Large Language Model (LLM) Disruption of Chatbots
To understand the disruption and demands Large Language Models will place on the Conversational AI/UI ecosystem going forward, considering the recent past helps and what vulnerabilities have emerged.

Traditionally the chatbot architecture and tooling were very much settled on four pillars:
Intents and entities combined constituted the NLU component.
This settled architecture has been disrupted by the advent of voicebots and Large Language Models (LLMs).
The Voice Disruption
The market requirement to automate voice calls originating from a telephone call placed to a contact centre, necessitated chatbot vendors to branch out into voicebots.
Voice as a medium demands two pieces of highly specialised technology:
Automatic Speech Recognition (ASR, Speech To Text, STT) and
Speech Synthesis (Text To Speech, TTS).
The voice focus also moved away from dedicated devices like Google Home and Alexa, to automated telephone calls.
This change in focus added complexity in the form of higher value conversations, calls with higher consequences, longer conversations with more dialog turns and complex conversation elements like self-correction, background noise and more. In short, customer support queries.
The Large Language Model (LLM) Disruption
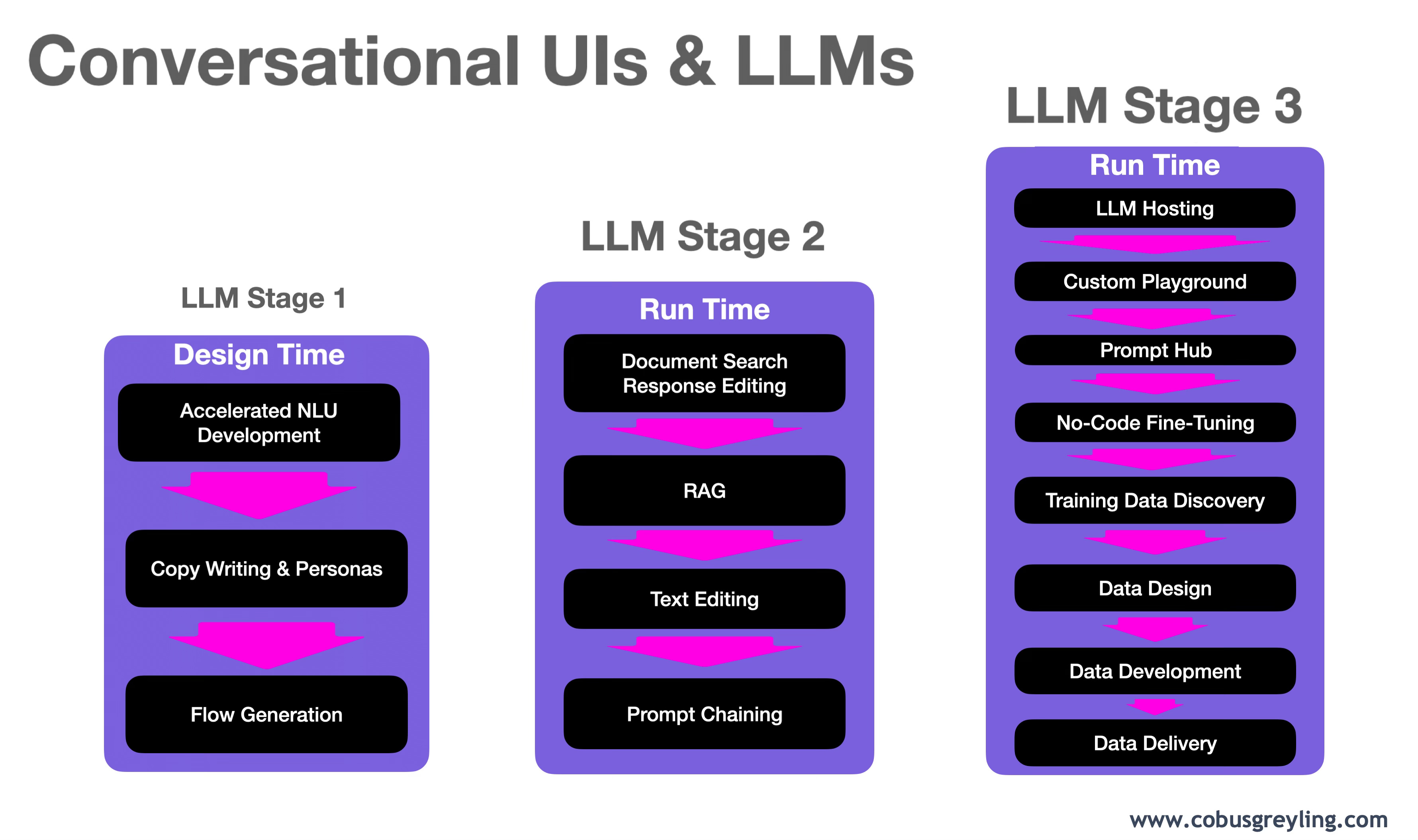
Large Language Models also disrupted the chatbot ecosystem, here I attempt to categorise the disruption in three stages.
