw or amend admissions, motion for protective orders, and sanctions available. These chunks directly address the substance, procedural requirements, and deadlines for motions to compel discovery and handling responses.
Chunks 502 and its subparts detail the general rules and form for motions and briefs, including motions to compel discovery. These include page limits, brief timing, written form and ESTTA filing requirements, service, and relation to confidential information.
The June 2024 TBMP text mostly describes ESTTA filing requirements, signature requirements (§106.02), certificate of service (§113 and related), service by email, and motions to compel discovery content and timing (§523 series).
Therefore, to answer the question about the format for a motion to compel discovery and signature rules, broadly the relevant information spans from the early Chapters about signatures (chunks 5-7), the rules on submission format and service (chunks 8, 9, 44-47), and the detailed discussion of motions to compel discovery and related service and certificates rules (chunks 523-527, including 65-73 and the associated notes). Also relevant is chunk 502 for the general format and filing rules for motions.
Hence, I will select the following chunks for detailed answer: 5, 6, 7, 8, 9, 44, 45, 46, 47, 523, 524, 525, 526, 527, and the note appendix chunks 65-73. I will also consider chunk 502 for form of motions and briefs.
Split document into 8 chunks
Chunk 0: 398 tokens
Chunk 1: 256 tokens
Chunk 2: 389 tokens
Chunk 3: 356 tokens
Chunk 4: 401 tokens
Chunk 5: 277 tokens
Chunk 6: 435 tokens
Chunk 7: 265 tokens
Split document into 6 chunks
Chunk 0: 353 tokens
Chunk 1: 393 tokens
Chunk 2: 388 tokens
Chunk 3: 398 tokens
Chunk 4: 397 tokens
Chunk 5: 247 tokens
Split document into 5 chunks
Chunk 0: 325 tokens
Chunk 1: 389 tokens
Chunk 2: 303 tokens
Chunk 3: 344 tokens
Chunk 4: 306 tokens
Split document into 6 chunks
Chunk 0: 380 tokens
Chunk 1: 396 tokens
Chunk 2: 384 tokens
Chunk 3: 368 tokens
Chunk 4: 208 tokens
Chunk 5: 215 tokens
Split document into 5 chunks
Chunk 0: 342 tokens
Chunk 1: 349 tokens
Chunk 2: 402 tokens
Chunk 3: 376 tokens
Chunk 4: 261 tokens
Split document into 6 chunks
Chunk 0: 292 tokens
Chunk 1: 329 tokens
Chunk 2: 388 tokens
Chunk 3: 392 tokens
Chunk 4: 356 tokens
Chunk 5: 386 tokens
Split document into 4 chunks
Chunk 0: 407 tokens
Chunk 1: 390 tokens
Chunk 2: 380 tokens
Chunk 3: 40 tokens
Split document into 6 chunks
Chunk 0: 400 tokens
Chunk 1: 342 tokens
Chunk 2: 398 tokens
Chunk 3: 361 tokens
Chunk 4: 349 tokens
Chunk 5: 249 tokens
Split document into 5 chunks
Chunk 0: 385 tokens
Chunk 1: 387 tokens
Chunk 2: 341 tokens
Chunk 3: 376 tokens
Chunk 4: 325 tokens
Split document into 8 chunks
Chunk 0: 400 tokens
Chunk 1: 272 tokens
Chunk 2: 321 tokens
Chunk 3: 387 tokens
Chunk 4: 388 tokens
Chunk 5: 381 tokens
Chunk 6: 348 tokens
Chunk 7: 148 tokens
Split document into 7 chunks
Chunk 0: 359 tokens
Chunk 1: 354 tokens
Chunk 2: 362 tokens
Chunk 3: 376 tokens
Chunk 4: 357 tokens
Chunk 5: 370 tokens
Chunk 6: 200 tokens
Split document into 6 chunks
Chunk 0: 366 tokens
Chunk 1: 265 tokens
Chunk 2: 370 tokens
Chunk 3: 379 tokens
Chunk 4: 388 tokens
Chunk 5: 286 tokens
Split document into 5 chunks
Chunk 0: 384 tokens
Chunk 1: 359 tokens
Chunk 2: 372 tokens
Chunk 3: 372 tokens
Chunk 4: 356 tokens
Split document into 6 chunks
Chunk 0: 369 tokens
Chunk 1: 397 tokens
Chunk 2: 237 tokens
Chunk 3: 401 tokens
Chunk 4: 380 tokens
Chunk 5: 215 tokens
Split document into 7 chunks
Chunk 0: 398 tokens
Chunk 1: 391 tokens
Chunk 2: 300 tokens
Chunk 3: 336 tokens
Chunk 4: 377 tokens
Chunk 5: 371 tokens
Chunk 6: 367 tokens
Split document into 9 chunks
Chunk 0: 376 tokens
Chunk 1: 356 tokens
Chunk 2: 386 tokens
Chunk 3: 385 tokens
Chunk 4: 254 tokens
Chunk 5: 381 tokens
Chunk 6: 392 tokens
Chunk 7: 250 tokens
Chunk 8: 283 tokens
Split document into 5 chunks
Chunk 0: 388 tokens
Chunk 1: 367 tokens
Chunk 2: 364 tokens
Chunk 3: 398 tokens
Chunk 4: 376 tokens
Split document into 10 chunks
Chunk 0: 675 tokens
Chunk 1: 358 tokens
Chunk 2: 397 tokens
Chunk 3: 248 tokens
Chunk 4: 385 tokens
Chunk 5: 395 tokens
Chunk 6: 353 tokens
Chunk 7: 399 tokens
Chunk 8: 272 tokens
Chunk 9: 212 tokens
==== ROUTING AT DEPTH 2 ====
Evaluating 114 chunks for relevance
Selected chunks: 4, 5, 6, 7, 8, 9, 10, 11, 12, 31, 32, 33, 34, 35, 36, 37, 38, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64
Updated scratchpad:
DEPTH 0 REASONING:
The user's question concerns the format and signature requirements for a motion to compel discovery in Trademark Trial and Appeal Board proceedings.
