Language Model Quantization Explained
Small Language Models (SLMs) are very capable for NLG (Natural Language Generation, logic & common-sense reasoning, language understanding, entity recognition and more…


Some Background
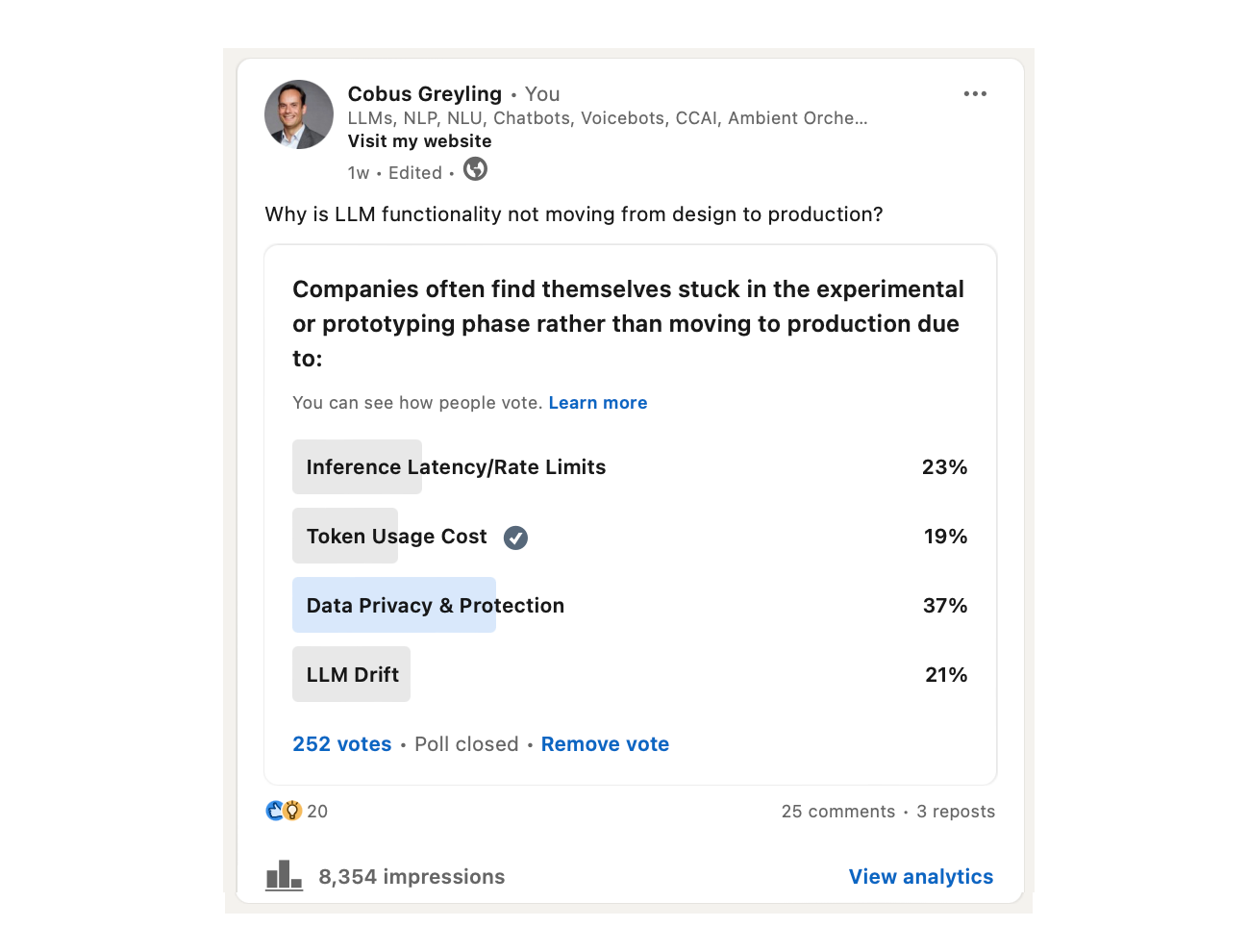
In a recent poll I ran on LinkedIn I asked what are the main impediments to implementing LLM functionality in enterprises.
As seen below, all of the elements listed below are indeed valid, and my initial feeling was that inference latency together with cost would be the main considerations.
However, as seen below, data privacy & data protection were top of mind to respondents. Followed by inference latency and rate limits.
LLM Drift
LLM drift has been highlighted by a number of studies, showing how commercial models change over a very short period of time (months). And how this change is not an improvement in performance, but rather a deprecation.
A solution to most, if not all, of these impediments would be to run a local instance of a LLM, and leveraging smaller and/or open-sourced models.
Recent studies have illustrated how smaller open-sourced models, often deemed inferior, yields on par and in some instances better performance by leveraging ICL (In-Context Learning).
The Case For Small Language Models
The initial allure of LLMs was their Knowledge Intensive (KI) nature, the idea that these KI-NLP systems can be asked any question and respond with an answer.
Subsequently users learned that LLMs does not have real-time knowledge, and that the base model training cut-off date, that models forget previously learned information. Something which is now termed as Catastrophic Forgetting (CF), and that models hallucinate.