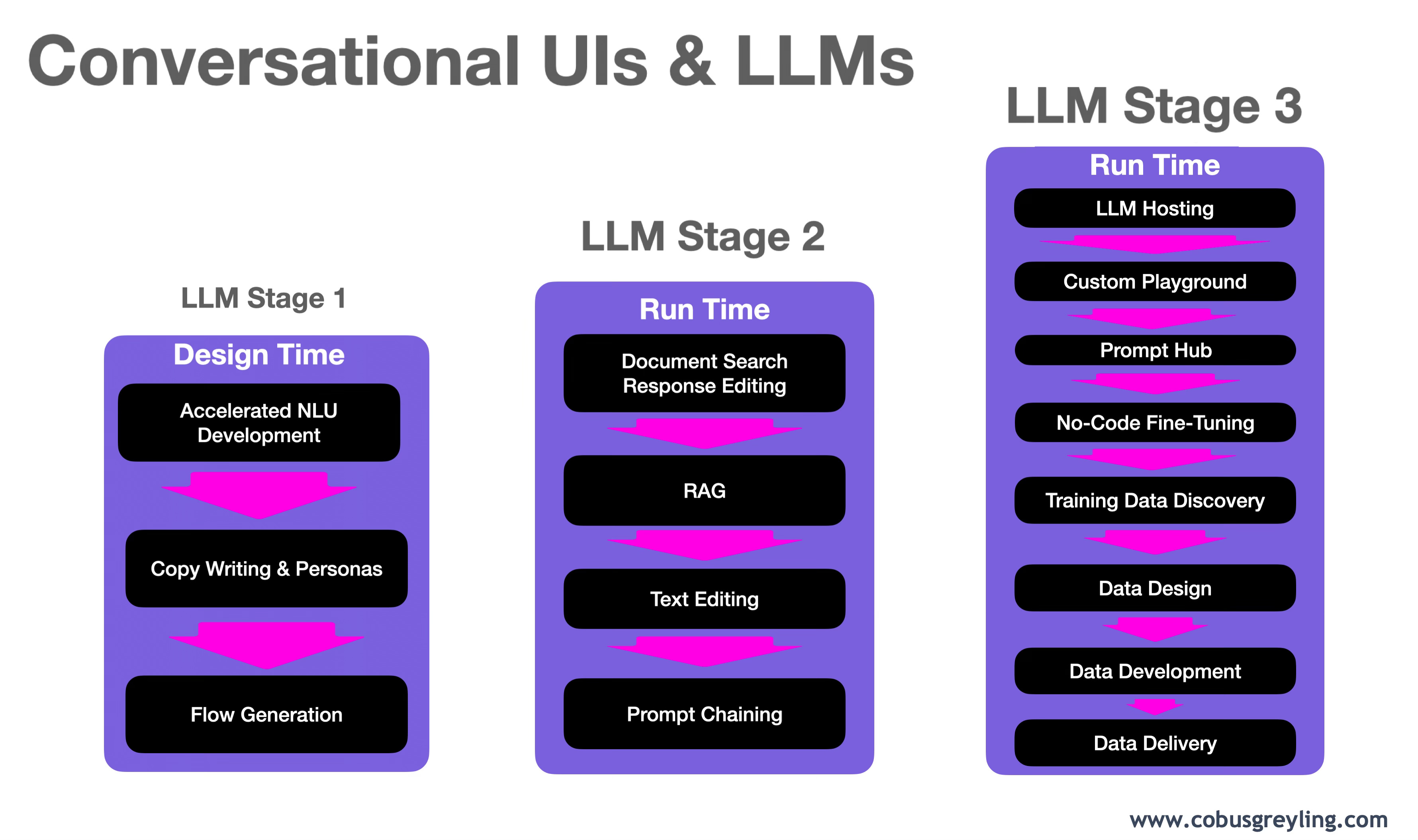
LLM Disruption: Stage One
Accelerated NLU Development
Stage one of LLM implementation focussed on the bot development process, and in specific accelerating NLU development.
