LangSmith by LangChain
Here I consider three of the five components of LangSmith (by LangChain). Those three being Projects, Datasets & Testing and Hub.

Introduction
I really like the way the notebook and the LangSmith GUI integrate seamlessly. With tasks being performed via code with the results visible via the web GUI.
Applications can be sorted under projects, prompts are accessed via the prompt hub. With Datasets & Testing holding data and linked to agent runs.
LangChain has to a large extend democratised the development of LLM-based generative applications.
Prototyping with LangChain is one thing, but taking applications to production introduces a whole different dimension.
LangSmith is a companion technology to LangChain to assist with observability, inspectability, testing, and continuous improvement.
LangSmith is especially helpful when running autonomous agents, where the different steps or chains in the agent sequence is shown. Also when multiple parallel requests are sent to the LLMs.
In this article I only consider three of the five tools within LangSmith; Projects, Datasets & Testing & Hub.

Run An Agent While Logging Traces
Whenever a new project is created within LangSmith, under the Setup tab the code snippets are shown, which can be include in your code to reference and log traces to the LangSmith project.
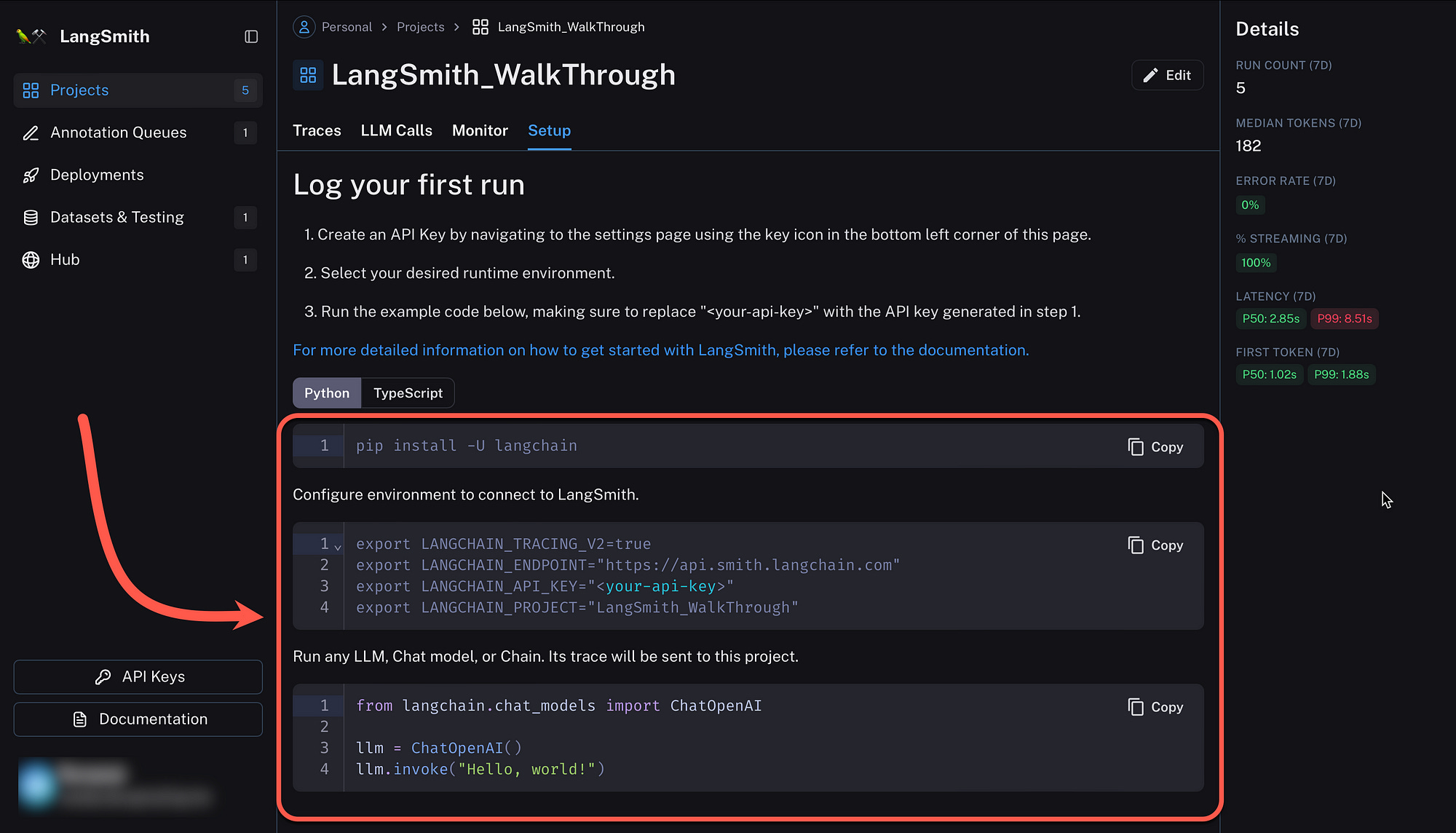
Below you see the Python code to install LangChain with the required components. Also notice how the environment variables are set. You are able to run this application fully within a Colab notebook.