Hallucination can best be described as the scenario where an LLM yields a highly succinct, plausible, contextual and believable answer. But, an answer which is not factually correct.
So we have learned that making use of Retrieval Augmented Generation (RAG), the in-context learning capability of LLMs can be leveraged.
So what if a smaller model can be run in a private environment?
Quantization
Quantization can best be described as a technique to reduce the computational and memory footprint and demands of running inference.
Inference is the process of interacting with a LLM/SLM, sending and receiving information.
Explaining quantization in simple terms, imagine you have a library with many books. And each book contains incredibly detailed information.
Quantization is like summarising those books into shorter, condensed versions that still capture the main ideas and key points.
These condensed books takes up less space on your bookshelf and is faster to read through.
Similarly, in LLMs, quantization simplifies the complex calculations and parameters of the model, making it more compact and faster to process while still retaining the essential information and capabilities.
Tools Of Titan
To prototype the idea of running a Small Language Model (SLM) locally and off-line on a MacBook, I made use of a model from HuggingFace.
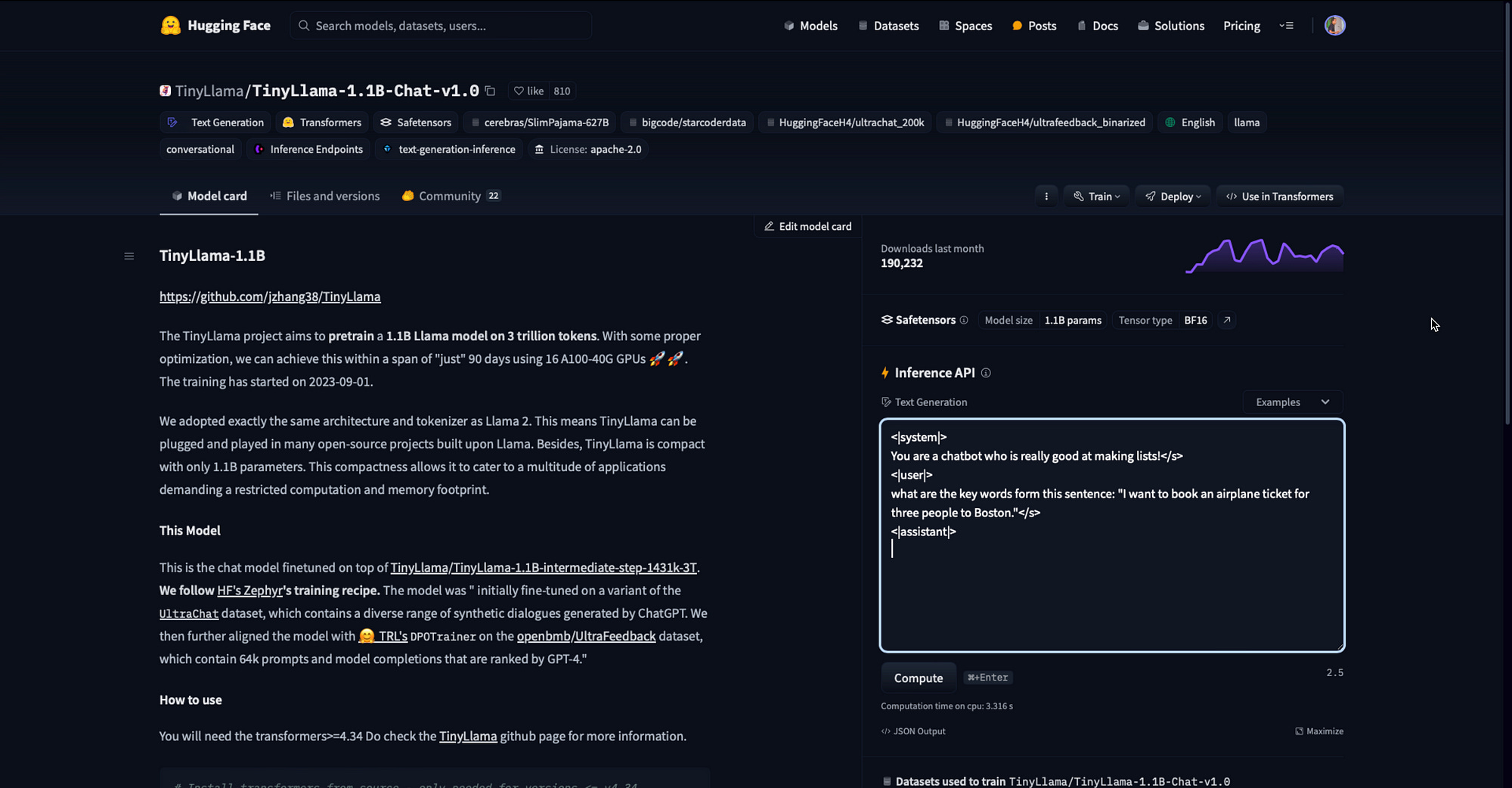
I also made use of the Titan TakeOff Inference Server, which I run locally on my MacBook.

