Knowledge Retrieval Via The OpenAI Playground
In the new OpenAI playground under the Assistants Mode, OpenAI has added a Retrieval Augmentation tool. Does this qualify as a RAG implementation? Here I discuss the good and the bad.

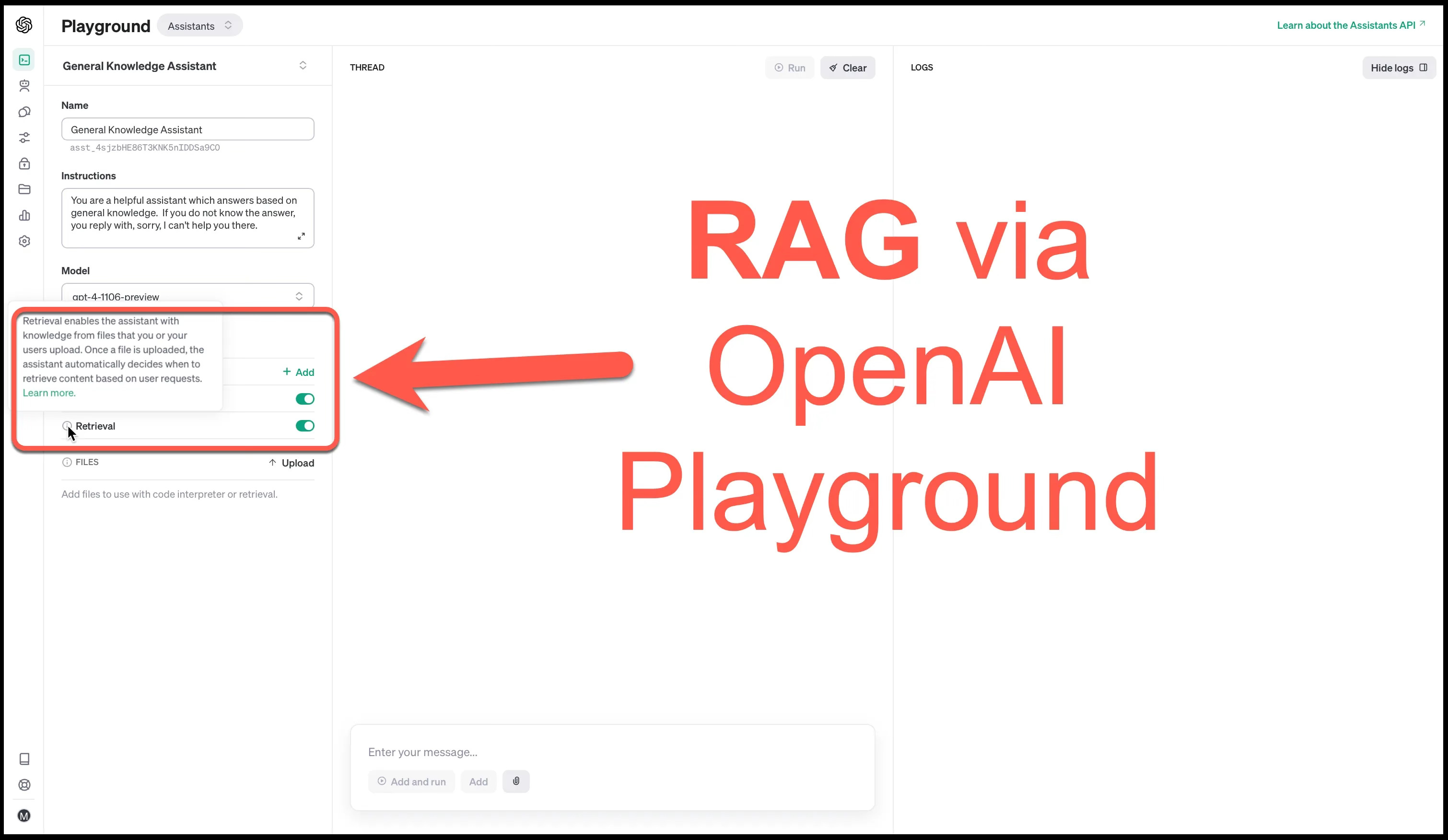
Why Retrieval Augmentation Is Important
The graph below shows the trending topics for the year 2023 and it is clear that a large part of the narrative has been on Retrieval Augmentation (aka RAG, Retrieval-Augmented Generation).
Hence this is an important extension of the OpenAI Playground; It’s safe to say that the OpenAI Playground has expanded into an no-code to low-code dashboard.
The Basics Of OpenAI Retrieval
OpenAI’s Retrieval feature enables the new assistant with knowledge from uploaded files. Once a file is uploaded it is automatically processed and automatically referenced by the assistant when needed.
OpenAI decides when to retrieve content and by implication context from the uploaded documents; all based on user input.
