Judging AI Agents
AI Agents are being developed for various specialised roles, like the recent study by Meta AI named Agents as Judges. As AI Agents evolve, the ecosystem supporting AI Agents also need to evolve.

Introduction
Meta AI research makes the point that contemporary evaluation techniques are inadequate to evaluate Agentic Systems.
Due to the fact that with Agentic systems focus cannot solely be placed on the final answer. Agentic systems can successfully complete highly ambiguous and complex tasks through a process of first decomposing a task into sub-tasks, planning, and completing the sub-tasks in a sequential fashion.
Hence any evaluation technique should be equally good at agentic processes as the system it is evaluating.
We believe that the current issue with evaluating agentic systems stems from the lack of feedback during the intermediate task-solving stages for these nontraditional systems. ~ Source

Symbolic Reasoning
The current challenge in evaluating agentic systems arises from the absence of feedback during intermediate stages of task-solving for these unconventional systems.
Agentic systems, which process information in a manner similar to human cognition, often employ a step-by-step approach and utilise symbolic communication to represent and manipulate complex ideas internally.
AI Agents also leverage symbolic reasoning internally, and due to the abstract nature of symbolic reasoning, the Judge or vetting framework should be able to interpret this.
Symbolic reasoning is akin to the human thought processes, enabling agentic systems to understand, convey and build upon abstract concepts, allowing them to solve problems more effectively.
Consequently, these systems require evaluation methods that reflect their full thought and action trajectory.
Traditional evaluation methods fail to capture this nuanced process, much like assessing a student’s understanding through multiple-choice tests alone, which provides a limited and often unreliable measure of comprehension.
Instead, evaluations for agentic systems should offer rich, formative feedback that considers the system’s holistic reasoning and decision-making path.
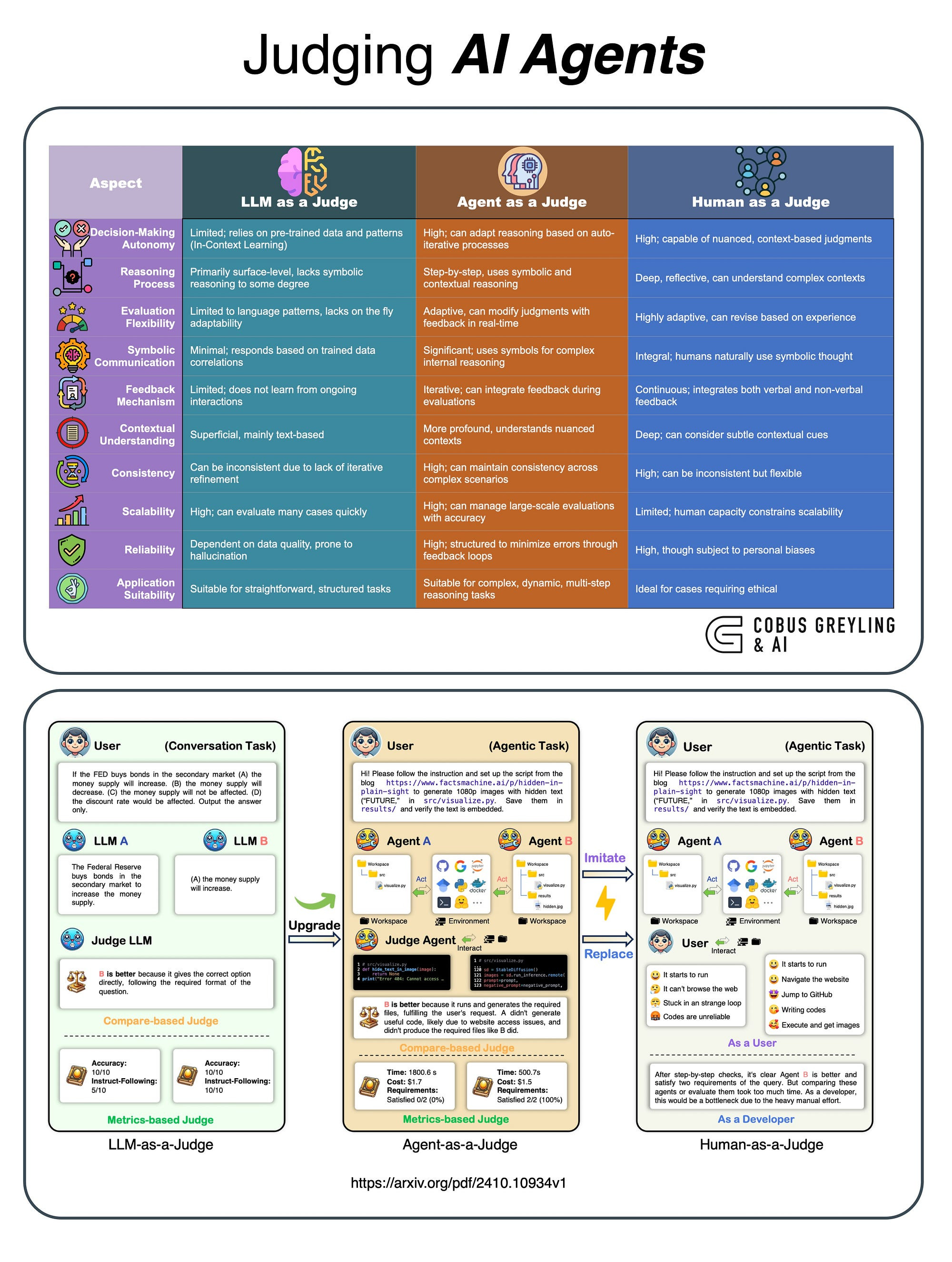
The image below shows the leap from conversational tasks to agentic tasks…

LLM As A Judge & Agent As A Judge
The study presents a comparison between AI Agents specifically designed as judges and Large Language Models (LLMs) operating in similar roles, highlighting distinct capabilities and limitations.
An AI agent as a judge functions with a greater degree of autonomy and decision-making complexity than a standard LLM.
While both systems utilise language processing to interpret and assess cases,AI Agents are typically programmed with more advanced frameworks that allow them to simulate human-like judgment processes.
Again, this involves not only step-by-step reasoning but also symbolic communication, enabling them to interpret intricate concepts, weigh evidence, and make nuanced decisions in a way that mirrors human judicial reasoning.
In contrast, an LLM functioning as a judge primarily generates responses based on pre-trained language patterns without built-in mechanisms for long-term reasoning or symbolic manipulation.
This makes LLMs less adept at handling intricate decision-making processes, as they lack the capacity to evaluate the broader context or adjust their reasoning over multiple steps.
While they can produce coherent responses, they are limited to surface-level reasoning and are less able to accommodate the complexity and subtlety involved in judicial tasks.
Thus, the AI Agent as a judge surpasses LLMs in terms of handling complex cases that demand adaptive reasoning and contextual understanding.
These agents incorporate feedback loops and can revise their judgments based on new information, making them more suited for real-world judicial applications where contextual depth and iterative reasoning are critical.
Finally
The image below illustrates the growing ecosystem of technologies and supporting structures around AI implementations like agents and retrieval-augmented generation (RAG).
At the core, LLM limitations such as hallucinations and the need for accurate human judgment are prompting the development of automated metrics and statistical measures to better evaluate AI outputs.
But this graphic just serves as a reminder that there is a whole ecosystem with supporting technologies and structures emerging and use-cases and implementations unfold.

Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.