Installing & Running Local Off-Line Inference
Titan has two options, one for CPU and one for GPU. I made use of the CPU option, running the inference server on a MacBook with an Apple M2 Pro chip.
The first step is to download and install Docker.
The next step is to log into the TitanML DockerHub, pull the container and start the Takeoff inference server.
I put the following text into a file called tytn.sh:
docker run -it \
-e TAKEOFF_MODEL_NAME=TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
-e TAKEOFF_DEVICE=cpu \
-e LICENSE_KEY=<INSERT_LICENSE_KEY_HERE> \
-e TAKEOFF_MAX_SEQUENCE_LENGTH=128 \
-p 3000:3000 \
-p 3001:3001 \
-v ~/.model_cache:/code/models \
tytn/takeoff-pro:0.11.0-cpuYou will need a license key to run the inference server. Titan will start offering a free trial open soon.
Once I run the sh tytn.sh command from a terminal window, the Titan Takeoff Inference server starts up, as shown below.

The easiest to start experimenting with the inference server is the Titan Playground, running locally on
http://localhost:3000/#/playground.
Below is the playground, there is a Complete Mode, as seen below, and also a Chat Mode.
You can see I defined a system prompt, describing the chatbot persona and purpose, with the user input. The assistant response was then generated.

Apart from metrics and reporting, the Takeoff playground has a model memory usage calculator, to help you estimate the memory footprint of models for different precisions and the maximum batch size / sequence length combination you can run on your device.

Conclusion
Considering the current research areas and challenges, I believe there are four key focus areas for future opportunities in Language Models:
Enabling offline and local operation of LLM/SLMs addresses issues like inference latency, rate limits, token cost, data privacy and protection, LLM Drift, and model independence. This includes facilitating easy fine-tuning and model customisation.
Developing methods and frameworks to harness the In-Context Learning (ICL) capabilities of LLM/SLMs. This involves exploring variations on RAG and optimising avenues for data delivery. Data Delivery encompasses the processes of discovery, design/structuring, and development of enterprise data for inference.
Defining clear use cases and business cases that justify enterprise implementations and demonstrate potential cost savings. This should illustrate the differentiation of LLM/GenAI from a business perspective.
Autonomous Agents
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.