What enabled the LLM Stage One disruption was that LLM functionality was introduced at design time as opposed to run time.
This meant that elements like inference latency, cost and LLM response aberrations could be confined to development and not exposed to production.
LLMs were introduced to assist with the development of NLU in the form of clustering existing customer utterances in semantically similar groupings for intent detection, generating intent training data, named entity recognition and more.
This accelerated the NLU development process and also made for more accurate NLU design data.
Copy Writing & Personas
The next phase of LLM disruption was to use LLMs / Generative AI for bot copy writing and to improve bot responses. This approach again was introduced at design time as opposed to run time, acting as an assistant to bot developers in crafting and improving their bot response copy.
Designers could also describe to the LLM a persona, tone and other traits of the bot in order to craft a consistent and succinct UI.
This is the tipping point where LLM assistance extended from design time to run time.
The LLM was used to generate responses on the fly and present it to the user. The first implementations used LLMs to answer out-of-domain questions, or craft succinct responses from document search and QnA.
LLMs were leveraged for the first time for:
Data & context augmented responses.
Natural Language Generation (NLG)
Dialog management; even though only for one or two dialog turns.
Stage one is very much focused on leveraging LLMs and Gen-AI at design time which has a number of advantages in terms of mitigating bad UX, cost, latency and any aberrations at inference.
The introduction of LLMs at design time was a safe avenue in terms of the risk of customer facing aberrations or UX failures. It was also a way to mitigate cost and spending and not face the challenges of customer and PII data being sent into the cloud.
Flow Generation
What followed was a more advanced implementation of LLMs and Generative AI (Gen-AI) with a developer describing to the bot how to develop a UI and what the requirements are for a specific piece of functionality.
And subsequently the development UI went off, leveraging LLMs and Generative AI, it generated the flow, with API place holders, variables required and NLU components.
LLM Disruption: Stage Two
Document Search & Response Editing
RAG
Text Editing
Prompt Chaining
Stage four of the LLM disruption was again at run time, where LLM functionality was introduced for RAG based search, Document based QnA, and prompt chaining.
One can add to this list formatting of API output data, for example:
Summarising longer pieces of text.
Extracting key points
Structuring data into a table, or a list, etc.
LLMs combined with company data and documents allows flexibility in terms of search and natural language generated responses.
Prompt Chaining found its way into Conversational AI development UIs, with the ability to create flow nodes consisting of one or more prompts being passed to a LLM. Longer dialog turns could be strung together with a sequence of prompts, where the output of one prompt serves as the input for another prompt.
Between these prompt nodes are decision and data processing nodes…so prompt nodes are very much analogous to traditional dialog flow creation, but with the flexibility so long yearned for.
LLM Disruption: Stage Three
LLM Introduced Challenges
In order for LLM and Gen-AI to move beyond stage four there are a number of impediments which will have to be overcome.
These challenges include:
Trust & Responsible AI
Enterprise Requirements
True Value Proposition
Trust & Responsible AI
Personal Identifiable information (PII) and other protection of private information legislation can only be complied with, when an organisation is able to have a private installation of a LLM within a private cloud or on-premise.
This will ensure the path information travels and used within a model can be subject to an audit with full accountability.
There is a dire need for a service where LLMs can be installed and run in a private environment.
Customer data passed to the LLM should not be used to train generally available LLMs and good data governance is paramount in underpinning trust and responsible AI.