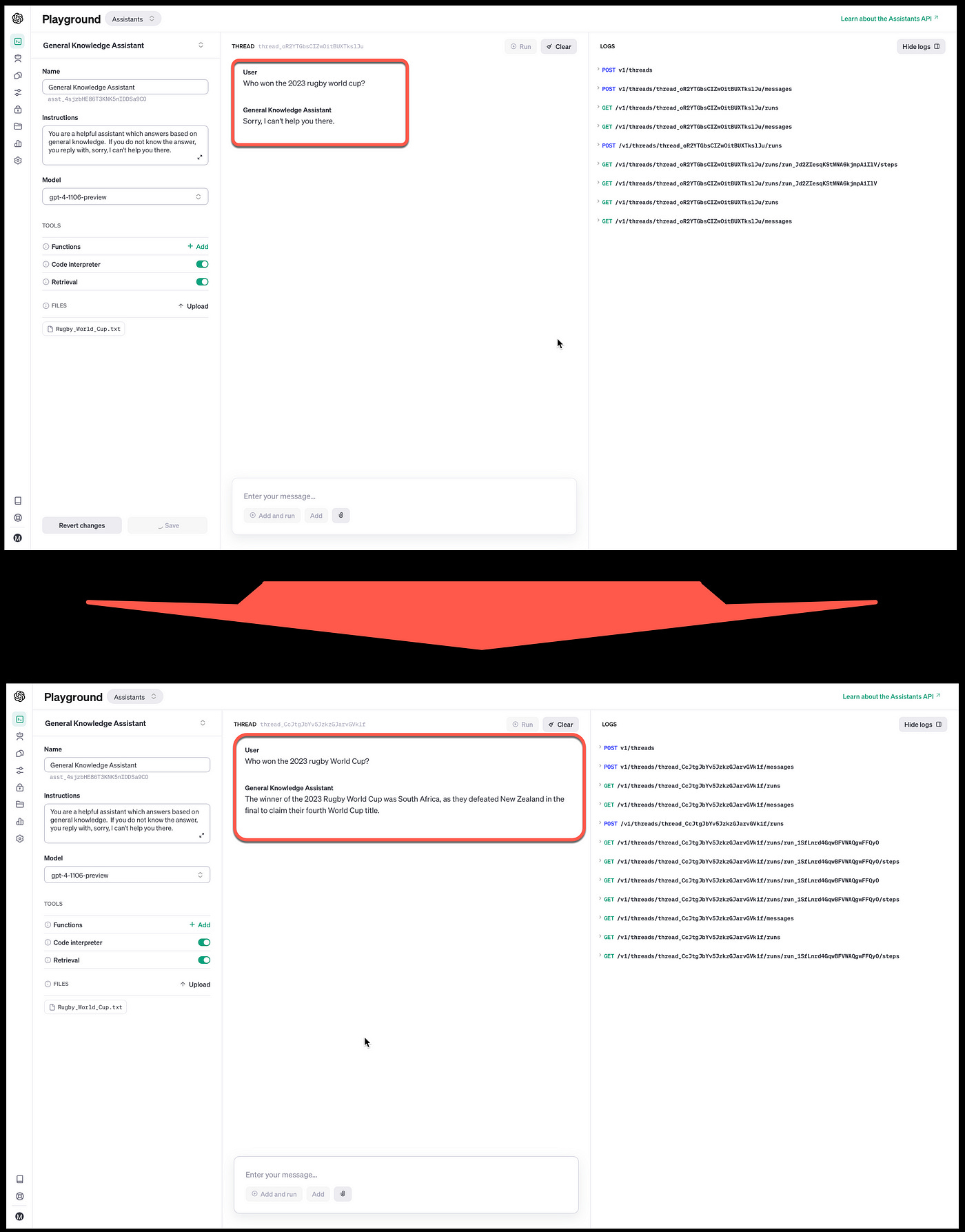
Considering the image below, first the assistant is asked a highly contextual and recent question, which the model cannot answer. As this question falls outside the time window of the model’s training.
The second image, a document was uploaded via the Retrieval option, and the same question was answered in a succinct and concise manner with information retrieved from the document.
It needs to be considered that Retrieval is built and hosted by OpenAI and is a closed and internally managed service.
The Retrieval tool only works with the gpt-3.5-turbo-1106 and gpt-4-1106-preview models.
A Glance Under The Hood
OpenAI states that the aim of the Retrieval feature is to augment the Assistant with knowledge from outside pre-trained models.
There needs to be a balance between automation but also a level of granularity…and here is the problem.
Once a file is uploaded and passed to the Assistant, OpenAI will automatically chunk your documents, index and store the embeddings, and implement vector search to retrieve relevant content to answer user queries.
