LangChain Structured Output Parser Using OpenAI
The LangChain structured output parser in its simplest form closely resembles OpenAI’s function calling.


In this article I include a complete working example of the LangChain parser in its simplest form.
Introduction
One of the reasons for the wide adoption of LLMs is the fact that the User Interface (UI) of LLMs is natural language. And by definition natural language is unstructured.
Hence LLMs have the ability to take unstructured data as input in the form of natural language. The formulation of the unstructured data is still important and the natural language prompt still needs to contain the elements shown below.
These elements in broad terms are Data, Context, Instruction and Framing.
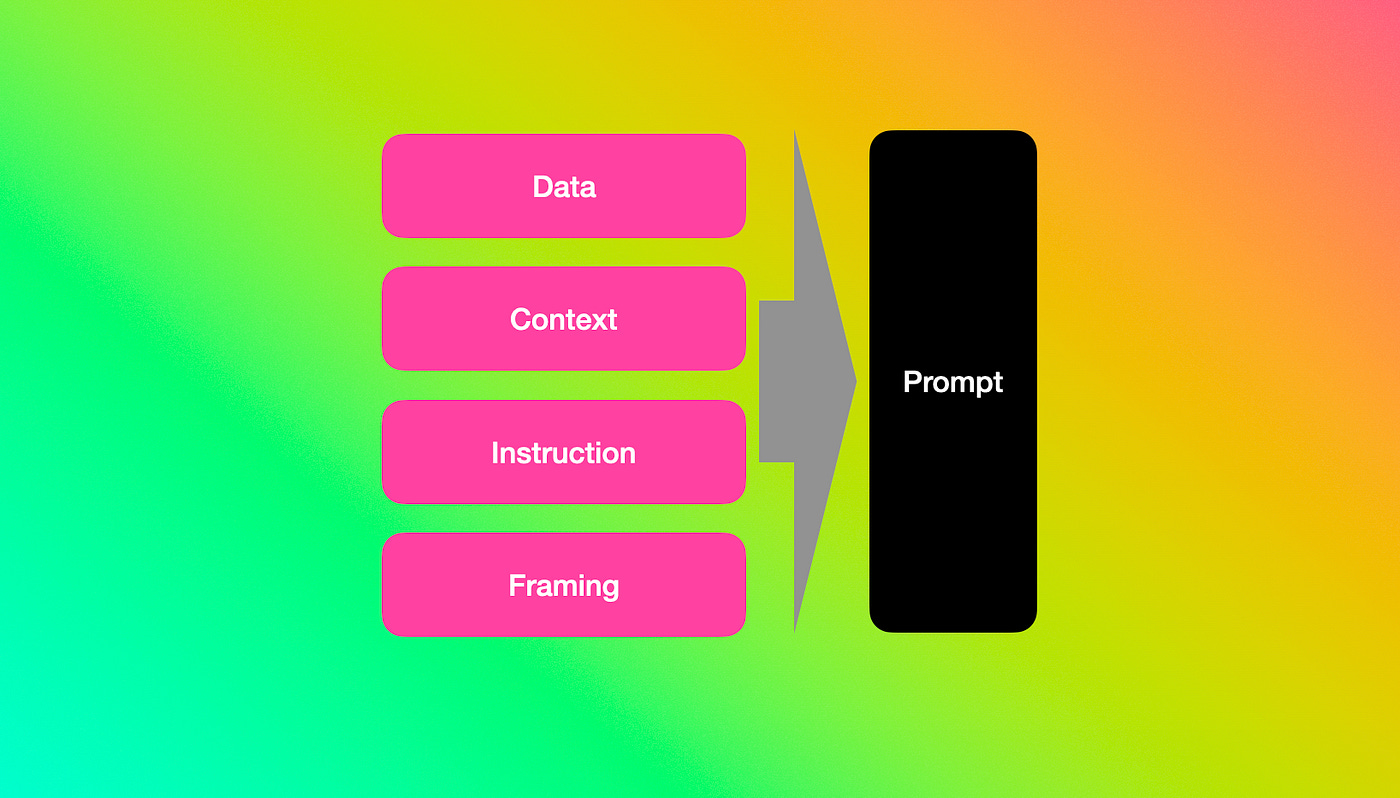
LLM & Unstructured Data
One of the strong points of LLMs are their ability to generate natural language (Natural Language Generation, NLG). And by implication the NLG process converts structured data, into unstructured conversational data.
However, there are instances where the output data needs to be structured; this could be necessitated by downstream systems. Hence formatting the data in the correct format to be consumed by APIs, etc. Below is an example from OpenAI’s JSON mode. Where unstructured data is inputted and the structured data is the output.
Unstructured LLM Input
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": "How many Olympic medals have Usain Bolt have and from which games?"}
],Structured LLM Output
{
"medals": {
"gold": 8,
"silver": 0,
"bronze": 0
},
"games": [
"Beijing 2008",
"London 2012",
"Rio 2016"
]
}Structure As An Agent Tool
Considering that autonomous agents are enabled by one or more Agent Tools it makes use of, structuring data can be one of those tools…
For instance, Agents might need to access an internet search tool, to get current weather conditions, or a RAG interface for data extraction…and if the user request data in a certain format, there can also be a tool to facilitate this.
LangChain Parser
The LangChain output parsers can be used to create more structured output, in the example below JSON is the structure or format of choice.
The LangChain output parsers are classes that help structure the output or responses of language models.
The two main implementations of the LangChain output parser are:
Get format instructions: A method which returns a string containing instructions for how the output of a language model should be formatted.
Parse: A method which takes in a string (assumed to be the response from a language model) and parses it into some structure.
There is also Parse with prompt:
A function receives a string, presumed to be the output of a language model, and a prompt, presumed to be the input that generated said output, and then processes it into a structured format.
The prompt serves primarily in cases where the OutputParser needs to reattempt or correct the output, requiring prompt-related details for such adjustments.
Get started
Below you will find a complete working example of what LangChain considers their main output parser, the Pydantic Output Parser.
You can take this Python code as-is and paste it into a Colab notebook.
All you will need to add is your OpenAI API key…
!pip install langchain
!pip install openai
pip install langchain-openai
##############################################
from langchain.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import OpenAI
##############################################
import os
os.environ['OPENAI_API_KEY'] = str("Your API Key Goes Here")
##############################################
model = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.0)
##############################################
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# You can add custom validation logic easily with Pydantic.
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
##############################################
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)
##############################################
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
##############################################
# And a query intended to prompt a language model to populate the data structure.
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": "Tell me a joke."})
parser.invoke(output)And the structured JSON output from the LangChain parser:
Joke(
setup='Why did the tomato turn red?',
punchline='Because it saw the salad dressing!'
)In Conclusion
Structuring the unstructured output from large language models is a critical task in leveraging their potential for a wider range of applications.
When these models generate text, the output lacks organisation and structure, making it challenging for downstream processes to interpret effectively.
However, by implementing structured parsing techniques, this raw output can be transformed into a more manageable and insightful form.
One approach involves breaking down the output into meaningful components, such as sentences, paragraphs, or semantic units.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.