Large Language Models Are Forcing Conversational AI Frameworks To Look Outward
With fragmentation being forced on frameworks it will become increasingly hard to be self-contained. I also consider the strengths, opportunities, weaknesses and threats of LLMs.


Introduction
The last few days have seen a deluge of statements from companies announcing that their Conversational AI Framework is LLM enabled or leverages LLMs.
The irony is that many of the LLM implementations and use-cases are largely similar; with a few “use-cases” being very vague.
First some context, there are numerous Large Langauge Models (LLMs), also referred to as Foundation Models (FMs). These models have been around for a while, GPT-1 was released in 2018, BERT was also released in that year.
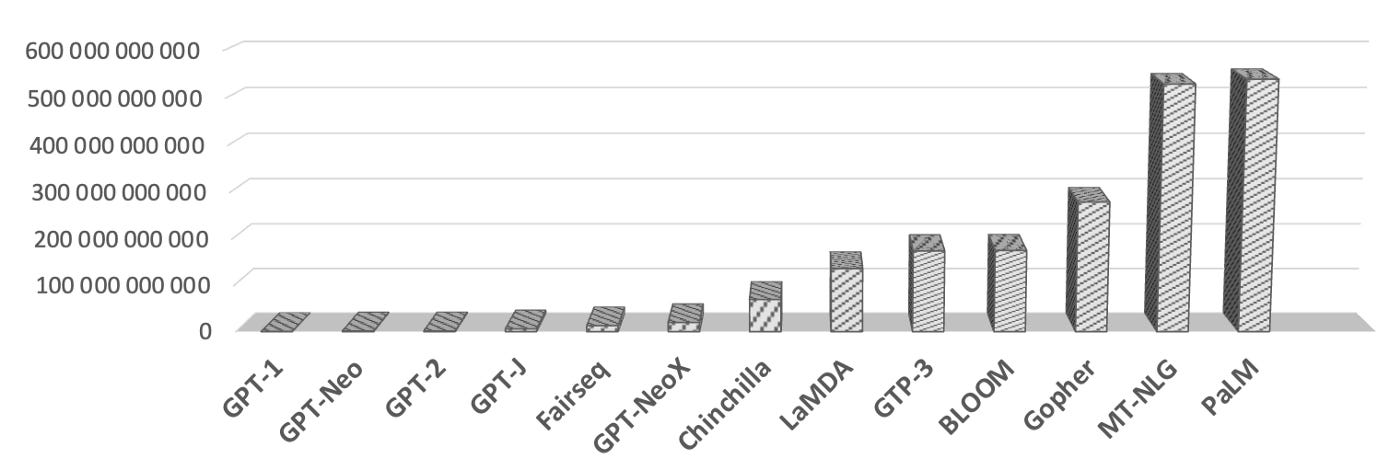
I get the sense that with the launch of text-davinci-3 and ChatGPT interest in LLMs has gone mainstream. And Conversational AI Frameworks (chatbot development frameworks) are scrambling to announce they are LLM-enabled. This follows a recent wave of announcements regarding being voiceenabled.
