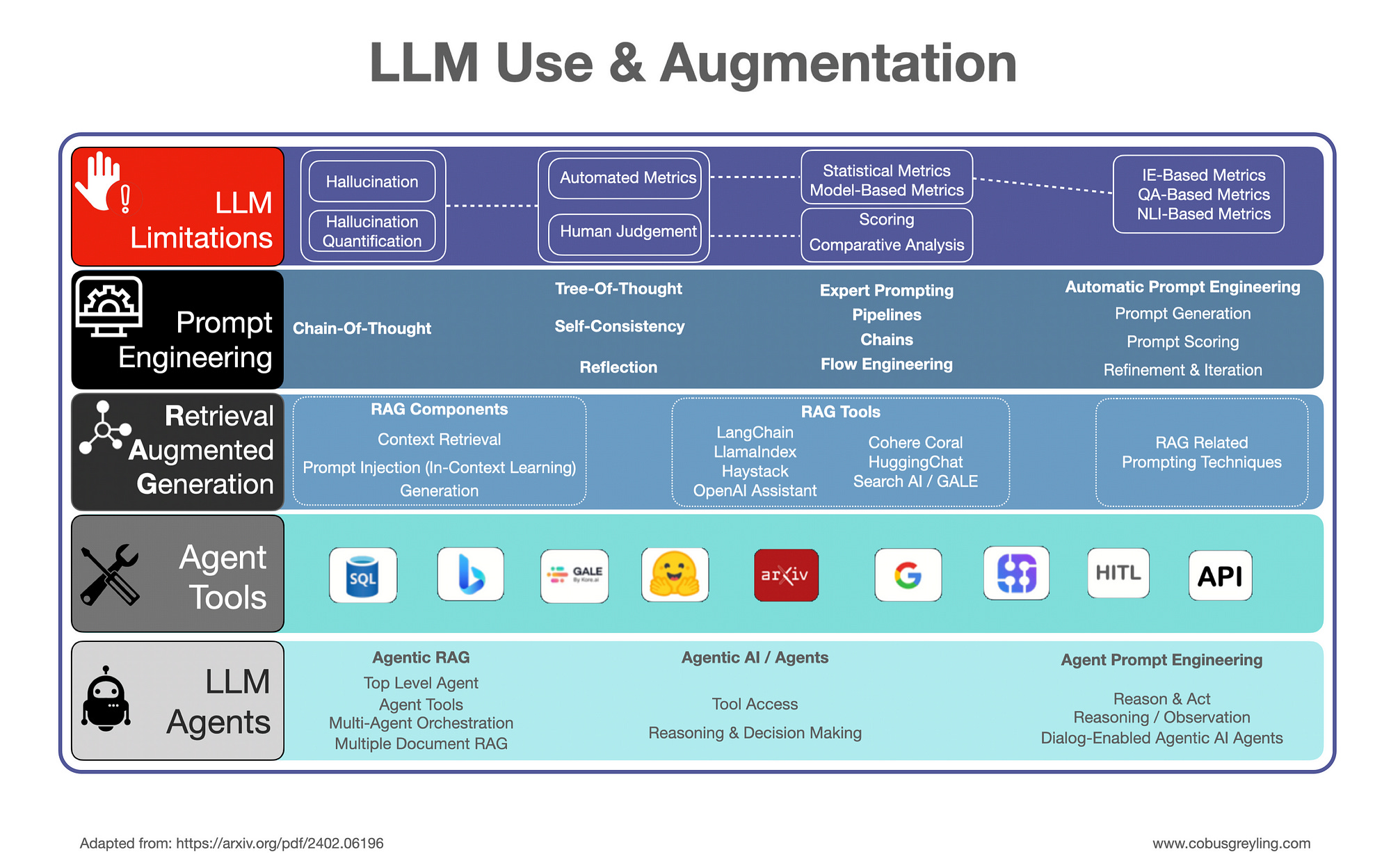
Large Language Model Use & Augmentation
GPT-3 was launched on May 28, 2020, and over the past four years, a rapidly developing ecosystem has emerged to create LLM-based solutions.