The relevant information would likely be found in sections discussing motions, service of papers, signature requirements, and the form of submissions and motions in TBMP. Most applicable sections are in chunks discussing general procedure (chunk 0), motions (chunks 10, 11, 12), signatures and service (chunk 0, 5), and discovery (chunks 4, 5, 6, 7, 8, 9).
Specific focus should be on:
- 37 C.F.R. rules cited in the text for motions and service.
- Signature requirements for filing motions (chunk 0 especially § 106.02).
- Service requirements and certificate of service for motions (chunk 0 § 113 and chunk 5).
- Form of motions and briefs including page limit and format rules (chunk 10 and 12).
- Motion to compel filing requirements and motion content requirements (chunk 12 § 523).
- Discovery rules concerning motions to compel (chunks 4,5,6,7,8,9).
- Special motions content in TBMP chapters 500 and 520.
I will select excerpts from these chunks that cover the above areas to answer the question about the appropriate format and signature handling for a motion to compel discovery.
DEPTH 1 REASONING:
The user's question concerns the format and signature requirements for a motion to compel discovery in Trademark Trial and Appeal Board (TTAB) proceedings. Relevant information likely lies in sections on motions, particularly motions to compel discovery, signature and form of submissions, service of papers and certificates of service, discovery procedures, and filing requirements.
Chunk 5, 6, 7, 8, 9, 44, 45, 46, and 47 provide detailed information about form and signature of submissions, including motions, their filing via ESTTA, paper filing exceptions, signatures including electronic signatures, service requirements, certificates of service and mailing, length, and formatting.
Chunks 523, 524, 525, 526, 527 (including 65 to 73) discuss motions to compel discovery, special requirements for motions to compel, time for filing motions to compel discovery, failure to file a motion to compel, motion to test sufficiency of responses to requests for admission, motion to withdraw or amend admissions, motion for protective orders, and sanctions available. These chunks directly address the substance, procedural requirements, and deadlines for motions to compel discovery and handling responses.
Chunks 502 and its subparts detail the general rules and form for motions and briefs, including motions to compel discovery. These include page limits, brief timing, written form and ESTTA filing requirements, service, and relation to confidential information.
The June 2024 TBMP text mostly describes ESTTA filing requirements, signature requirements (§106.02), certificate of service (§113 and related), service by email, and motions to compel discovery content and timing (§523 series).
Therefore, to answer the question about the format for a motion to compel discovery and signature rules, broadly the relevant information spans from the early Chapters about signatures (chunks 5-7), the rules on submission format and service (chunks 8, 9, 44-47), and the detailed discussion of motions to compel discovery and related service and certificates rules (chunks 523-527, including 65-73 and the associated notes). Also relevant is chunk 502 for the general format and filing rules for motions.
Hence, I will select the following chunks for detailed answer: 5, 6, 7, 8, 9, 44, 45, 46, 47, 523, 524, 525, 526, 527, and the note appendix chunks 65-73. I will also consider chunk 502 for form of motions and briefs.
DEPTH 2 REASONING:
The user's question is about the proper format and signature handling for a motion to compel discovery in TTAB proceedings. This topic is covered mainly in the following areas of the TBMP and regulations:
- Signature and form of submissions in general (chunks 4,5,6,7,8,9,10,11,12).
- Requirements for format of motions including motions to compel (chunks 31,32,33,34,35,36,37,38).
- Specifics about motions to compel discovery, their content requirements, timing, and service (chunks 51,52,53,54,55,56,57,58,59,60,61,62,63,64).
- Service and certificate of service requirements related to motions (chunks 0,36).
To answer fully about format and signature, I should focus on the rules requiring electronic filing through ESTTA, the content and form requirements for motions, including page limits, and the signature rules specifying who must sign and how electronic signatures work.
The good faith effort requirement in motions to compel discovery and the inclusion of copies of relevant discovery requests and responses or objections is important to mention.