%pip install --upgrade --quiet langchain langsmith langchainhub --quiet
%pip install --upgrade --quiet langchain-openai tiktoken pandas duckduckgo-search --quiet
import os
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"LangSmith_WalkThrough"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<Your LangSmith API Key>" # Update to your API key
# Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<Your OpenAI API Key>"Defined Agent
Considering the agent, notice the only tool defined for this agent:
tools = [
DuckDuckGoSearchResults(
name="duck_duck_go"
), # General internet search using DuckDuckGo
]The prompt at the centre of this Agent is fetched with the code below:
prompt = hub.pull("wfh/langsmith-agent-prompt:5d466cbc")And the prompt retrieved from the prompt hub:
input_variables=['agent_scratchpad', 'input']
input_types={'agent_scratchpad':
typing.List[typing.Union[langchain_core.messages.ai.AIMessage,
langchain_core.messages.human.HumanMessage,
langchain_core.messages.chat.ChatMessage,
langchain_core.messages.system.SystemMessage,
langchain_core.messages.function.FunctionMessage,
langchain_core.messages.tool.ToolMessage]]}
messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[],
template='
You are an expert senior software engineer.
You are responsible for answering questions about LangChain.
Use functions to consult the documentation before answering.')),
HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'],
template='{input}')), MessagesPlaceholder(variable_name='agent_scratchpad')]The code to run the agent:
from langsmith import Client
client = Client()
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.tools import DuckDuckGoSearchResults
from langchain_community.tools.convert_to_openai import format_tool_to_openai_function
from langchain_openai import ChatOpenAI
# Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:5d466cbc")
llm = ChatOpenAI(
model="gpt-3.5-turbo-16k",
temperature=0,
)
tools = [
DuckDuckGoSearchResults(
name="duck_duck_go"
), # General internet search using DuckDuckGo
]
llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
runnable_agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(
agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
inputs = [
"What is LangChain?",
"What's LangSmith?",
"When was Llama-v2 released?",
"What is the langsmith cookbook?",
"When did langchain first announce the hub?",
]
results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True)And the output from the Agent:
[{'input': 'What is LangChain?',
'output': 'I\'m sorry, but I couldn\'t find any information about "LangChain". Could you please provide more context or clarify your question?'},
{'input': "What's LangSmith?",
'output': 'I\'m sorry, but I couldn\'t find any information about "LangSmith". It could be a company, a product, or a person. Can you provide more context or details about what you are referring to?'},
{'input': 'When was Llama-v2 released?',
'output': 'Llama-v2 was released on July 18, 2023.'},
{'input': 'What is the langsmith cookbook?',
'output': 'The Langsmith Cookbook is a collection of recipes and cooking techniques created by Langsmith, a fictional character. It is a comprehensive guide that covers a wide range of cuisines and dishes. The cookbook includes step-by-step instructions, ingredient lists, and tips for successful cooking. Whether you are a beginner or an experienced cook, the Langsmith Cookbook can help you enhance your culinary skills and create delicious meals.'},
{'input': 'When did langchain first announce the hub?',
'output': 'LangChain first announced the LangChain Hub on September 5, 2023.'}]It is evident that the Agent is not performing optimal, hence LangSmith can be used to evaluate and improve the Agent.