Introduction
As the potential and use of LLMs become relevant, there emerged a drive to develop applications and tools around LLMs. There is obviously also a significant business opportunity which is continuously unfolding.
However, while trying to harness LLMs and build applications with LLMs at the centre, it was discovered that LLMs have vulnerabilities. And solutions and frameworks had to be built to accommodate the vulnerabilities and support LLM and Generative AI application development.
And hence now we have a whole host of terms not known before, like RAG, ICL and others.
LLM Limitations
No Memory
LLMs can’t remember previous prompts, which limits their use in applications needing state retention. The same goes for maintaining context within a conversation. Hence methods of few-shot learning had to be implemented, summarising conversation history and injecting the prompts with the summary.
Or approaches like seeding had to be implemented, where a particular response can be replicated for a certain input.
Stochastic Responses
LLMs give different answers to the same prompt. Parameters like temperature can limit this variability, but it remains an inherent trait.
This can be good in the case of some conversational UIs, where level of liveness is required, simulating us as humans.
Outdated Information
LLMs can’t access current data or know the present time, relying only on their training data. Hence the notion of RAG, and retrieving highly contextually relevant information for each inference.
Large Size
LLMs require costly GPU resources for training and serving, leading to potential latency issues.
Here Small Language Models have come to the fore; SLMs have all the characteristics of LLMs, apart from their knowledge intensive nature. The knowledge intensive nature has been superseded by ICL and RAG. Hence SLMs are ideal for most solutions.
Hallucinations