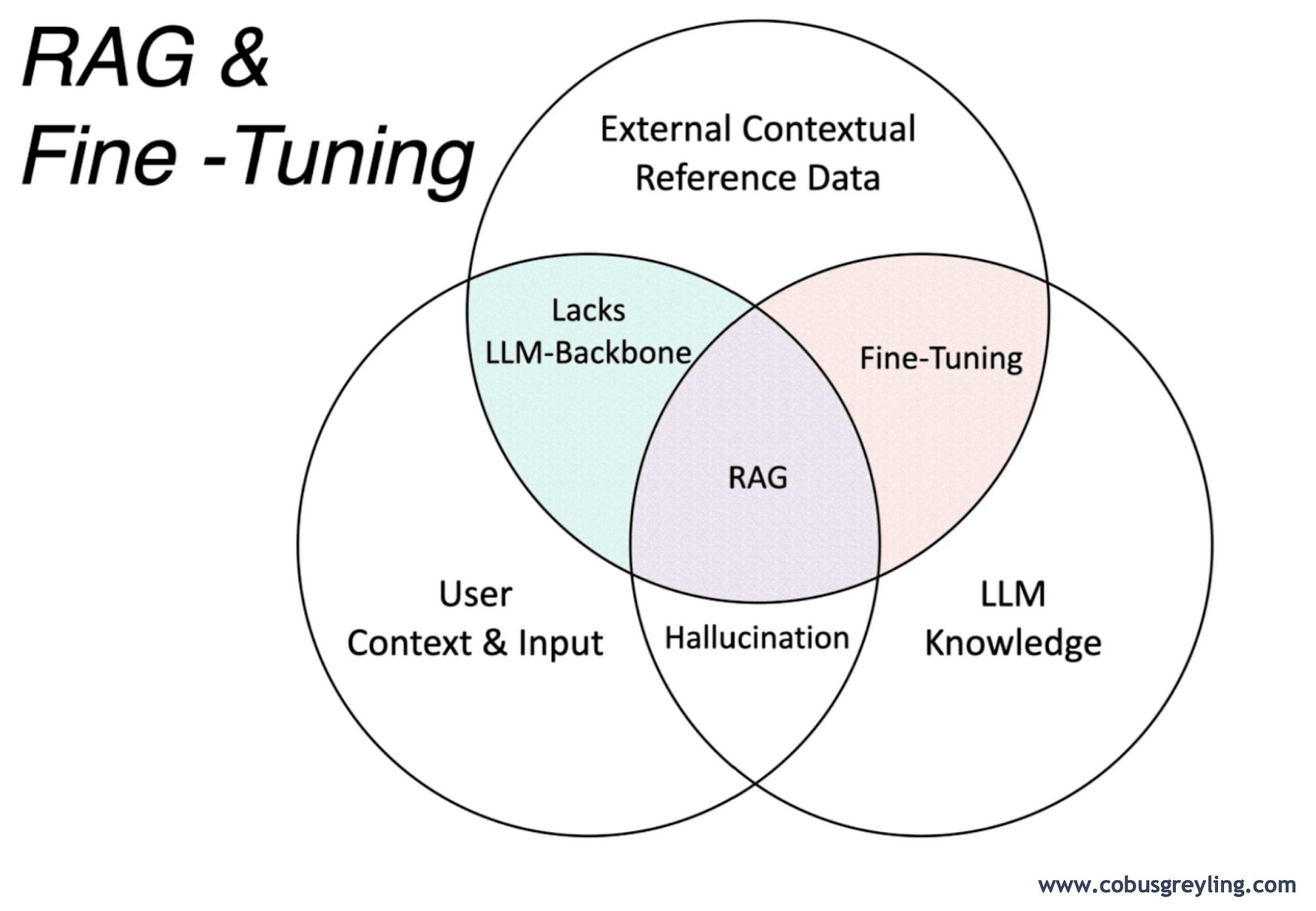
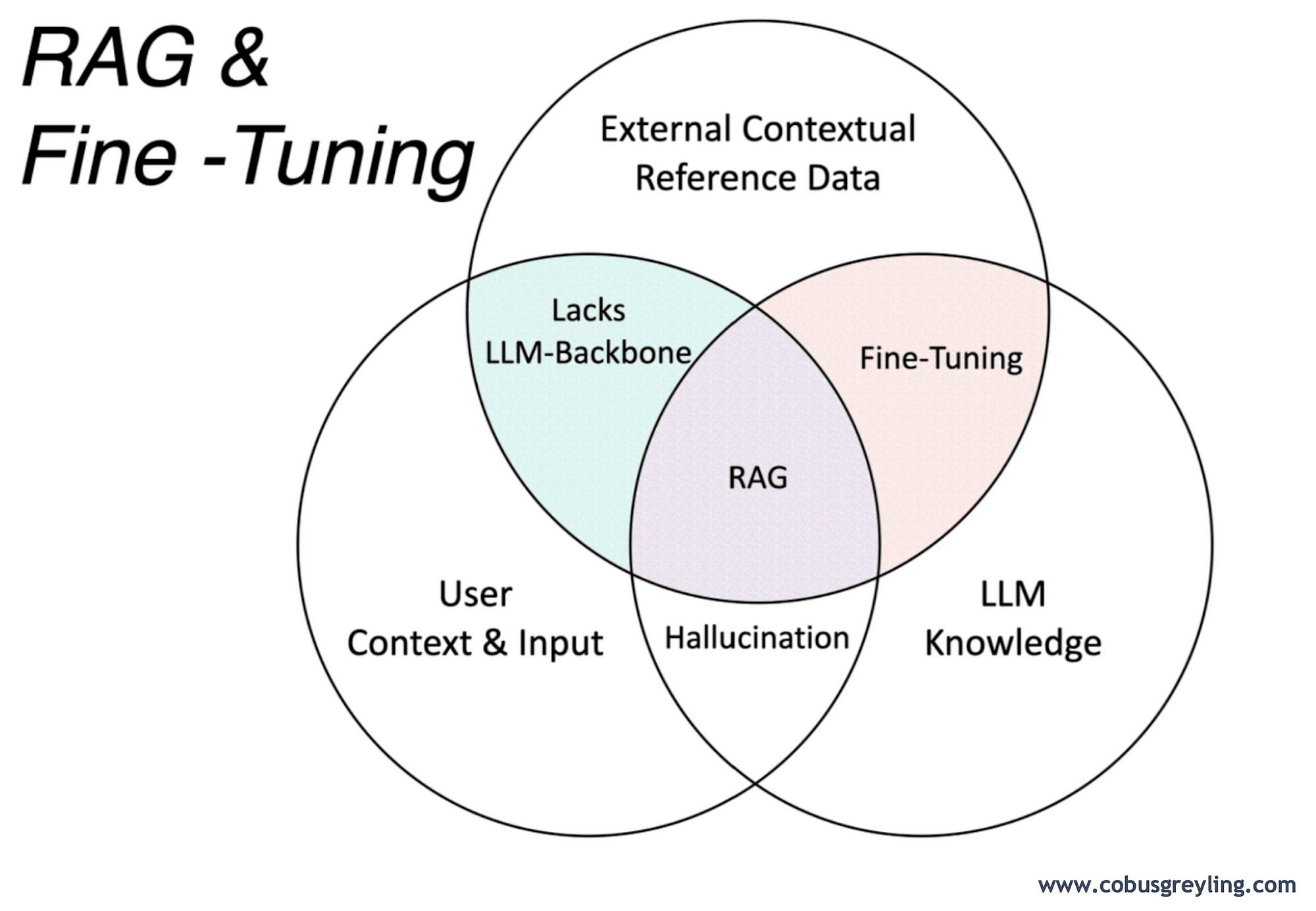
Accuracy in LLM response and the negation of model hallucination are dependant on two factors:
Fine-Tuning
Retrieval Augmented Generation (RAG).
Fine-Tuning relies on data which is relevant to the use-case; RAG relies on presenting the LLM with highly contextual information at inference time.
Enterprise Requirements
Enterprise requirements include a low-code to no-code environment, with manageable and forecastable costs, integration to existing enterprise processes and systems and more.
Highly manageable hosting is also important.
LLMs provide enterprises with an opportunity to leverage data productivity. Data can be put to work and leveraged via LLMs for fine-tuning, RAG and vector databases. Data productivity can also be defined as a process of data discovery; data discovery entails the detection of clusters and semantic similarities within data.
True Value Proposition
The UI must be no-code to low-code, underpinned by an intuitive and simplistic UI. The challenge is that as complexity and flexibility grows, the UI should still be easy to navigate. Production use will demand granular control and the tension between UI simplicity, solution flexibility, complex implementation and granular management will have to be managed well.
