How To Create HuggingFace🤗 Custom AI Models Using autoTRAIN
autoTrain makes it easy to create fine-tuned custom AI models without any code. autoTRAIN from HuggingFace🤗 is a web-based studio to upload data, train your model and put it to the test.


autoTRAIN is a powerful tool for testing, prototyping and exploring your data via a fine-tuned custom AI model.
There is a fair balance of functionality between the free and paid tier.
autoTRAIN closes the loop between preparing training data, model selection, training, testing and deploying a model.
Maintaining data privacy is easy. Training data stays on the HuggingFace server, and is private to my account. According to HuggingFace, all data transfers are protected with encryption.
Supported data formats include CSV, TSV or JSON files. Data preparation is straight forward and very much simplified.
The no-code interface of autoTRAIN allows for users to upload data, and train a custom fine-tuned model.
The training data is split between training data and testing data.
While the model trains the real-time results are shown in terms of model accuracy, as seen below. The model cards rearranges as the accuracy scores are updated:

Below is a practical step-by-step example on how to create a text classification model.
The dataset used for training is the HuggingFace banking77 dataset.
However, any model trained on > 3,000 records of data, requires payment.
Hence I downloaded the CSV file and truncated it to < 3,000 records. You can see the two labels of the two columns below:
text
category
And each of the utterances are labeled with a class name. These can also be thought of as intent names. The file has 77 different classes/intents which are assigned.

Once the data is prepared, you can head to the autoTRAIN UI, and click on Create new project:

Once you have clicked on new project, the window below is displayed. There is the option of three tasks and the model choice.
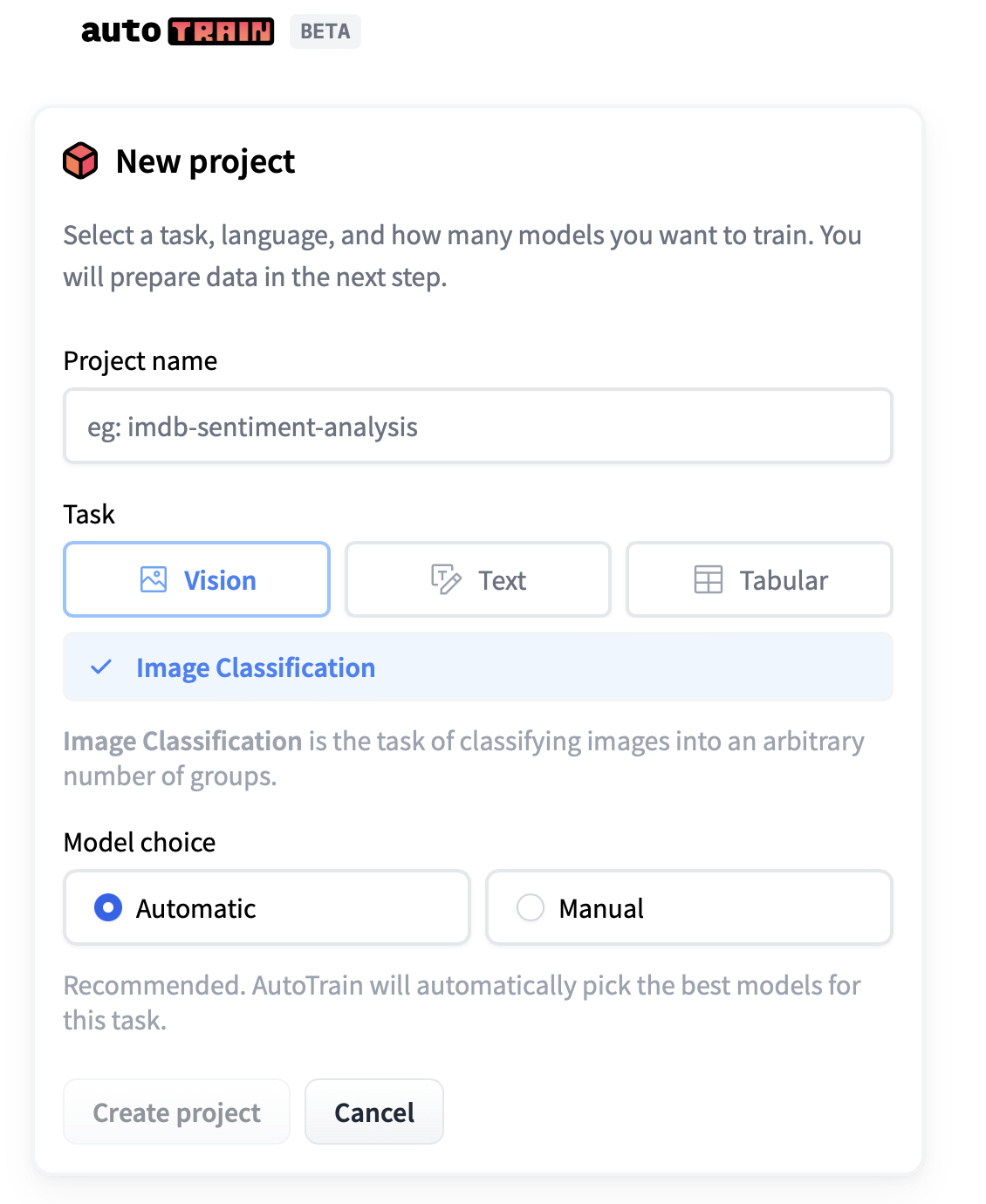
For this example under Task, Text was selected with multi-class text classification. This is inline with the aim of performing intent detection on the utterances.