LLMs can generate highly plausible, succinct and coherent answers, but answers which are factually incorrect.
These limitations, especially hallucinations, have sparked interest and led to various prompt engineering and LLM augmentation strategies.
Hallucinations in Large Language Models (LLMs)
In LLMs, hallucinations refer to the generation of nonsensical or unfaithful content.
This phenomenon has gained significant attention, particularly highlighted in the Survey of Hallucination in Natural Language Generation paper.
According to a recent study, hallucinations can be categorised as:
Intrinsic Hallucinations
These introduce factual inaccuracies or logical inconsistencies, directly conflicting with the source material.
Extrinsic Hallucinations
These are unverifiable against the source, involving speculative or unconformable elements.
The definition of source varies with the task.
In dialogues, it can refer to world knowledge, while in text summarisation, it pertains to the input text.
The context of hallucinations matters too; in creative writing, like poetry, they might be acceptable or even beneficial.
LLMs are trained on diverse datasets, including the internet, books, and Wikipedia, and generate text based on probabilistic models without an inherent understanding of truth.
Techniques like instruct tuning and Reinforcement Learning from Human Feedback (RLHF) aim to produce more factual outputs, but the inherent probabilistic nature remains a challenge.
Prompt Engineering: CoT
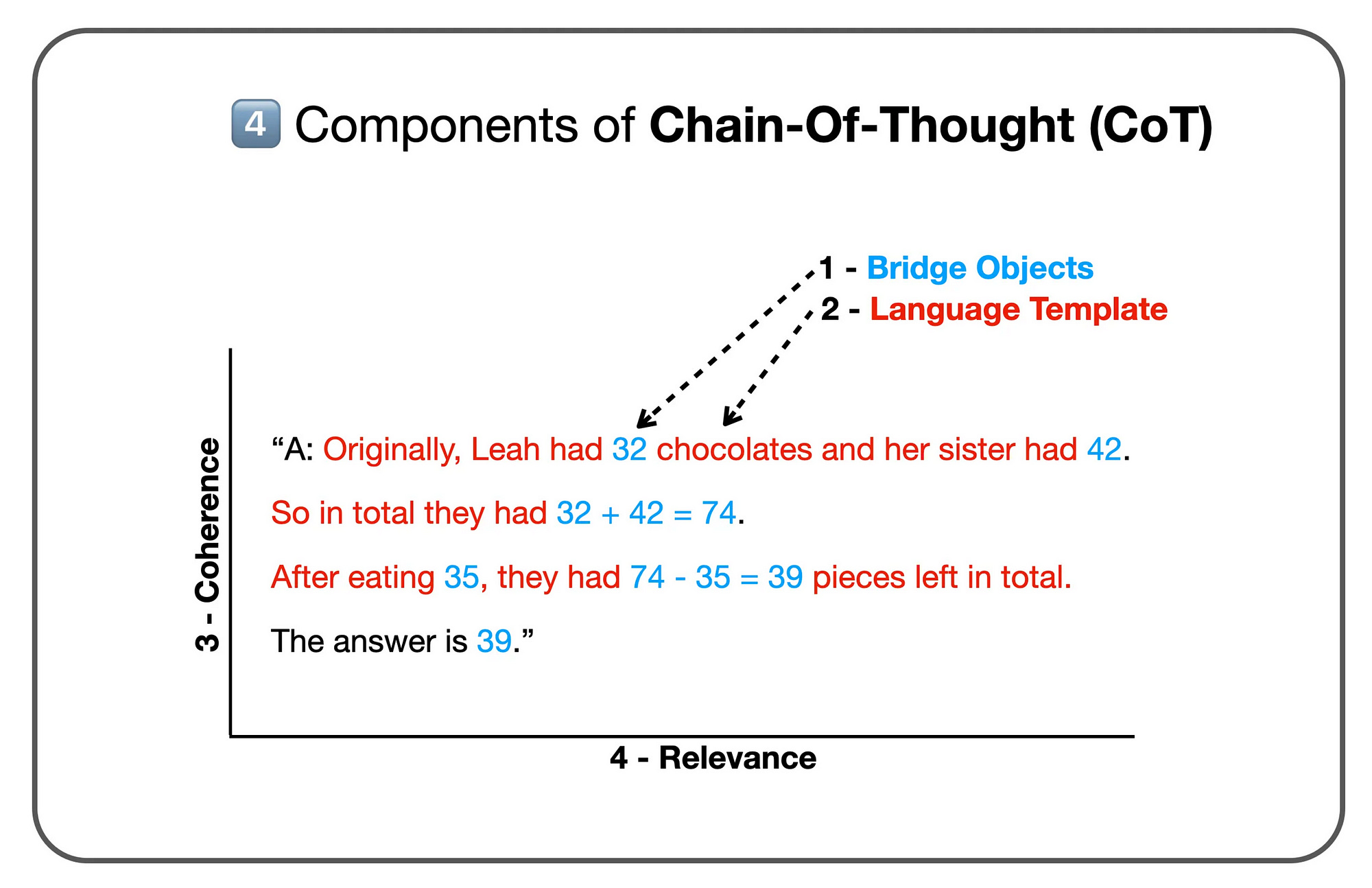
Chain-of-Thought (CoT) prompting makes the implicit reasoning process of LLMs explicit.
By breaking down the reasoning steps required to solve a problem, the model is guided towards more logical and reasoned outputs, particularly in tasks that require complex problem-solving or deeper understanding beyond simple information retrieval or pattern recognition.
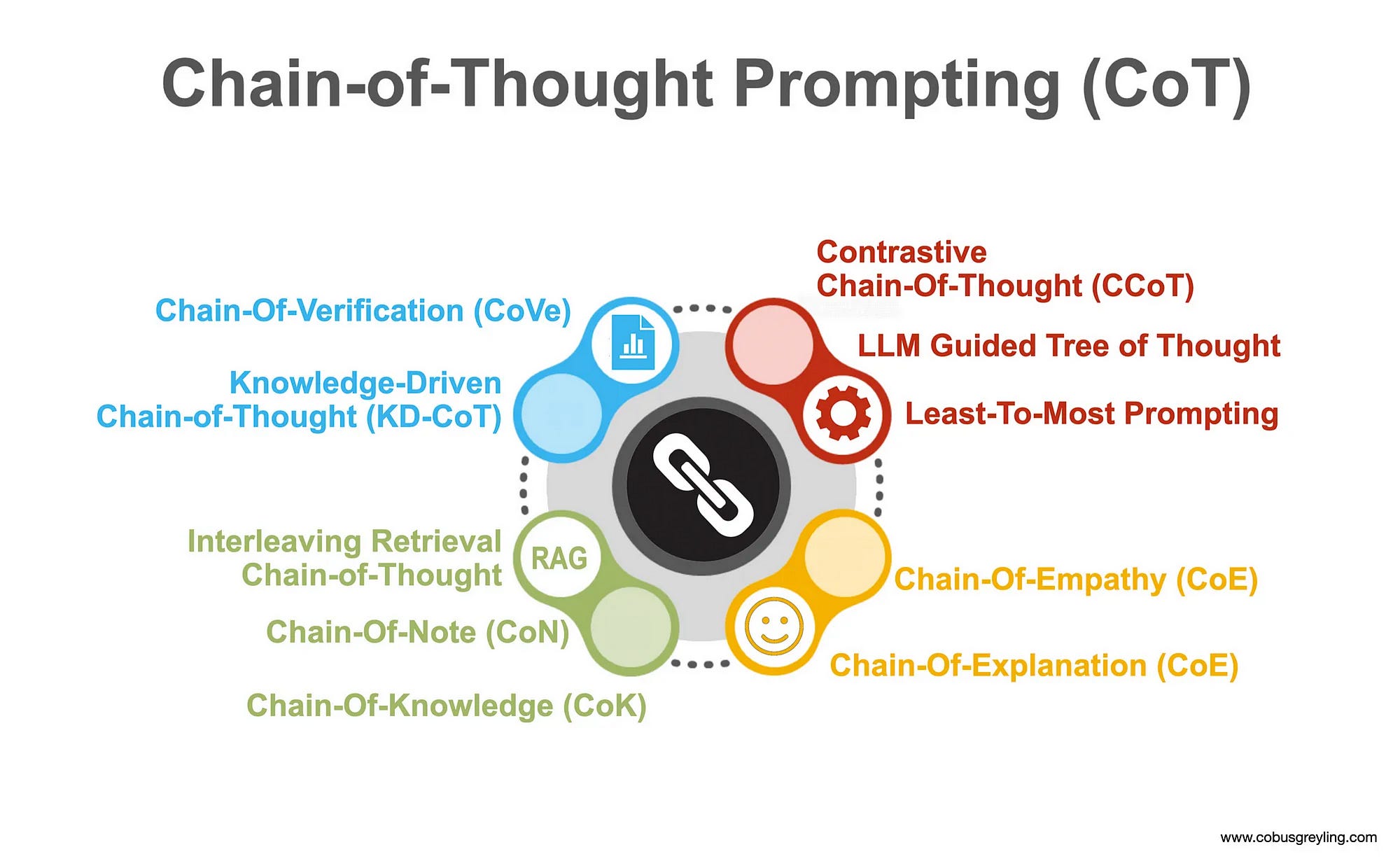
