Large Language Model Programs
A recent study named Large Language Model Programs explores how LLMs can be implemented in applications.

Intro
The basic premise of the study is to abstract the application logic away from a prompt chaining approach and only access LLM APIs as and when required.
This approach also discards to some degree model fine-tuning in favour of in-context learning (ICL).
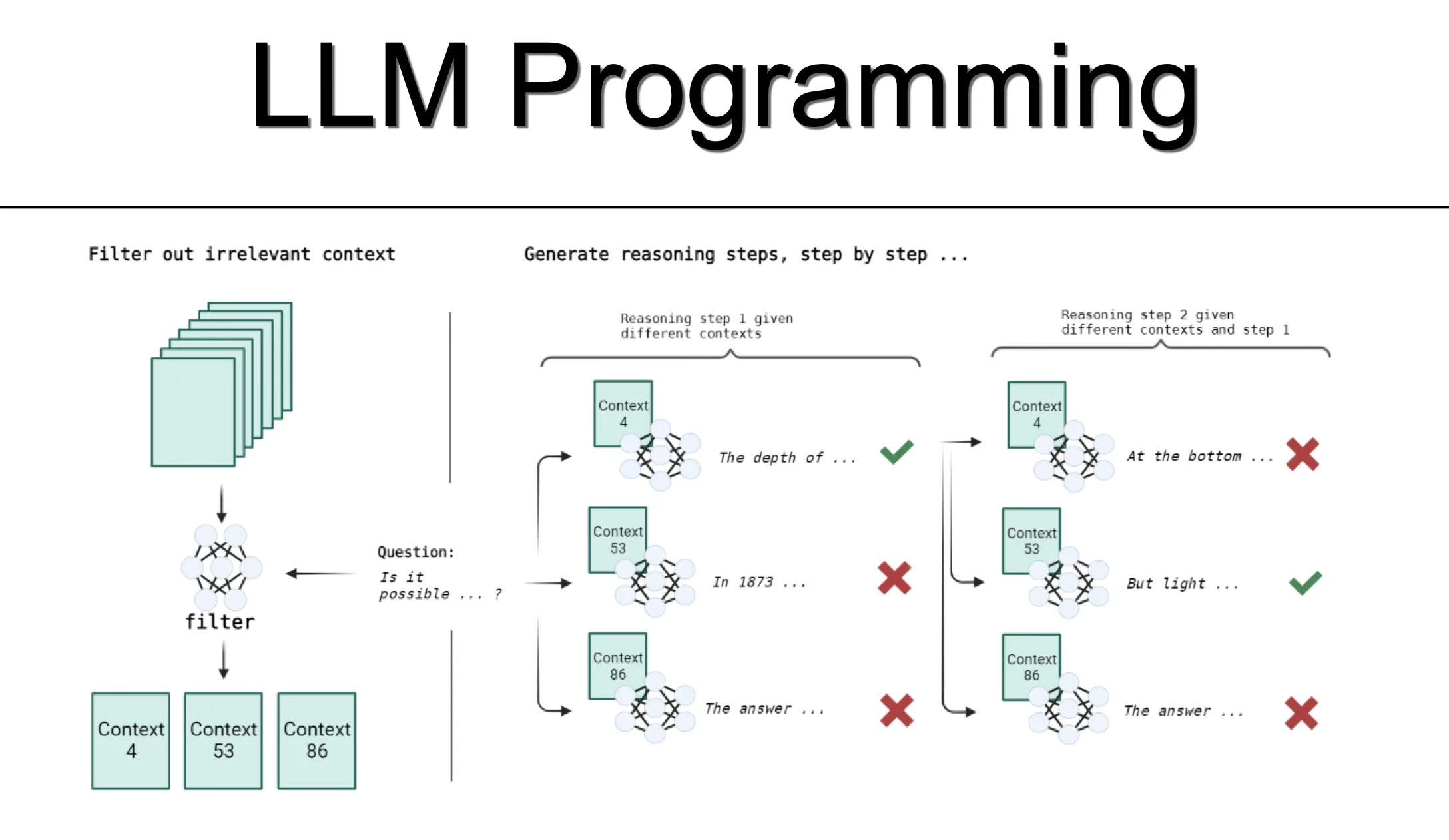
Although not described as RAG, the study’s approach of retrieving relevant and filtering content prior to LLM inference is analogous to RAG.