The next step is to upload the data, the easiest way to do this is to browse the HuggingFace datasets and select an applicable dataset. Due to the cost implications mentioned earlier, for this demonstration we will choose to upload the truncated CSV file.

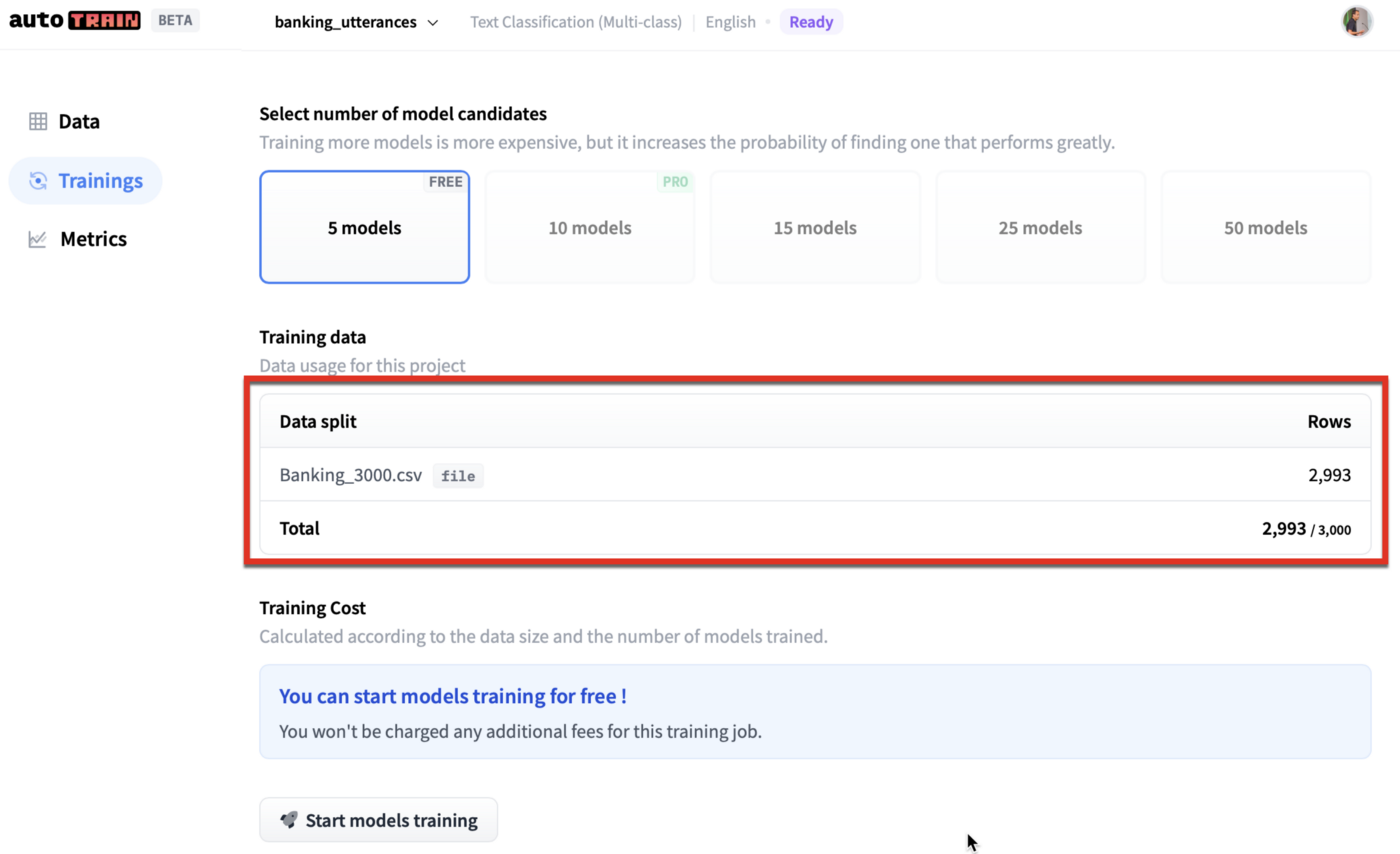
Below you can see the data is uploaded, the least amount of models which can be selected are five models, under the free tier. And we are going to ask autoTRAIN to automatically select the five best suited models for this task.
Once training is initiated it cannot be stopped, hence the confirmation dialog seen below. In our case this is perhaps not that relevant, but in a scenario where significant costs can be incurred, due diligence is necessary.