Opportunities
There is a dire market need for a comprehensive LLM Productivity Platform.
Three significant opportunities and current market vulnerabilities can be found in the areas of Prompt Engineering, Application Flows and Fine Tuning (custom models). With all of these available via a no-code to low-code interface.
It needs to be kept in mind that enterprises want to reach a level of large language model independence, where they are not at the behest of model suppliers. This can be achieved in three ways.
Organisations can install and train one or more custom LLM on premise or a private cloud.
Highly contextual reference data at inference allows for smaller and less capable LLMs to yield good results. By establishing a mature data pipeline and RAG infrastructure LLM independence can also be achieved.
Creating robust and well defined prompts. Various studies have shown that different prompt techniques can be used to leverage LLMs for good results.
Prompt Engineering Via A Playground
The market is ready for a no-code prompt engineering platform, giving users access to a prompt hub with a host of prompts for different scenarios. A library of sorts where prompts can be searched, tested, updated etc.
Different modes are important, OpenAI is pushing the chat mode quite a bit. This is due to the inherent input data structure the chat mode offers. However, the edit and completion modes are also of value and a non-structured input is often easier to create.
The playground must also give access to a host of models; with the option to create multiple panes where the same prompt can be run against multiple models. Access to open-sourced models and lesser known models is a first step in the direction of being model agnostic, and treating LLMs as a utility.
Application Flows
The natural outflow is for users to want to expand their prompt engineering functionality into broader applications. Building application flows can be via a GUI design canvas where design elements can be used to build flows.
Adding to this, an option to create RAG implementations via a no-code GUI, for uploaded documents which are automatically chunked, indexed in a vector store and made available for semantic search is also of great value.
LLM based solutions should not replace traditional chatbot functionality, but rather augment chatbot functionality with the principle of better together.
LLM based application flows must be available via APIs and act as micro flows or smart APIs within the traditional chatbot development framework. Flows should be able to reference various prompts and LLMs at various stages.
Fine-Tuning & Hosting
In recent times RAG has been pitted against model fine-tuning, the Venn Diagram below shows the overlaps between fine-tuning and RAG. The truth is that enterprises need a combination of RAG and fine-tuning.
Fine-tuning can be made easy for organisations via a no-code environment.
Data Discovery
Data design is the process of identifying any data within an enterprise which can be used for LLM fine-tuning. The best place to start is with existing customer conversations from the contact centre which can be voice or text based. Other good sources of data to discover are customer emails, previous chats and more.
This data should be discovered via an AI accelerated data productivity tool (latent space) where customer utterances are grouped according to semantic similarity, These clusters can be visually represented as seen below, which are really intents or classification; and classifications are still important for LLMs.
LLMs have two components, generative and predictive. The generative side has received most of the attention of late, but data discovery is important for both approaches.

Below is an example of a text based data discovery tool where utterances are discovered and semantic similarity, traits and conversation types are identified.

Data Design
Data design is the next step where the discovered data is transformed into the format required for LLM fine-tuning. The data needs to be structured and formatted in a specific way to serve as optional training data. The design phase compliments the discovery phase, at this state we know what data is important and will have the most significant impact on the users and customers.
Hence data design has two sides, the actual technical formatting of data and also the actual content and semantics of the training data.
Data Development (Observability)
This step entails the operational side of continuous monitoring and observing of customer behaviour and data performance. Data can be developed by augmenting training data with observed vulnerabilities in the model.
Data Delivery
Lastly, data delivery is the mode through which the data is delivered to the LLM, this can be fine-tuning, RAG, etc. This is the most efficient way contextual, reference data can be introduced at inference to aid the LLM.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.

Introduction & Background
Traditionally the chatbot architecture and tooling were very much settled on four pillars:
Intents and entities combined constituted the NLU component.
This settled architecture has been disrupted by the advent of voicebots and Large Language Models (LLMs).
The Voice Disruption
The market requirement to automate voice calls originating from a telephone call placed to a contact centre, necessitated chatbot vendors to branch out into voicebots.
Voice as a medium demands two pieces of highly specialised technology:
Automatic Speech Recognition (ASR, Speech To Text, STT) and
Speech Synthesis (Text To Speech, TTS).
The voice focus also moved away from dedicated devices like Google Home and Alexa, to automated telephone calls.