Subsequently, on a prompt level, the reasoning steps are created via decomposition, again this is very much analogous to Chain-Of-Thought.
The third step in the proposed sequence, again resembles the Self-Consistency CoT aproach.
More On The Study’s Approach
One important distinction of the LLM Programs study from previous implementations, is that one or more LLMs do not form part of a conversational UI per se, but any application, like a website for instance.
Hence the state management of the program is not managed and maintained by the LLM, but rather the LLM is only involved as needed.
The study sees one of the advantages, that only contextual information from that particular step is included in each LLM call.
There are some advantages listed in the study, even-though the principle of RAG has been proven many times over, together with the principle of decomposition coined as the Chain-Of-X Phenomenon.
The Chain-Of-X Phenomenon In LLM Prompting
Some of the key findings from the study are:
Contextual reference data at inference can suffice in the absence of fine-tuning.
High-level information can be handled by LLMs via breaking down a complex task into multiple sub-tasks with little or no training.
Granular input and output allows for more manageable and systematic evaluation of LLMs. Hence there is a higher level of inspectability and observability of data input and output.
LLM performance can be performed via testing subsets of certain routines in isolation, even via manual inspection.
Concessions
This approach does necessitate some concessions, especially on the front of flexibility.
The study suggests a framework which embeds an LLM within a program, and which includes a safety mechanism which filters out unwanted LLM responses.
Embedding an LLM within a task-independent program that is responsible to select and load relevant documents into context or which summarises past text may serve as a way of overcoming such limitations.
The study states:
It is central to this method to decompose the main problem recursively into subproblems until they can be solved by a single query to the model.
This approach will definitely require a framework of sorts to programatically perform a recursive approach, iterating over subproblems until the final answer is reached.
Finally
I read multiple papers on a daily basis; what I find interesting, is that one starts to form a general perception of what are becoming accepted norms and standards.
Especially in the case of LLMs, there is an alignment starting to solidify on what is best practice for production implementations. This becomes evident when you read older studies and find how many of the ideas raised in the past are now superseded.
Take for instance the idea of fine-tuning a model. The introduction of new concepts have lead to fine-tuning being much more feasible than only a few months ago:
LLM providers are introducing no-code fine-tuning studios.
Training token cost and training time have come down considerably, making it more accessible.
In general the fine-tuning dashboard also improved on a few fronts. Users can immediately see what is wrong where, when a training file is uploaded. For instance, OpenAI will give you the line number and a description of where the file formatting error is.
The training status is updated and once training is completed the user receives an email and the custom trained model is visible via the playground.
To add to this, the dataset size required for effective fine-tuning has come down considerably.
Key elements for any LLM implementation are:
Makers must have a clear understanding of inherent LLM abilities versus prompting techniques available.
Highly scaleable and flexible LLM-based implementations can only be built using framework to manage the LLM interactions and prompts.
Gone are the days where the assumption is that all you need is one prompt and six lines of code.
Problem Decomposition and addressing sub-problems sequentially.
Data AI. Data Strategy > AI Strategy. Data plays a big role; enterprises will demand tools for data discovery, data design (structuring unstructured data), data development (augmenting identified relevant data). And lastly, data delivery.
Data delivery can be performed via prompt injection, prompt pipelines, prompt chaining, RAG, etc.etc.
Leverage LLMs to perform sampling strategies which improves Robustness for imperfect Prompts.
In-Context Learning
RAG
Fine-Tuned Models
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.