Chain-Of-X Phenomenon
Recently, various “Chain-Of-X” implementations have demonstrated how Large Language Models (LLMs) can break down complex problems into a series of intermediate steps. This concept, known as Chain-Of-X, originated from Chain-Of-Thought (CoT) prompting.
CoT prompting mirrors human problem-solving methods by decomposing larger problems into smaller steps. The LLM then addresses each sub-problem with focused attention, reducing the likelihood of overlooking crucial details or making incorrect assumptions. This Chain-Of-X approach has proven to be very effective in interacting with LLMs.
Tools & AI Agents
The concept of AI agents has been thoroughly explored in AI history. An agent is typically an autonomous entity that perceives its environment using sensors, makes judgments based on its current state, and acts accordingly.
In the context of LLMs, an agent refers to a specialised instantiation of an (augmented) LLM designed to perform specific tasks autonomously. These agents interact with users and the environment to make decisions based on input and intended goals. LLM-based agents can access and use tools and make decisions based on the given input, handling tasks requiring autonomy and decision-making beyond simple response generation.
The functionalities of a generic LLM-based agent include:
Tool Access and Utilisation
Agents can access and effectively use external tools and services to accomplish tasks.
Decision Making
They make decisions based on input, context, and available tools, often employing complex reasoning processes.
For example, an LLM with access to a weather API can answer weather-related questions for specific locations. Similarly, an LLM with access to a purchasing API can be built into a purchasing agent, capable of reading information from the external world and acting on it.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.