Large Language Models Excel At In-Context Learning (ICL)
Recent studies have shown that, when supplied with a contextual reference at Inference, LLMs opt to make use of the contextual data as opposed to model training data.


Introduction
Retrieval-augmented generation (RAG) is widely adopted in Generative AI applications for several reasons.
Firstly, it capitalises on the power of In-Context Learning (ICL) within Large Language Models (LLMs), which enhances contextual understanding and helps mitigate errors like hallucinations.
Secondly, RAG offers a non-gradient approach, allowing customisation without the need for fine-tuning multiple LLMs, thus promoting LLM independence.
Thirdly, unlike opaque fine-tuning processes, RAG provides high observability and inspectability, enabling comparison between user input, retrieved context, and model-generated responses.
Fourthly, RAG facilitates easier continuous maintenance, suiting less technical and piece-meal approaches, thereby simplifying ongoing updates and improvements to the Generative AI solution.
In-Context Learning (ICL)
ICL leverages the LLM abilities of logic and common-sense reasoning, natural language generation, language understanding and contextual dialog management.
With the exception of not heavily relying on the knowledge intensive nature of LLMs.
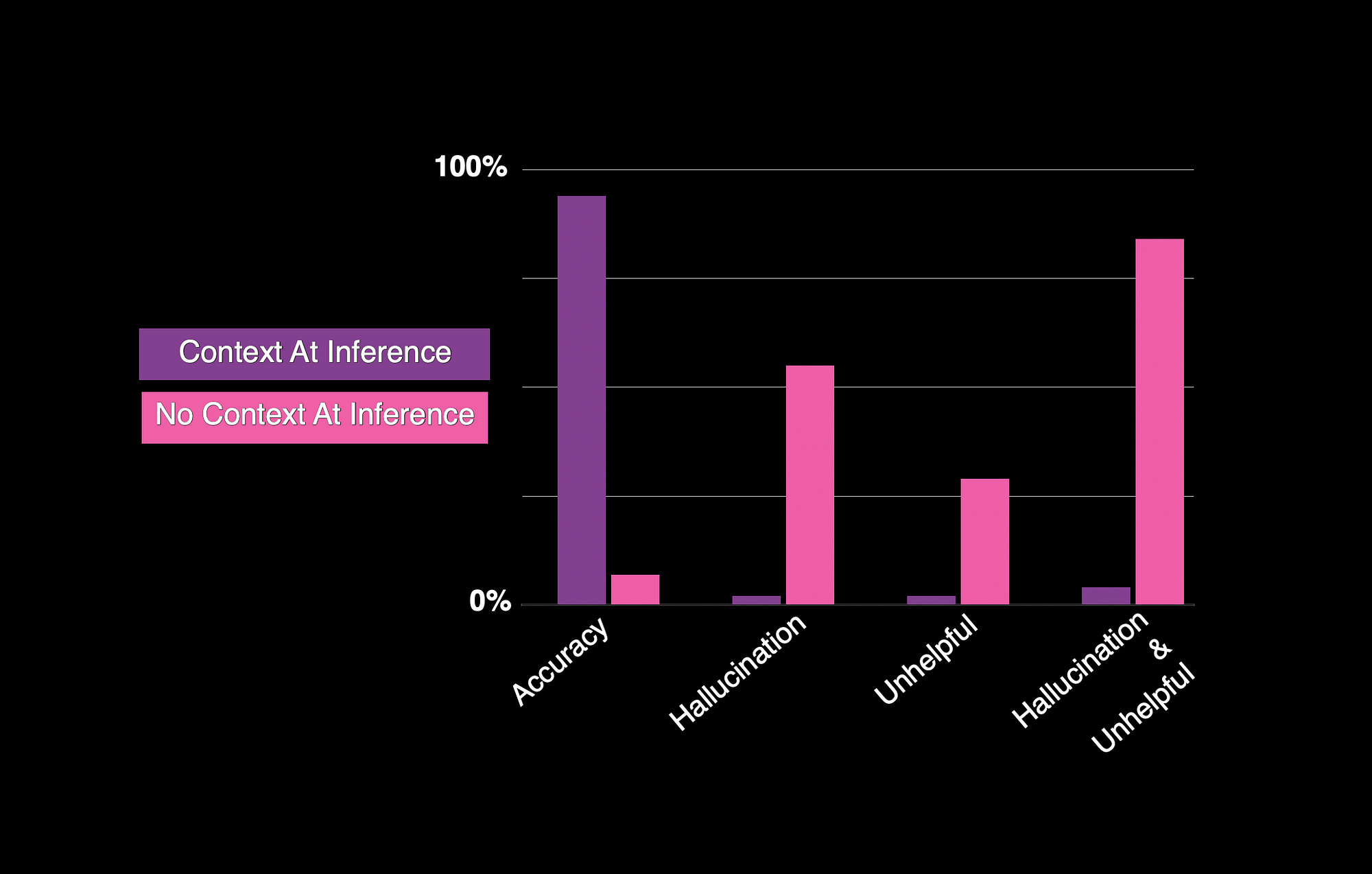
Considering the graph below, the stark contrast is illustrated when context is present and absent. The categories the study considered was accuracy, hallucination, helpfulness and helpfulness combined with hallucination.
Adjacent Hallucination
In context-based response augmentation, a common issue is how the model handles the prompt. In the study, each prompt includes education, work, and publication details from a CV.
Sometimes, the generated response continues into the next section instead of stopping after getting all relevant information. For instance, the text might include work details in the education section.
For example, when asked about subject’s education, the model listed degrees accurately but then added employment details.
Although the prompt limits responses to ten items, the model sometimes creates more items, appearing reasonable at first glance. This behaviour is akin to hallucination, as it presents inappropriate information in a believable manner.
In my opinion this is where accurate and astute chunking of information is important. The better input data is organised and segmented, the better the LLM response will be.
In Conclusion
This study highlights the crucial role of context in improving the accuracy of responses generated by language models using retrieval-augmented generation (RAG).
Incorporating context led to an impressive 18-fold increase in correctly navigating text, achieving a 94% accuracy rate. However, even with accurate context, a small percentage (6.04%) of responses were incorrect.
The study raises concerns about models’ ability to generate credible but false information, particularly when interpolating between factual content.
It also emphasises the impact of unusual formatting and incomplete context on response reliability. Additionally, it suggests that public expectations regarding language models may influence their usage.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.
