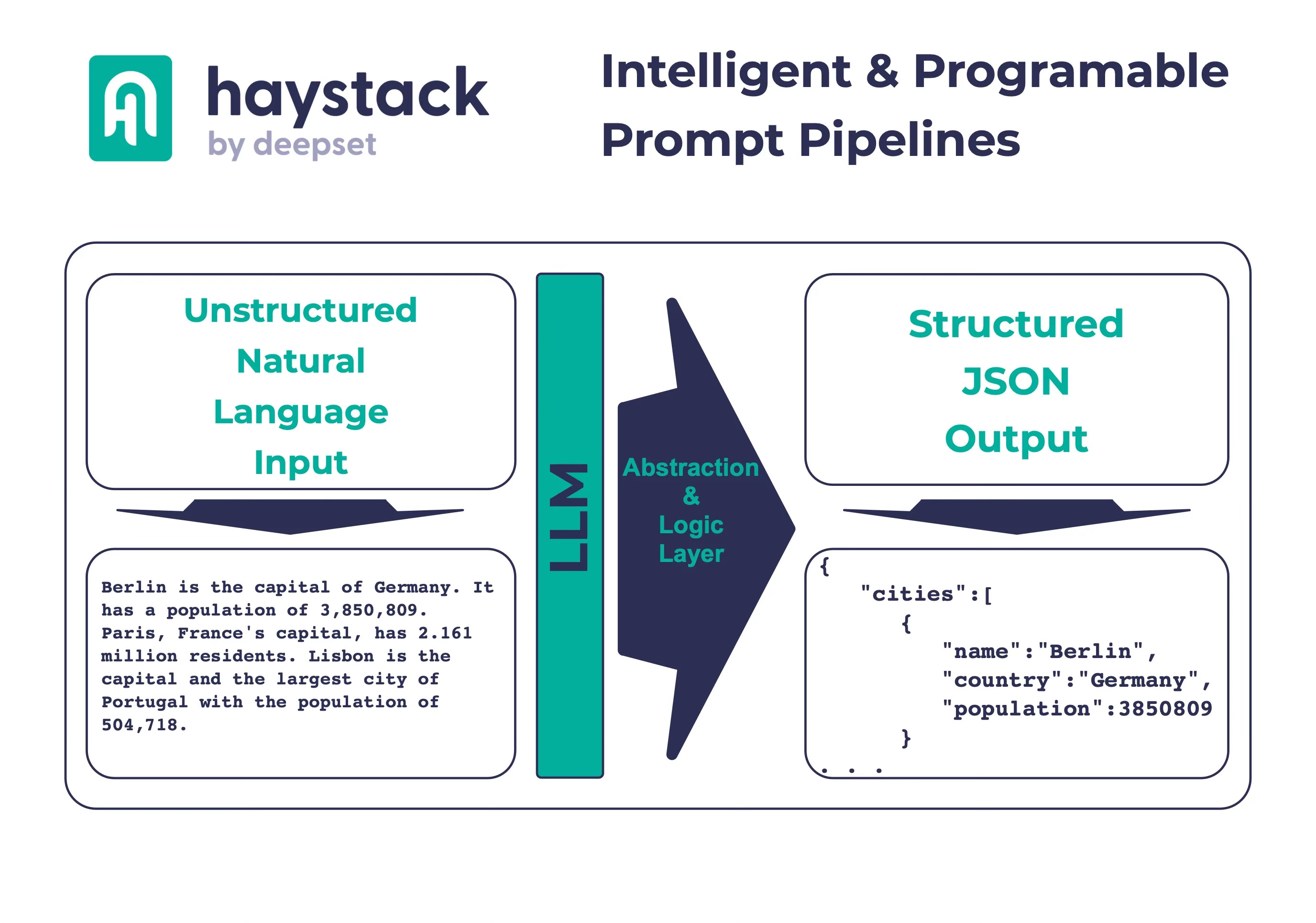
Intelligent & Programable Prompt Pipelines From Haystack
Considering LLM-based Generative Apps architectures, the leap from prompt chaining to autonomous agents are too big. Intelligent and programable prompt pipelines fill this void.

Introduction
There has been a few developments with regard to adding structure to the input and output of Large Language Models.
And I have alluded to this a few times in the recent past; the challenge with traditional chatbot architectures and frameworks is that you need to structure the unstructured conversational input from the user.
Followed by a subsequent abstraction layer where the structured data generated by the chatbot returned to the user needs to be unstructured again. To propegate the illusion of a natural language conversation.

Fast Forward to Large Language Models (LLMs), and we are on the other side of the spectrum, where the input and output of the LLMs are highly unstructured and conversational.
Hence now we have moved from the problem of scarcity, to the problem of abundance; going from fast to feast. And it is posing a challenge on how to harness the power of LLMs in a scaleable, flexible and repeatable fashion.
LLM Data Structuring
Considering all of this, there has been structuring taking place in terms of LLM input and output data.
Input Data
Input data has been structured specifically by OpenAI around the notion of chatbots or multi-turn dialogs. Hence the chat mode has been favoured above the other modes like the edit mode and completion mode. Both of these are scheduled for depreciation soon.