Therefore, the most relevant chunks to select and examine in depth are 4,5,6,7,8,9,10,11,12 for signature and general form; 31,32,33,34,35,36,37,38 for motion format and filing; and 51,52,53,54,55,56,57,58,59,60,61,62,63,64 for the procedure and content of motions to compel discovery including timing, service, and required good faith effort statement.
Returning 31 relevant chunks at depth 2
==== FIRST 3 RETRIEVED PARAGRAPHS ====
PARAGRAPH 1 (ID: 0.0.5.4):
----------------------------------------
The document should
also include a title describing its nature, e.g., “Notice of Opposition,” “Answer,” “Motion to Compel,” “Brief
in Opposition to Respondent’s Motion for Summary Judgment,” or “Notice of Reliance.”
Documents filed in an application which is the subject of an inter partes proceeding before the Board should
be filed with the Board, not the Trademark Operation, and should bear at the top of the first page both the
application serial number, and the inter partes proceeding number and caption. Similarly , requests under
Trademark Act § 7, 15 U.S.C. § 1057, to amend, correct, or surrender a registration which is the subject of
a Board inter partes proceeding, and any new power of attorney, designation of domestic representative, or
change of address submitted in connection with such a registration, should be filed with the Board, not with
the Trademark Operation, and should bear at the top of its first page the re gistration number, and the inter
partes proceeding number and the proceeding caption. [Note 2.] 100-14June 2024
TRADEMARK TRIAL AND APPEAL BOARD MANUAL OF PROCEDURE§ 105
NOTES:
1. 37 C.F.R. § 2.194. 2. 37 C.F.R. § 2.194. 106.02 Signature of Submissions
37 C.F.R. § 2.119(e) Every submission filed in an inter partes proceeding, and every request for an extension
of time to file an opposition, must be signed by the party filing it, or by the party’s attorney or other authorized
representative, but an unsigned submission will not be r efused consideration if a signed copy is submitted
to the Office within the time limit set in the notification of this defect by the Office. 37 C.F.R. § 11.14(e) Appearance.
----------------------------------------
PARAGRAPH 2 (ID: 0.0.5.5):
----------------------------------------
No individual other than those specified in par agraphs (a), (b), and (c)
of this section will be permitted to pr actice before the Office in tr ademark matters on behalf of a client. Except as specified in § 2.11(a) of this chapter, an individual may appear in a trademark or other non-patent
matter in his or her own behalf or on behalf of:
(1) A firm of which he or she is a member;
(2) A partnership of which he or she is a partner; or
(3) A corporation or association of which he or she is an officer and which he or she is authorized to
represent. 37 C.F.R. § 11.18 Signature and certificate for correspondence filed in the Office. (a) For all documents filed in the Office in patent, trademark, and other non-patent matters, and all
documents filed with a hearing officer in a disciplinary proceeding, except for correspondence that is
required to be signed by the applicant or party, each piece of correspondence filed by a practitioner in the
Office must bear a signature, personally signed or inserted by such practitioner, in compliance with §
1.4(d)(1), § 1.4(d)(2), or § 2.193(a) of this chapter.
----------------------------------------
PARAGRAPH 3 (ID: 0.0.5.5.6):
----------------------------------------
(b) By presenting to the Office or hearing officer in a disciplinary proceeding (whether by signing,
filing, submitting, or later advocating) any paper, the party presenting such paper, whether a practitioner
or non-practitioner, is certifying that—
(1) All statements made therein of the party’s own knowledge are true, all statements made therein
on information and belief are believed to be true, and all statements made therein are made with the
knowledge that whoever, in any matter within the jurisdiction of the Office, knowingly and willfully falsifies,
conceals, or covers up by any trick, scheme, or device a material fact, or knowingly and willfully makes any
false, fictitious, or fraudulent statements or representations, or knowingly and willfully makes or uses any
false writing or document knowing the same to contain any false, fictitious, or fraudulent statement or entry,
shall be subject to the penalties set forth under 18 U.S.C. 1001 and any other applicable criminal statute,
and violations of the provisions of this section may jeopardize the probative value of the paper; and
(2) To the best of the party’s knowledge, information and belief, formed after an inquiry reasonable
under the circumstances,
(i) The paper is not being presented for any improper purpose, such as to harass someone or to
cause unnecessary delay or needless increase in the cost of any proceeding before the Office;
(ii) The other legal contentions therein are warranted by existing law or by a nonfrivolous
argument for the extension, modification, or reversal of existing law or the establishment of new law;
June 2024100-15
§ 106.02GENERAL INFORMATION
(iii) The allegations and other factual contentions have evidentiary support or, if specifically so
identified, are likely to have evidentiary support after a reasonable opportunity for further investigation or
discovery; and
(iv) The denials of factual contentions are warranted on the evidence, or if specifically so
identified, are reasonably based on a lack of information or belief.
----------------------------------------Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. Language Models, AI Agents, Agentic Apps, Dev Frameworks & Data-Driven Tools shaping tomorrow.