This change in focus added complexity in the form of higher value conversations, calls with higher consequences, longer conversations with more dialog turns and complex conversation elements like self-correction, background noise and more. In short, customer support queries.
The Large Language Model (LLM) Disruption
Large Language Models also disrupted the chatbot ecosystem, here I attempt to categorise the disruption in three stages.
LLM Disruption: Stage One
Accelerated NLU Development
Stage one of LLM implementation focussed on the bot development process, and in specific accelerating NLU development.
What enabled the LLM Stage One disruption was that LLM functionality was introduced at design time as opposed to run time.
This meant that elements like inference latency, cost and LLM response aberrations could be confined to development and not exposed to production.
LLMs were introduced to assist with the development of NLU in the form of clustering existing customer utterances in semantically similar groupings for intent detection, generating intent training data, named entity recognition and more.
This accelerated the NLU development process and also made for more accurate NLU design data.
Copy Writing & Personas
The next phase of LLM disruption was to use LLMs / Generative AI for bot copy writing and to improve bot responses. This approach again was introduced at design time as opposed to run time, acting as an assistant to bot developers in crafting and improving their bot response copy.
Designers could also describe to the LLM a persona, tone and other traits of the bot in order to craft a consistent and succinct UI.
This is the tipping point where LLM assistance extended from design time to run time.
The LLM was used to generate responses on the fly and present it to the user. The first implementations used LLMs to answer out-of-domain questions, or craft succinct responses from document search and QnA.
LLMs were leveraged for the first time for:
Data & context augmented responses.
Natural Language Generation (NLG)
Dialog management; even though only for one or two dialog turns.
Stage one is very much focused on leveraging LLMs and Gen-AI at design time which has a number of advantages in terms of mitigating bad UX, cost, latency and any aberrations at inference.
The introduction of LLMs at design time was a safe avenue in terms of the risk of customer facing aberrations or UX failures. It was also a way to mitigate cost and spending and not face the challenges of customer and PII data being sent into the cloud.
Flow Generation
What followed was a more advanced implementation of LLMs and Generative AI (Gen-AI) with a developer describing to the bot how to develop a UI and what the requirements are for a specific piece of functionality.
And subsequently the development UI went off, leveraging LLMs and Generative AI, it generated the flow, with API place holders, variables required and NLU components.
LLM Disruption: Stage Two
Document Search & Response Editing
RAG
Text Editing
Prompt Chaining
Stage four of the LLM disruption was again at run time, where LLM functionality was introduced for RAG based search, Document based QnA, and prompt chaining.
One can add to this list formatting of API output data, for example:
Summarising longer pieces of text.
Extracting key points
Structuring data into a table, or a list, etc.
LLMs combined with company data and documents allows flexibility in terms of search and natural language generated responses.
Prompt Chaining found its way into Conversational AI development UIs, with the ability to create flow nodes consisting of one or more prompts being passed to a LLM. Longer dialog turns could be strung together with a sequence of prompts, where the output of one prompt serves as the input for another prompt.
Between these prompt nodes are decision and data processing nodes…so prompt nodes are very much analogous to traditional dialog flow creation, but with the flexibility so long yearned for.
LLM Disruption: Stage Three
LLM Introduced Challenges
In order for LLM and Gen-AI to move beyond stage four there are a number of impediments which will have to be overcome.
These challenges include:
Trust & Responsible AI
Enterprise Requirements
True Value Proposition
Trust & Responsible AI
Personal Identifiable information (PII) and other protection of private information legislation can only be complied with, when an organisation is able to have a private installation of a LLM within a private cloud or on-premise.
This will ensure the path information travels and used within a model can be subject to an audit with full accountability.
There is a dire need for a service where LLMs can be installed and run in a private environment.
Customer data passed to the LLM should not be used to train generally available LLMs and good data governance is paramount in underpinning trust and responsible AI.
Accuracy in LLM response and the negation of model hallucination are dependant on two factors:
Fine-Tuning
Retrieval Augmented Generation (RAG).
Fine-Tuning relies on data which is relevant to the use-case; RAG relies on presenting the LLM with highly contextual information at inference time.
Enterprise Requirements
Enterprise requirements include a low-code to no-code environment, with manageable and forecastable costs, integration to existing enterprise processes and systems and more.