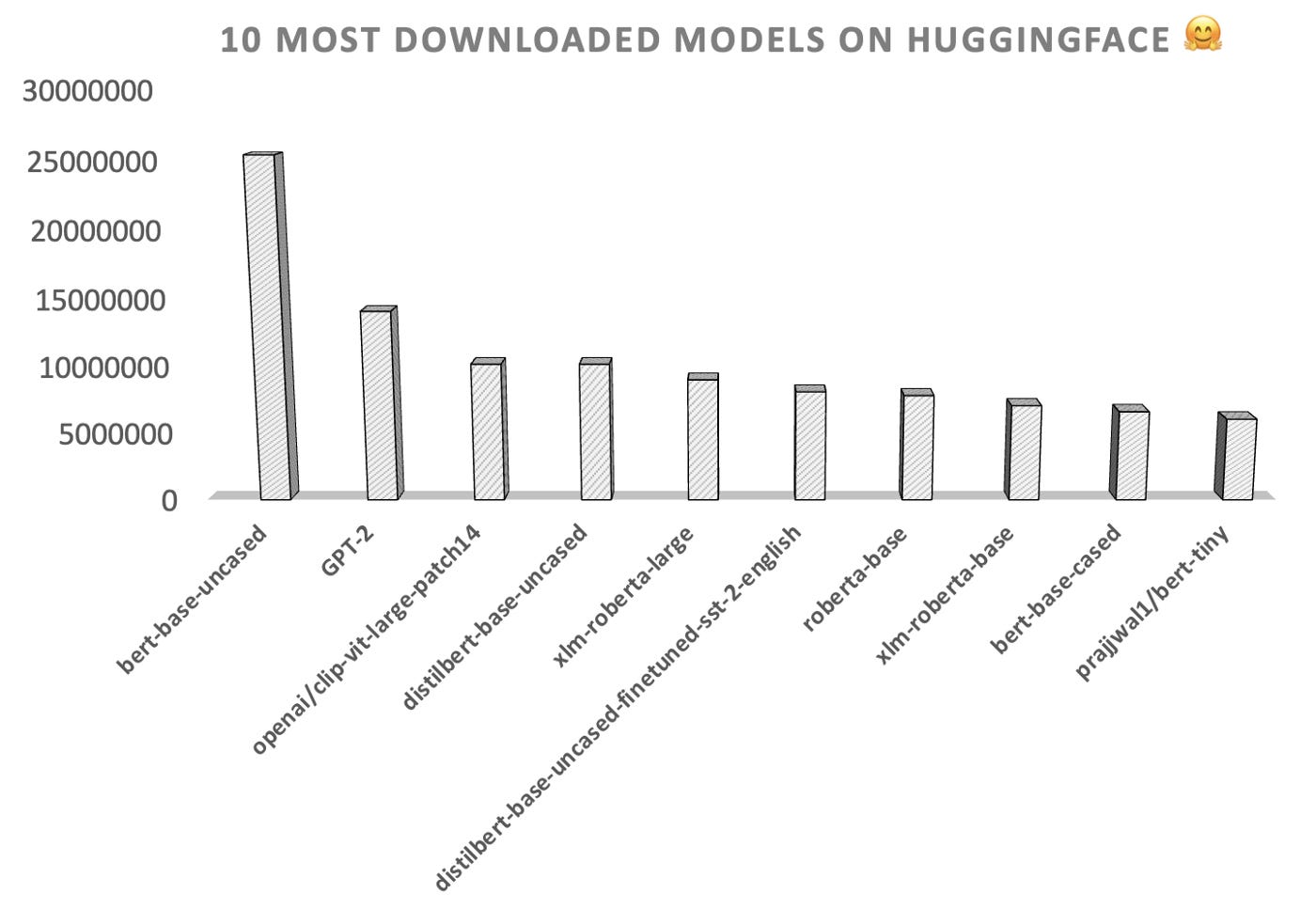
In the graph below are the top 10 most downloaded models on HuggingFace. It is clear that natural language processing makes up a big chunk of this. It would be interesting to know to what extend these models are already leveraged under the hood within chatbot development frameworks.
The Irony
The 2022 Gartner Magic Quadrant for Conversational AI Platforms (CAIP) does well to illustrate how crowded the CAIP landscape is.
This leads to the irony…
1️⃣ Each platform is trying to differentiate itself from all the others in a bid to win market share.
2️⃣ The feature arms-race lead to platforms becoming more alike than actually diverging (There are a few exceptions though). Examples of this is chatbot frameworks announcing voice enablement, agent-assist functionality, etc.
3️⃣ And here is the irony, chatbot development frameworks pride themselves on being self-contained. With their own NLU, dialog state development and management, plugins for different chat mediums, reporting and more.
But no one can compete with the might of LLMs, and all of a sudden virtually all chatbot development frameworks made LLM announcements within the last week or two.