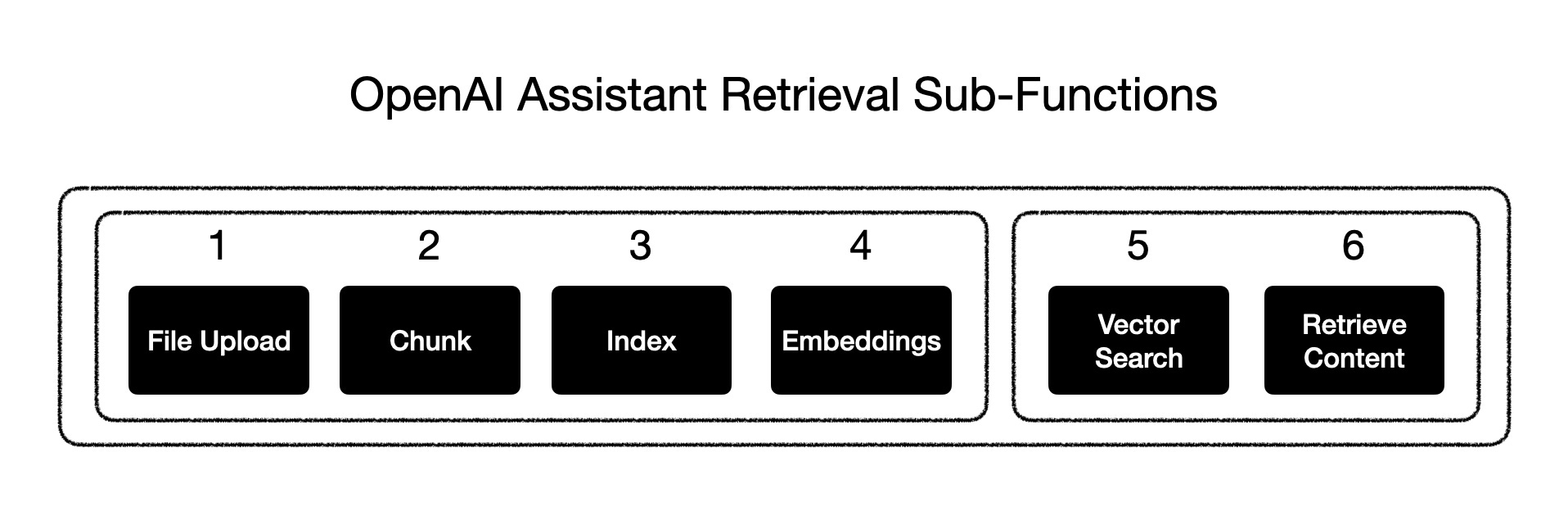
This process happens in sequence, automatically and so when uploading a file, the processing takes quite a while. To the uninformed, it might seem like a long time to “upload” a file. However, it needs to be considered that steps one to four are performed at design time automatically when the file is uploaded. And steps five and six are performed at run-time.
With input from a user to the assistant, the model decides when to retrieve content based on the user message.
The Assistants automatically chooses between two retrieval techniques:
Passing the file content in the prompt for short documents, or
Performs a vector search for longer documents.
Retrieval is aimed at optimising by adding relevant content to the context of model calls.
OpenAI is planning to introduce other retrieval strategies to enable developers to choose a different tradeoff between retrieval quality and model usage cost.
In Closing
This feature is a step in the right direction, and I wonder how many startup companies and products based on a “simple file upload RAG approach” are superseded or at least very much marginalised by the Retriever feature.
As stated by OpenAI, under the hood a traditional RAG architecture is followed. However, as complexity increases, so also will the demand for flexibility grow.
A feature which will be required for enterprise implementations is control on over how multiple documents are handled.
Insight into how chunking is performed and a GUI to tweak chunk size and content will also be needed.
Being able to directly perform a vector search to check the feedback, without any adjustment or contextualising the vector search output will also be insightful.
The logs do not give insight into the prompt structure, and how the model is queried with the contextual data. Or how prompts are injected.
More insight into how RAG is used will allow for astute application management.
One of the advantages and attractions of RAG is the fact that it is not an opaque approach like gradient implementations like soft prompts, or prompt tuning. But rather, from start to end the prompts, chunks and vector responses are all human readable and interpretable.
This allows for easier trouble shooting and discovery, inspection and correction.
Below, the input which demanded a response from the Retriever and the feedback from the retriver.
"file_ids": [],
"assistant_id": "asst_4sjzbHE86T3KNK5nIDDSa9CO",
"run_id": "run_lzIoGBYo8DhvHG5sU1G8XQ4t",
"metadata": {}
},
{
"id": "msg_uTDYVgKOiwssHI0YSgVH6sZM",
"object": "thread.message",
"created_at": 1699381752,
"thread_id": "thread_CcJtgJbYv5JzkzGJarvGVk1f",
"role": "user",
"content": [
{
"type": "text",
"text": {
"value": "Who won the 2023 rugby World Cup?",
"annotations": []
}
}
],
"file_ids": [],
"assistant_id": null,
"run_id": null,
"metadata": {}
},
{
"id": "msg_HQISlVFGTF5Nv8hkdzngXOGk",
"object": "thread.message",
"created_at": 1699369844,
"thread_id": "thread_CcJtgJbYv5JzkzGJarvGVk1f",
"role": "assistant",
"content": [
{
"type": "text",
"text": {
"value": "The winner of the 2023 Rugby World Cup was South Africa, as they defeated New Zealand in the final to claim their fourth World Cup title.",
"annotations": []
}
}
]⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.