Highly manageable hosting is also important.
LLMs provide enterprises with an opportunity to leverage data productivity. Data can be put to work and leveraged via LLMs for fine-tuning, RAG and vector databases. Data productivity can also be defined as a process of data discovery; data discovery entails the detection of clusters and semantic similarities within data.
True Value Proposition
The UI must be no-code to low-code, underpinned by an intuitive and simplistic UI. The challenge is that as complexity and flexibility grows, the UI should still be easy to navigate. Production use will demand granular control and the tension between UI simplicity, solution flexibility, complex implementation and granular management will have to be managed well.
Opportunities
There is a dire market need for a comprehensive LLM Productivity Platform.
Three significant opportunities and current market vulnerabilities can be found in the areas of Prompt Engineering, Application Flows and Fine Tuning (custom models). With all of these available via a no-code to low-code interface.
It needs to be kept in mind that enterprises want to reach a level of large language model independence, where they are not at the behest of model suppliers. This can be achieved in three ways.
Organisations can install and train one or more custom LLM on premise or a private cloud.
Highly contextual reference data at inference allows for smaller and less capable LLMs to yield good results. By establishing a mature data pipeline and RAG infrastructure LLM independence can also be achieved.
Creating robust and well defined prompts. Various studies have shown that different prompt techniques can be used to leverage LLMs for good results.
Prompt Engineering Via A Playground
The market is ready for a no-code prompt engineering platform, giving users access to a prompt hub with a host of prompts for different scenarios. A library of sorts where prompts can be searched, tested, updated etc.
Different modes are important, OpenAI is pushing the chat mode quite a bit. This is due to the inherent input data structure the chat mode offers. However, the edit and completion modes are also of value and a non-structured input is often easier to create.
The playground must also give access to a host of models; with the option to create multiple panes where the same prompt can be run against multiple models. Access to open-sourced models and lesser known models is a first step in the direction of being model agnostic, and treating LLMs as a utility.
Application Flows
The natural outflow is for users to want to expand their prompt engineering functionality into broader applications. Building application flows can be via a GUI design canvas where design elements can be used to build flows.
Adding to this, an option to create RAG implementations via a no-code GUI, for uploaded documents which are automatically chunked, indexed in a vector store and made available for semantic search is also of great value.
LLM based solutions should not replace traditional chatbot functionality, but rather augment chatbot functionality with the principle of better together.
LLM based application flows must be available via APIs and act as micro flows or smart APIs within the traditional chatbot development framework. Flows should be able to reference various prompts and LLMs at various stages.
Fine-Tuning & Hosting
In recent times RAG has been pitted against model fine-tuning, the Venn Diagram below shows the overlaps between fine-tuning and RAG. The truth is that enterprises need a combination of RAG and fine-tuning.
Fine-tuning can be made easy for organisations via a no-code environment.
Data Discovery
Data design is the process of identifying any data within an enterprise which can be used for LLM fine-tuning. The best place to start is with existing customer conversations from the contact centre which can be voice or text based. Other good sources of data to discover are customer emails, previous chats and more.
This data should be discovered via an AI accelerated data productivity tool (latent space) where customer utterances are grouped according to semantic similarity, These clusters can be visually represented as seen below, which are really intents or classification; and classifications are still important for LLMs.
LLMs have two components, generative and predictive. The generative side has received most of the attention of late, but data discovery is important for both approaches.
Below is an example of a text based data discovery tool where utterances are discovered and semantic similarity, traits and conversation types are identified.

{kind=link}
Data Design
Data design is the next step where the discovered data is transformed into the format required for LLM fine-tuning. The data needs to be structured and formatted in a specific way to serve as optional training data. The design phase compliments the discovery phase, at this state we know what data is important and will have the most significant impact on the users and customers.
Hence data design has two sides, the actual technical formatting of data and also the actual content and semantics of the training data.
Data Development (Observability)
This step entails the operational side of continuous monitoring and observing of customer behaviour and data performance. Data can be developed by augmenting training data with observed vulnerabilities in the model.
Data Delivery
Lastly, data delivery is the mode through which the data is delivered to the LLM, this can be fine-tuning, RAG, etc. This is the most efficient way contextual, reference data can be introduced at inference to aid the LLM.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.