➡️ And here is the kicker, their LLM implementations and functionality are extremely similar. 🙂
LLM Implementation Types
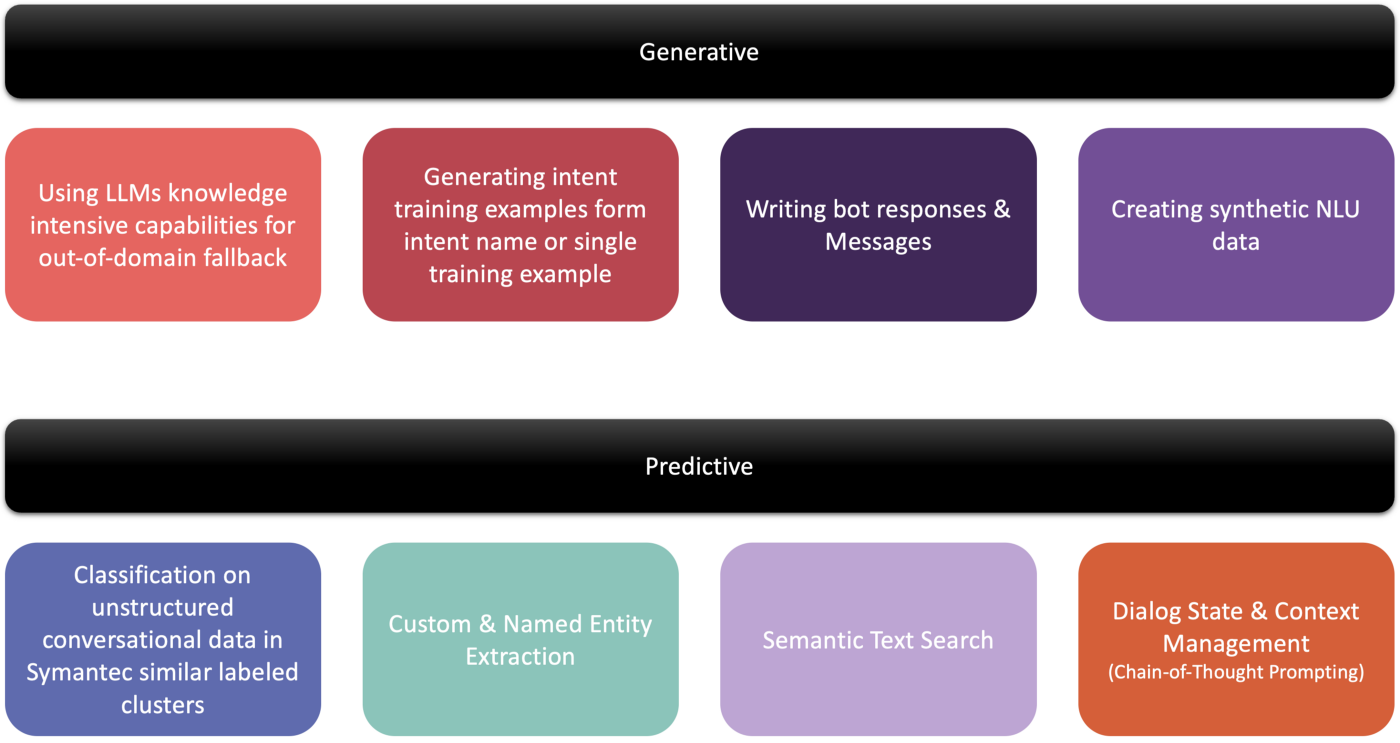
LLM implementations in CAIPs can be split into two areas:
⚙️ Generative & 🔮 Predictive
⚙️ Generative
Generative is usually where LLMs are implemented first as this is the easiest and fastest implementation.
The most common implementation is functionality to create intent training data. In some cases (Yellow AI and Kore AI) the intent name is used for creating training sentences or synonyms.
Both frameworks advise users to use augmented and descriptive intent names.
Little to no fine-tuning is required to make use of these basic generative capabilities.
The image below is from Kore AI’s presentation on their new Zero-shot ML Model. This approach demands from users to define descriptive and longer intent names. These intent names or rather intent sentences are used to generate synonyms in terms of training sentences.

This approach reminds much of Yellow AI’s approach with Dynamic NLP.
The problem I have here, is the missing link in knowing what the ambit of intents are, and how to solve for the long tail of intent distribution.
One of the popular implementations is to use the generative capabilities of LLMs with their knowledge intensive nature to respond to out-of-domain user questions. The challenge here is that of LLM hallucination, which was also cited by Meta as a challenge with Blender Bot 3.