Inspectability is illustrated with the image below; where the chain of execution of the agent can be inspected. The response snippet from the DuckDuckGo integration is shown, which serves as in-context learning for the prompt.
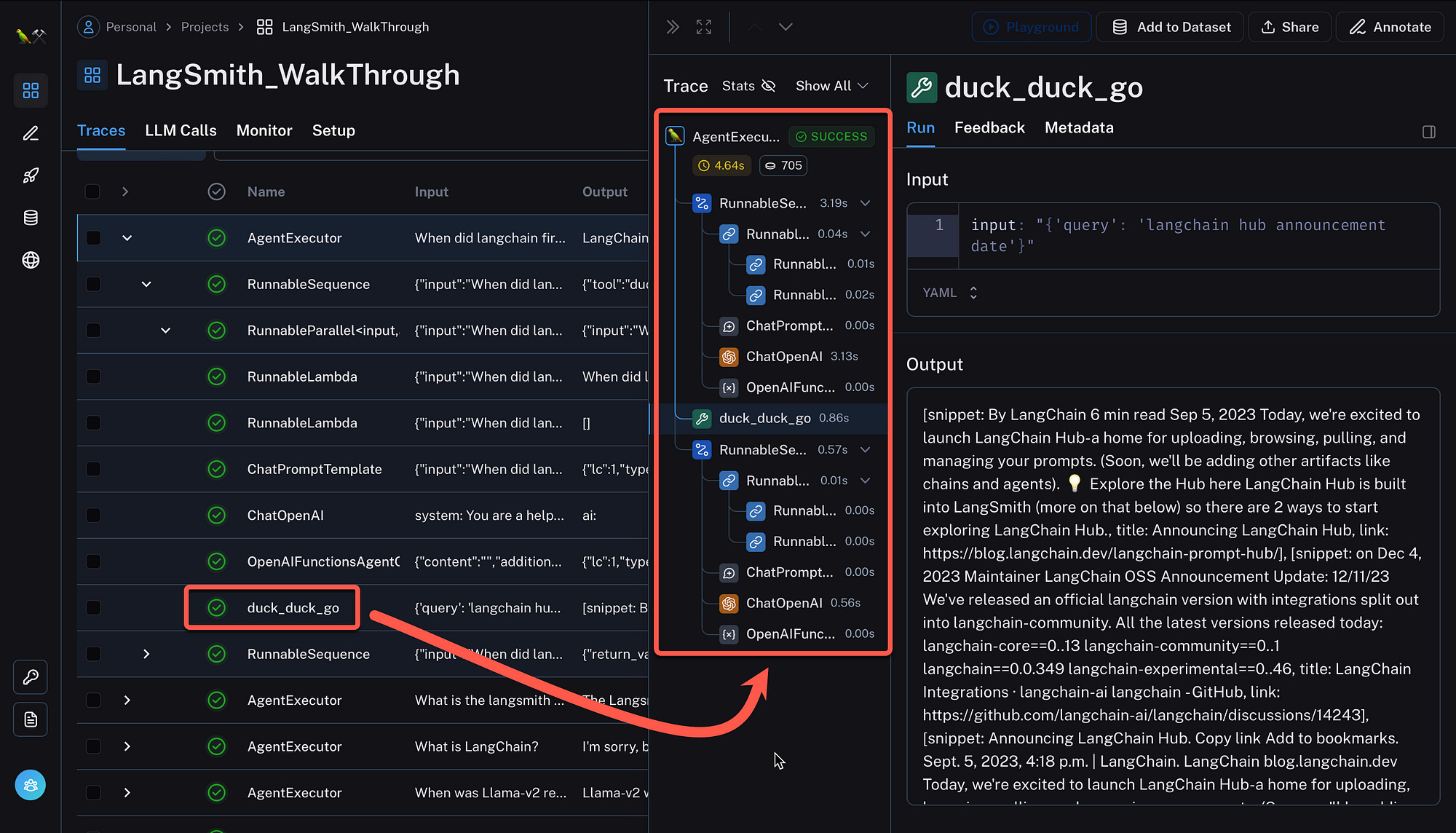
Create LangSmith Dataset
Below the five example input and outputs are shown, which is used for the test run. These entries will be used to measure the performance of the new agent.