As I stated earlier, as the models train, the ranking changes and the model cards rearrange automatically. Below you see the final results from the five trained models.

Below the metrics of each model is visible, something I find interesting is that it does not seem possible to view what the underlying models are, which was automatically selected by autoTRAIN.

From autoTRAIN the dataset can be displayed in HuggingFace, and in this case the dataset is set to private.

What I really found impressive is that a model card is created automatically. Here the model can be interrogated in a no-code fashion like you would any other model.
Below you can see the sentence I lost my card and want an update on when to expect my replacement card? with the returned classes or intents.

A test (non-production) inference API can be generated to test from a notebook environment, as seen below. This is still all available within the free tier.

The working Python code below:
import requests
API_URL = "https://api-inference.huggingface.co/models/Cobus/autotrain-banking_utterances-3301491749"
headers = {"Authorization": "Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxx"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "I lost my credit card and need an update on my new card delivery date.",
})
print (output)With the returned result in JSON:
[[{'label': 'card_arrival', 'score': 0.9718345999717712},
{'label': 'lost_or_stolen_card', 'score': 0.011649119667708874},
{'label': 'card_delivery_estimate', 'score': 0.0029276181012392044},
{'label': 'contactless_not_working', 'score': 0.0026350687257945538},
{'label': 'card_linking', 'score': 0.001585263293236494},
{'label': 'transfer_not_received_by_recipient', 'score': 0.0013511107536032796},
{'label': 'card_not_working', 'score': 0.0013335602125152946},
{'label': 'supported_cards_and_currencies', 'score': 0.0008178158896043897},
{'label': 'extra_charge_on_statement', 'score': 0.000803415197879076},
{'label': 'card_payment_fee_charged', 'score': 0.0006243446841835976},
{'label': 'top_up_limits', 'score': 0.0005359890055842698},
{'label': 'automatic_top_up', 'score': 0.0005015501519665122},
{'label': 'age_limit', 'score': 0.0004812037805095315},
{'label': 'pin_blocked', 'score': 0.00043944784556515515},
{'label': 'exchange_rate', 'score': 0.00040180073119699955},
{'label': 'card_payment_wrong_exchange_rate', 'score': 0.0003744944406207651},
{'label': 'exchange_via_app', 'score': 0.000303107313811779},
{'label': 'fiat_currency_support', 'score': 0.00029278729925863445},
{'label': 'cancel_transfer', 'score': 0.0002708041574805975},
{'label': 'wrong_amount_of_cash_received', 'score': 0.00025225072749890387},
{'label': 'pending_top_up', 'score': 0.00020582920114975423},
{'label': 'pending_cash_withdrawal', 'score': 0.00019256919040344656},
{'label': 'top_up_by_bank_transfer_charge', 'score': 0.0001863267971202731}]]Please consider following me on LinkedIn for updates on Conversational AI.

I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.

