Implementing Chain-of-Thought Principles in Fine-Tuning Data for RAG Systems
Knowledge-oriented question answering is now a crucial aspect of enterprise knowledge management, aiming to provide accurate responses to user queries by leveraging a knowledge base.


Introduction
As always, I’m open for persuasion and welcome any input in terms of something I might have missed…but of late I have noticed a new trend in research regarding Language Models. Both Large and Small Language Models.
As I have mentioned before, there is a focus on fine-tuning to not imbue the model with data, but rather change the behaviour and capabilities of the model. This can include reasoning capabilities, Chain-of-Thought capabilities or the ability to handle larger context windows better.
Training data is being handcrafted in a very granular and fine-grained fashion with more complex data design (topology) principles involved.
Fine-tuning of models are being performed for task-specific performance, and the efficiency of Small Language Models (SLMs) also improve drastically using these methods.
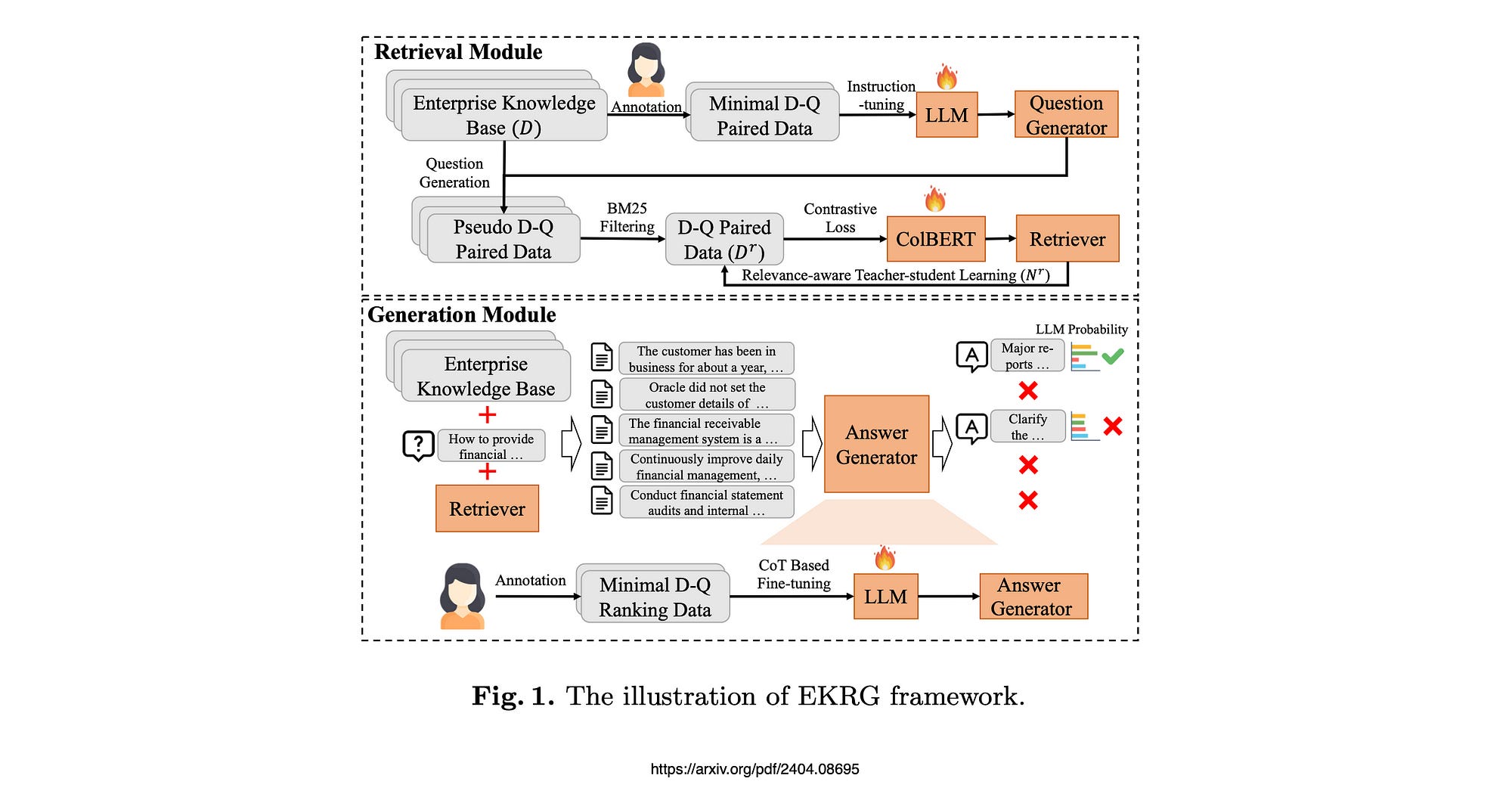
In this research to improve RAG performance, the generation model is subjected to Chain-Of-Thought (CoT) based fine-tuning.
RAG Basics
Currently RAG combines the strengths of two elements:
Information retrieval &
Natural language processing technologies.
This is performed primarily via a retrieve-and-read architecture which involves:
The system which receives a user query and retrieves semantically relevant documents from a knowledge base.
The reader model which distills and generates an answer from the content within these documents.
Data Design for Fine-Tuning
The study proposes a new Chain-Of-Thought based fine-tuning method to enhance the capabilities of the LLM generating the response.
Considering the image below, the study divided the RAG question types into three groupings:
Fact orientated,
Short & solution orientated &
Long & solution orientated.

Considering that retrieved documents may not always answer the user’s question, the burden is placed on the LLM to discern if a given document contains the information to answer the question.
Inspired by the Chain-Of-Thought Reasoning (CoT), the study proposes to break down the instruction into several steps.
Initially, the model should summarise the provided document for a comprehensive understanding.
Then, it assesses whether the document directly addresses the question.
If so, the model generates a final response, based on the summarised information.
Otherwise, if the document is deemed irrelevant, the model issues the response as irrelevant.
Additionally, the proposed CoT fine-tuning method should effectively mitigate hallucinations in LLMs, enabling the LLM to answer questions based on the provided knowledge documents.
Below the instruction for CoT fine-tuning is shown…

By leveraging a small set of annotated question-answer pairs, the researchers developed an instruction-tuning dataset to fine-tune an LLM, enabling it to answer questions based on retrieved documents.
There was focus to integrate answers from different documents for a specific question.
Rapid advancements in generative natural language processing technologies have enabled the generation of precise and coherent answers by retrieving relevant documents tailored to user queries.
In Conclusion
Firstly, the study introduces an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever.
This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.