A dataset is a collection of examples, which are nothing more than input-output pairs you can use as test cases to your application.

The example set is loaded programmatically in the following way:
outputs = [
"LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.",
"LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain",
"July 18, 2023",
"The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.",
"September 5, 2023",
]And,
dataset_name = f"LangSmith Walkthrough"
dataset = client.create_dataset(
dataset_name,
description="An example dataset of questions over the LangSmith documentation.",
)
client.create_examples(
inputs=[{"input": query} for query in inputs],
outputs=[{"output": answer} for answer in outputs],
dataset_id=dataset.id,
)Defining Agent To Benchmark
Below, an agent is defined which uses OpenAI’s function calling endpoints.
from langchain import hub
from langchain.agents import AgentExecutor, AgentType, initialize_agent, load_tools
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain_community.tools.convert_to_openai import format_tool_to_openai_function
from langchain_openai import ChatOpenAI
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def create_agent(prompt, llm_with_tools):
runnable_agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)Configure Evaluation
Manually comparing the results of chains in the UI is effective, but it can be time consuming.
Automating metrics and AI-assisted feedback to evaluate agent performance is more time effective.
Below is the code to create a custom run evaluator that logs a heuristic evaluation.
from langsmith.evaluation import EvaluationResult, run_evaluator
from langsmith.schemas import Example, Run
@run_evaluator
def check_not_idk(run: Run, example: Example):
"""Illustration of a custom evaluator."""
agent_response = run.outputs["output"]
if "don't know" in agent_response or "not sure" in agent_response:
score = 0
else:
score = 1
# You can access the dataset labels in example.outputs[key]
# You can also access the model inputs in run.inputs[key]
return EvaluationResult(
key="not_uncertain",
score=score,
)Below, the custom evaluator is defined, with comparing results with ground truth labels.
Measure semantic similarity using embedding distance, etc.
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig
evaluation_config = RunEvalConfig(
# Evaluators can either be an evaluator type (e.g., "qa", "criteria", "embedding_distance", etc.) or a configuration for that evaluator
evaluators=[
# Measures whether a QA response is "Correct", based on a reference answer
# You can also select via the raw string "qa"
EvaluatorType.QA,
# Measure the embedding distance between the output and the reference answer
# Equivalent to: EvalConfig.EmbeddingDistance(embeddings=OpenAIEmbeddings())
EvaluatorType.EMBEDDING_DISTANCE,
# Grade whether the output satisfies the stated criteria.
# You can select a default one such as "helpfulness" or provide your own.
RunEvalConfig.LabeledCriteria("helpfulness"),
# The LabeledScoreString evaluator outputs a score on a scale from 1-10.
# You can use default criteria or write our own rubric
RunEvalConfig.LabeledScoreString(
{
"accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference."""
},
normalize_by=10,
),
],
# You can add custom StringEvaluator or RunEvaluator objects here as well, which will automatically be
# applied to each prediction. Check out the docs for examples.
custom_evaluators=[check_not_idk],
)The prompt is imported from the LangSmith prompt hub:
from langchain import hub
# We will test this version of the prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:798e7324")
print (prompt)The evaluation process is run, this fetches the example rows from the specified datasets.
The agent is run on each example, and evaluators are applied to the resulting run traces with automated generated feedback.
The results are visible within LangSmith.
import functools
from langchain.smith import arun_on_dataset, run_on_dataset
chain_results = run_on_dataset(
dataset_name=dataset_name,
llm_or_chain_factory=functools.partial(
create_agent, prompt=prompt, llm_with_tools=llm_with_tools
),
evaluation=evaluation_config,
verbose=True,
client=client,
project_name=f"runnable-agent-test-5d466cbc-{unique_id}",
# Project metadata communicates the experiment parameters,
# Useful for reviewing the test results
project_metadata={
"env": "testing-notebook",
"model": "gpt-3.5-turbo",
"prompt": "5d466cbc",
},
)