🔮 Predictive
Predictive is the next and slightly more involved step. But a model like GPT-3can be trained in intent recognition for specific data. Semantic search forms part of this, together with entities, sentiment analysis and more.
SWOT Of Large Language Models
Considering the image below…what are the strengths, opportunities, weaknesses and threats of LLMs in general, and for CAIPs in specific?

Strengths
⏺ Existing default base knowledge. The best way to describe LLMs is knowledge intensive. The wide base of questions which can be answered is one of the reasons ChatGPT has gone mainstream. Another interesting aspect of the knowledge intensive nature of LLMs is blending.
By blending I refer to the unique capability of LLMs to blend knowledge, for instance the LLM can be instructed, “ (1)explain nuclear physics to a (2)toddler while sounding like (3)Donald Trump.“
Here three parameters or knowledge types need to be blended seamlessly.
⏺ Human language translation/ Multilingual. LLMs has the ability to be multilingual and translate between different languages. In the example below from OpenAI’s Language API referencing the text-davinci-003 model, perfect Afrikaans is understood and generated.

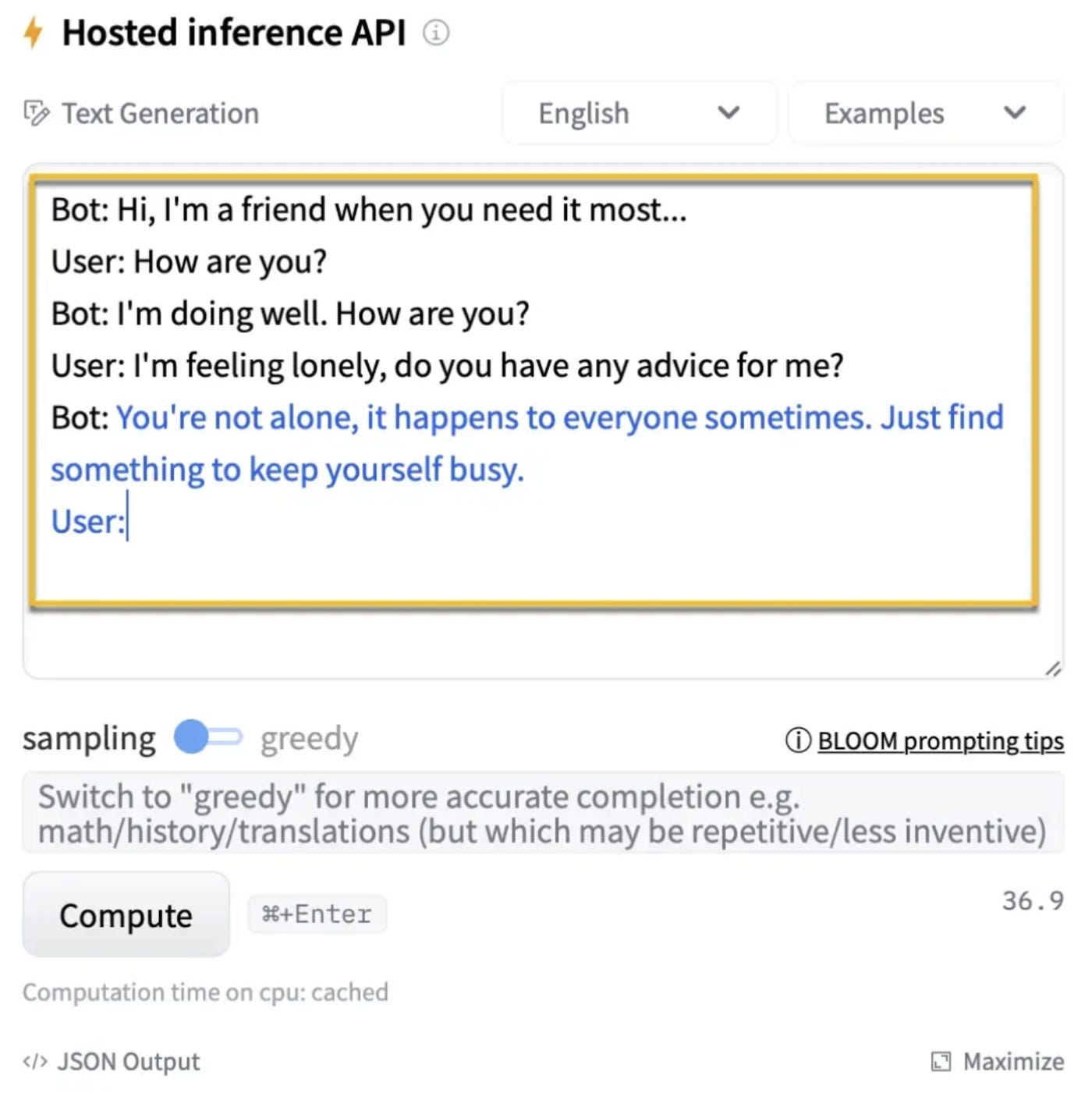
⏺ Generative power via prompt engineering. Generative functionality is the easiest way to leverage LLMs, even for novices. Dialog turns (Chain-of-Thought Prompting) can be created via prompt engineering in the example below from BLOOM via HuggingFace.