Another example of structure being introduced is around a more conversational approach in the form of newly added OpenAI Assistant functionality.
The chat mode input has a description of the chatbot in terms of tone, function, ambit etc. Together with the user and system messages being clearly segmented for each dialog turn.
The focus has also moved from string functions like text editing, summarisation etc. to a more conversational orientated approach.
Output Data
The output data from the OpenAI Assistant function calling is in the form of JSON. The json document is defined in terms of its structure, and each field in the JSON document is also described. Hence the LLM takes the user input and extract intents, entities and strings from the user input to assign to various fields in the predefined JSON document.
The JSON generation functionality is also interesting, but I see a vulnerability here in terms of the JSON structure. In this Implementation the output data is generated in the form of a JSON but the structure of the JSON is not kept constant or unchanged. The idea of a JSON document is to have a standardised output of data to be consumed by downstream systems like APIs. So having changing JSON structure defeats the objective of creating JSON output in the first place.
However, below is an article to a work-around.
Seeding can be used to keep the JSON static:
Now You Can Set GPT Output To JSON Mode
This feature is separate to function calling. When calling the models “gpt-4–1106-preview” or “gpt-3.5-turbo-1106” the…
Vulnerabilities
There are some considerations when introducing structure like JSON output, and that is the fact that you need control over how the JSON is created and the quality of the JSON generated.
Makers want to be able to define a JSON structure, and then have control over how and when data is segmented and assigned to the JSON structure. The challenge is to have checks and validation steps along the way, and a level of intelligence and complexity needs to be introduced to be able to manage the implementation. Hence this implementation from Haystack is very astute in terms of as an indication of what future Generative AI applications will look like.
The Short Comings Of OpenAI and JSON Function Calling
The naming of Function Calling is actually very misleading. If you choose function calling for the OpenAI LLM output, the LLMs does not actually call a function, or there is no integration with a function. The LLM merely generates output in the form of a JSON document.
As I have explained in this article thus far, not only is it not possible to fully control the structure of JSON document, but you might want to have multiple JSON documents and decision nodes or some layer of intelligence within the application.
Hence the level of simplicity portrayed within OpenAI is good to get users started and build and understanding of the basic concepts.
Back To Haystack
Some Considerations
The Haystack implementation is such a good example of how an abstraction layer or logic layer can be created to manage the data exchange between the user input and one or more LLMs.
There is a gap between prompt chaining and autonomous agents.
Where prompt chaining is too sequence and dialog-turn based… And the leap to Autonomous Agents being too big, in the sense that autonomous agents have multiple internal sequences it run to reach a final answer. So there is cost, latency and inspectability/observability concerns.
For Generative AI Apps (Gen-Apps) implementations multiple prompt pipelines can be exposed as APIs which can be called along the prompt chain. This approach introduced a level of flexibility to Prompt Chaining, resulting in a bridge between chaining and agents.
Code Example
For the complete executed code example, see below:
28_Structured_Output_With_Loop.ipynb at main · cobusgreyling/Haystack
Here is the prompt template used:
from haystack.components.builders import PromptBuilder
prompt_template = """
Create a JSON object from the information present in this passage: {{passage}}.
Only use information that is present in the passage. Follow this JSON schema, but only return the actual instances without any additional schema definition:
{{schema}}
Make sure your response is a dict and not a list.
{% if invalid_replies and error_message %}
You already created the following output in a previous attempt: {{invalid_replies}}
However, this doesn't comply with the format requirements from above and triggered this Python exception: {{error_message}}
Correct the output and try again. Just return the corrected output without any extra explanations.
{% endif %}
"""
prompt_builder = PromptBuilder(template=prompt_template)The unstructured conversational user input:
Berlin is the capital of Germany.
It has a population of 3,850,809. Paris, France's capital,
has 2.161 million residents. Lisbon is the capital and the largest city
of Portugal with the population of 504,718.And the structured output:
OutputValidator at Iteration 2: Valid JSON from LLM - No need for looping: {
"cities": [
{
"name": "Berlin",
"country": "Germany",
"population": 3850809
},
{
"name": "Paris",
"country": "France",
"population": 2161000
},
{
"name": "Lisbon",
"country": "Portugal",
"population": 504718
}
]
}Lastly
This example for Haystack shows how an application’s interaction with a LLM needs to be inspectable, observable, scaleable, while consisting of a framework to which complexity can be added.
There has been much focus on prompt engineering techniques which improves LLM performance by leveraging the In-Context Learning (ICL) which includes Retrieval Augmented Generation (RAG) approaches.
There also has been much focus on prompt chaining and a number of live implementations exist which uses prompt chaining. Most existing chatbot development frameworks have introduced LLM based prompt chaining functionality.
And, autonomous agents have also been developed, and this charge is being lead by LangChain. Although there are challenges with autonomous agentsin production in terms of latency, cost and execution / run-time observability and near real-time inspectability. This is where LangSmith will play an increasingly important role in the management of autonomous agents.
However, the idea of having a prompt pipeline, which sits somewhere between single prompts and chaining, needs more attention.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.