# Sometimes, the agent will error due to parsing issues, incompatible tool inputs, etc.
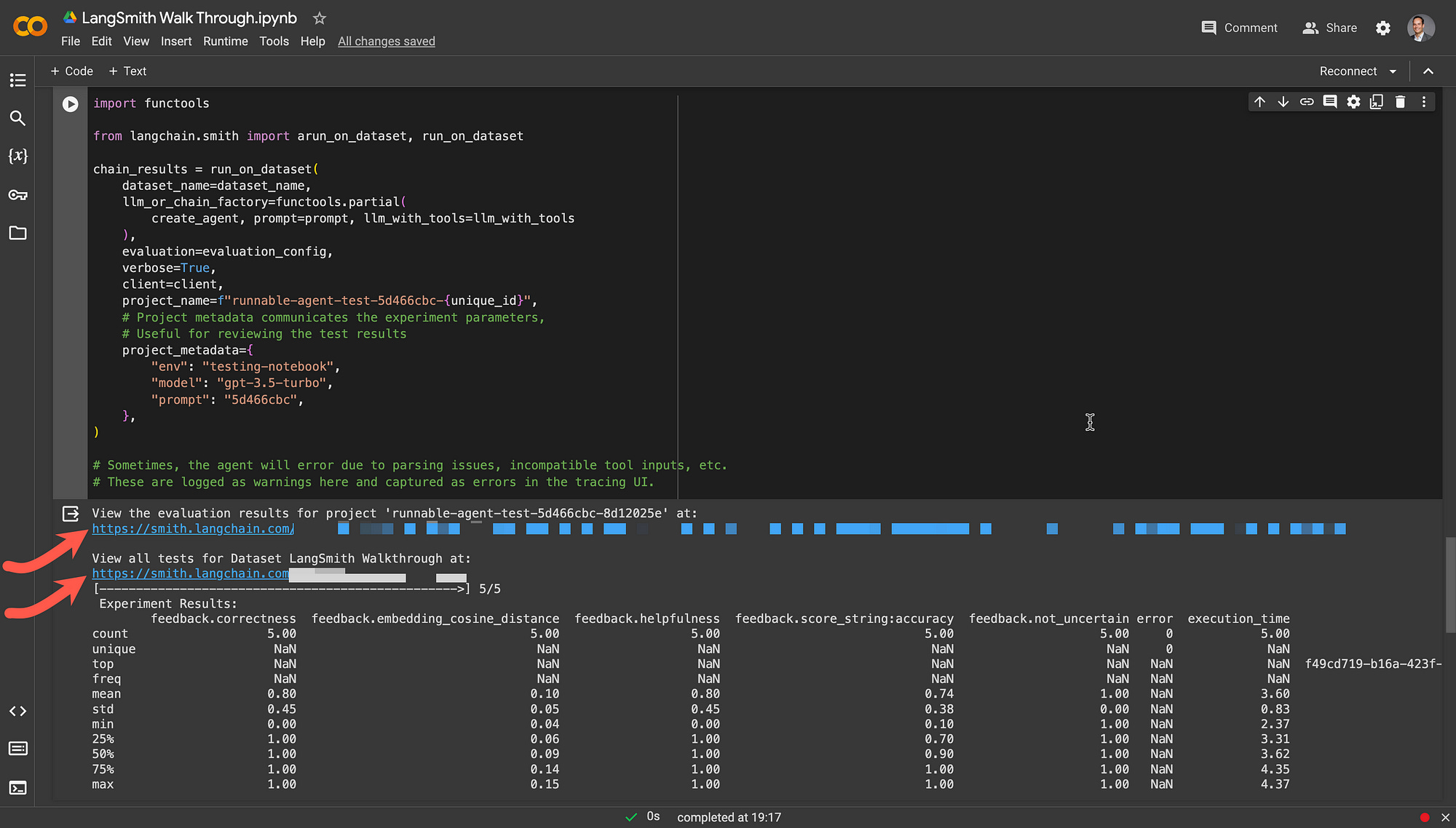
# These are logged as warnings here and captured as errors in the tracing UI.Within LangSmith, the input, example reference output and the test results can be viewed.

Inspectability
Notice how in the image below, when the evaluation is run within the notebook, links are created. The first link allows for the evaluation results to be viewed or all the tests for the dataset can also be viewed.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.