⏺ Zero/Few Shot Capabilities refer to LLM ability to yield results with no to very little training data. For instance, one sentence can be supplied to the LLM and the LLM can create any number of synonyms.
⏺ Multi-Disciplinary in terms of technology, coding etc. The versatility of LLMs is illustrated in their capability in human langauge and coding.
⏺ General search and dialog fall-back. LLMs can leverage their general knowledge to act as dialog fall-back for out-of-domain questions.
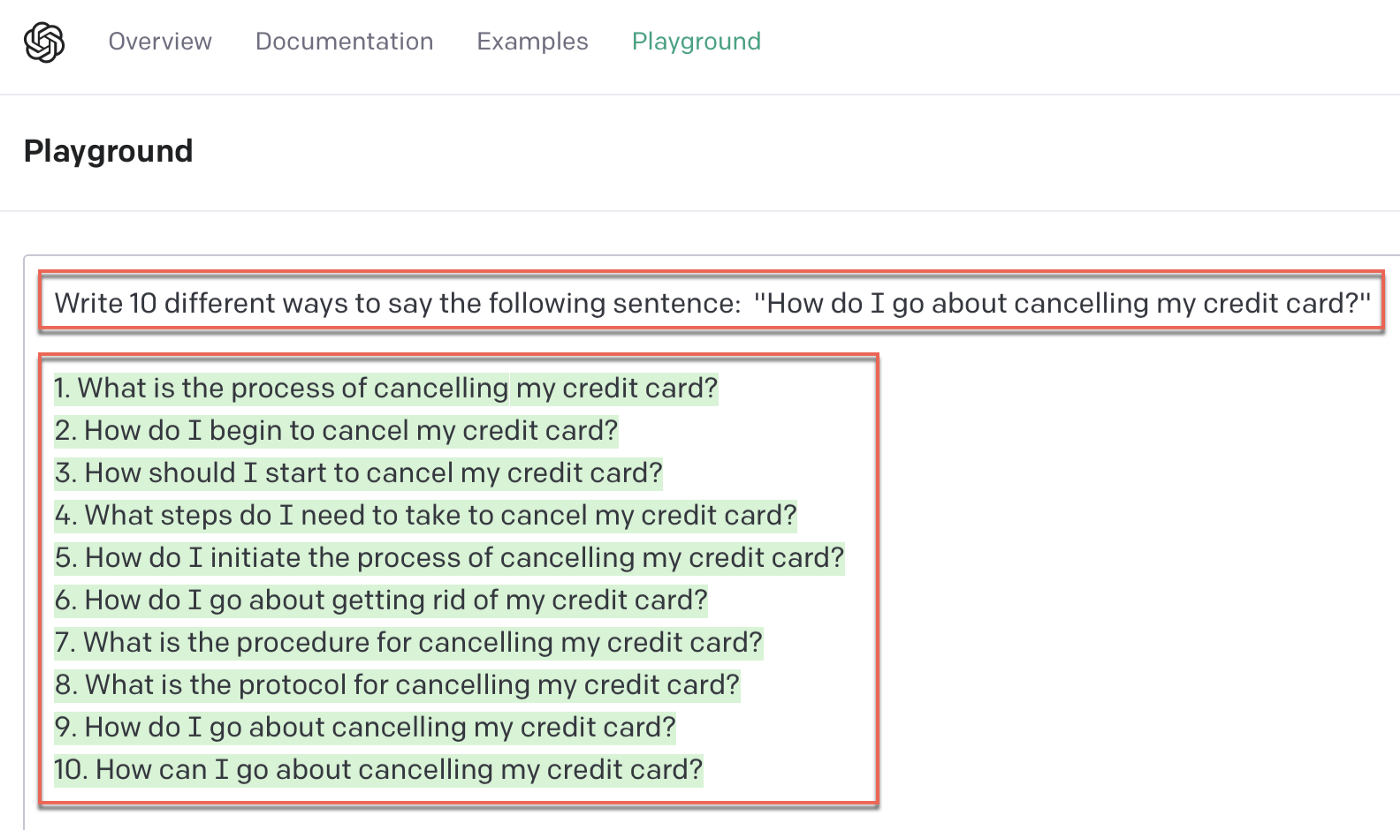
⏺ Synthetic training data for chatbots. This is currently the most common use of LLMs in chatbot development frameworks. A simple request can generate multiple training phrases for the same intent.
