HILL: Solving for LLM Hallucination & Slop
HILL is a prototypical User Interface which highlight hallucinations to LLM users, enabling them to assess the factual correctness of an LLM response.


Introduction
HILL can be described as a User Interface for accessing LLM APIs. To some extent HILL reminds of a practice called grounding. Grounding has been implemented by OpenAI and Cohere, where documents are uploaded. Should a user query match uploaded content, a piece of an uploaded document is used as contextual reference; in a RAG-like fashion. A link is also provided to the document referenced and serves as grounding.
Slop is the new Spam. Slop refers to unwanted generated content, like Google’s Search Generative Experience (SGE), which sits above some search results. As you will see later in the article, HILL will tell users how valuable auto-generated content is. Or if it could be regarded as slop.
HILL is not a generative AI chat UI like HuggingChat, Cohere Coral or ChatGPT…however, I can see a commercial use-case for HILL as a user interface for LLMs.
One can think of HILL as a browser of sorts for LLMs. If search offerings include this type of information by default, there is sure to be immense user interest.
The information supplied by HILL includes:
Confidence Score: the overall score of accuracy or response generation.
Political Spectrum: A score classifying the political spectrum of the answer on a scale between -10 and + 10.
Monetary Interest: A score classifying the probability of paid content in the generated response on a scale from 0 to 10.
Hallucination: Identification of the response parts that appear to be correct but are actually false or not based on the input.
Self-Assessment Score: A percentage score between 0 and 100 on how accurate and reliable the generated answer is.
I believe there will be value in a settings option where the user can define their preferences in terms of monetary interests, political spectrum and the like.
More On HILL
The image below shows the UI developed for HILL. Highlighting hallucinations to users and enabling users to assess the factual correctness of an LLM response.

The image below shows the positioning and delimitation of this study.
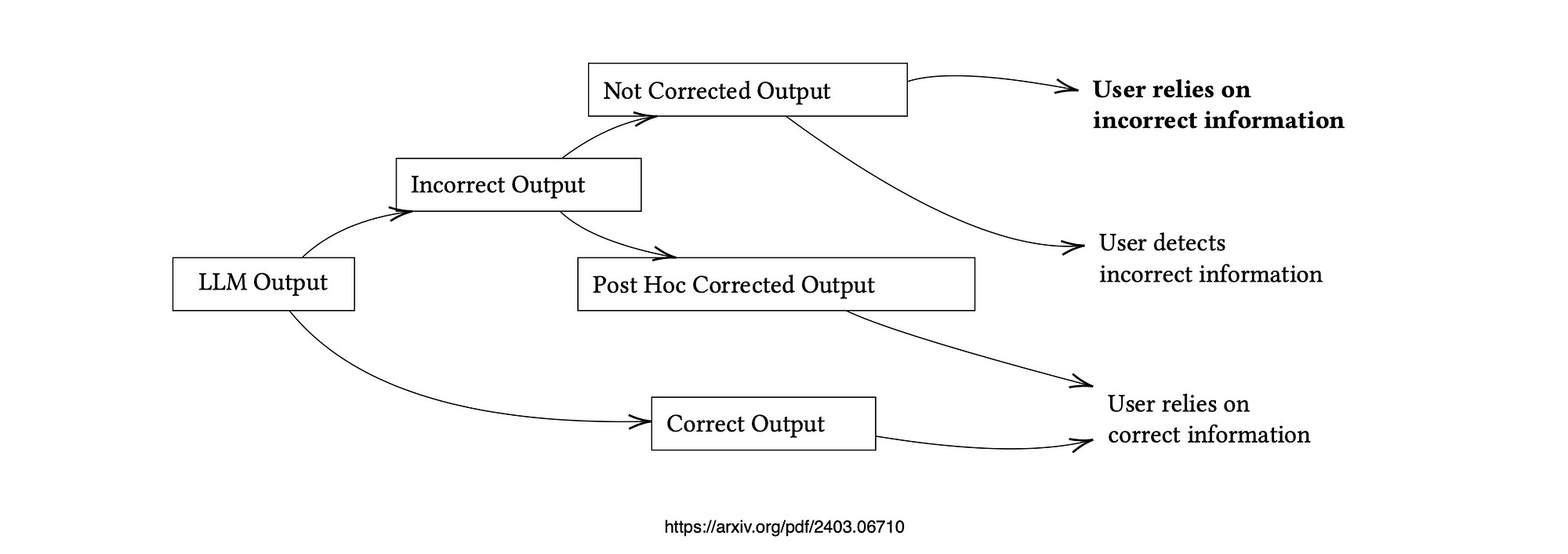
While existing methodologies centre on rectifying LLM hallucinations, the HILL approach’s objective is to empower users to refrain from depending on hallucinations.
These methodologies do not vie against each other but instead complement each other, both being vital in achieving the overarching aim of users no longer unquestioningly adhering to erroneous LLM output.

The image above shows a prototypical UI with a confidence score, uncertain information and the information sources.
In Conclusion
In this research, HILL is created. A tool to identify hallucinations in Large Language Models (LLMs). HILL addresses the significant problem of hallucinations in LLM responses, focussing on ensuring users don’t overly trust inaccurate information.
Prioritised features for HILL were based on feedback from everyday users who interacted with prototypes.
It was found that users valued:
Source links and a
Credibility score metric.
They also emphasised the importance of recognising and highlighting paid content in responses to maintain system credibility.
Using this feedback, a web-based tool was developed that complements existing efforts to reduce hallucinations in LLMs.
In a survey with 17 participants, the study found that the interface allows users to question responses without feeling overwhelmed.
HILL was tested in its ability to detect hallucinations on a dataset and found it could accurately identify hallucinations in incorrect responses. User interviews further highlighted HILL’s potential to help users identify hallucinations.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.