In the example below, a single line allows text-davinci-003 to generate wellformed and cohesive phrases.
Oppportunities
⏺ Continuous R&D of models. We will see immense advances in LLM capabilities, with merging of different mediums. Like voice, images, videos and text.
⏺ Bootstrapping complete chatbot solutions will become easier in future.
⏺ Foundation for innovating new products & services. LLMs will in increasing ways become the foundation of new products and services. Acting as an enabler.
⏺ Further automation of chatbot development. Currently LLM activity in chatbot development frameworks is limited to intent training data and general fallback. As LLMs develop, there should be other automation opportunities for chatbot development and management.
⏺ Autonomous dialog state management. Dialog state development and managing is the most intensive and labour intensive portion of chatbot development. It remains a hardcoded conditional navigation of a state machine. LLMs can start making inroads into this scenario.
⏺ Automation via Prompt Engineering. Prompt Engineering will most probably be leveraged in future by CAIPs. The premise is that prompt engineering is asking the LLM to perform a task, and customer conversations can be manipulated to act as engineered prompts.
Weakness
⏺ Lack of no-code & low-code custom fine-tuning. Fine-tuning needs are sure to arise as LLM use increases. And this is where the true power of LLMs resides, creating custom fine-tuned models which are use-case specific.
⏺ Lack of NLU & NLG Design tools for training data preparation. NLU (predictive )and NLG (generative) Design demands training data. Training data which is structured from unstructured (mostly conversational) data.
⏺ Sourcing and structuring training data for fine-tuning. Using LLM generated synthetic data to train the LLM with is not one of the best ideas. And hence sources must be found for good training data. Voice data is one source of data which is normally in abundance.
⏺ Default state of LLMs not Enterprise Ready. The aberrations in LLM responses in terms of hallucination and wrong answers makes it unfit for many enterprise implementations.
⏺ Ongoing management of custom fine-tuning. The complete lifecycle of a fine-tuned model should be managed, be replicatable, etc.
Threats
⏺ Data governance challenges. How are PII and protection of personal identifiable data managed in a LLM. Enterprises normally have strict data protection and governance in place.
⏺ Cost with rising usage. As usage rises, cost will rise with CAIP at the behest of LLM suppliers. This is an additional cost to digital assistant implementations and most probably will affect operational expenses the most.
⏺ Limited LLM Providers. There is only a number of LLM providers. Open-sourced initiatives like BLOOM, NLLB and others are aiming to negate this danger. Other low cost providers like Goose AI are sure to emerge.
⏺ Geographic/Regional Availability. This will surely be solved by big cloud providers, but there is surely a threat in terms of a model or functionality not being available in a given geographic region.
⏺ Unpredictable & Inconsistent Output. The hope is that this will improve over time in the long run, and fine-tuning in the shorter term. The introduction of the text-davinci-003 model has already seen huge improvements in terms of predictability and consistency.
⏺ Hallucination & inaccurate data being returned. LLMs make for great demos together with DALL-E. However, accurate data 100% of the time is a requirement for any production implementation.
⏺ Availability of minority Human Languages.
⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️

I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.

