Leveraging LLM In-Context Learning Abilities
This study is one of the more complex and technical papers released of late…but there are valuable concepts to glean from it.

In Short
Large Language Models (LLMs) excel at in-context learning. Presented the correct context within a prompt at inference, and the LLM will leverage the contextual information to answer the question.
Hence not relying on existing knowledge the model is trained on, but using the external knowledge. There was a time when we expected LLMs to possess all knowledge; obviously this is not feasible for enterprise and organisational specific implementations.
There has been also a realisation that highly relevant data must be presented to the LLM at inference; accuracy in terms of relevance is paramount.
Overhead & Response Times
Considering LLM-based implementations are primarily conversational UIs, response times are of utmost importance.
One of the big challenges using commercial LLM APIs, is inference latency. And even-though structures like this adds to accuracy and reliability, overhead is added in terms of data processing and additional latency. Hence the easiest place to win time, so to speak, is at inference. This is possible with locally hosted open-source LLMs; which also solves for token usage cost.
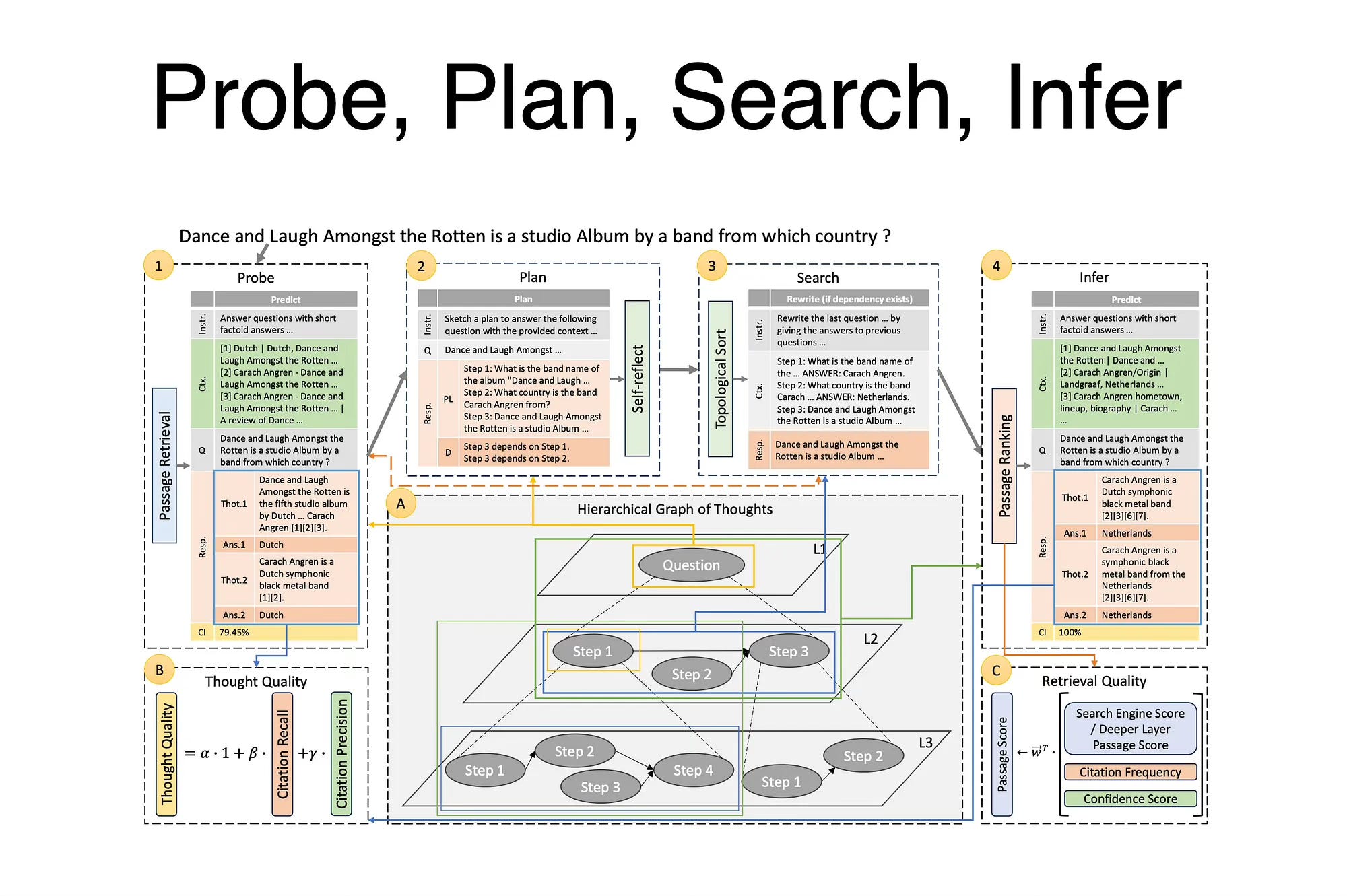
Probe, Plan, Search, Infer
LLMs have the ability to break complex queries into smaller, more manageable sub-queries, following a divide-and-conquer strategy.
This mechanism takes into account various factors such as the frequency of passage citation, the quality of citations in the thoughts, a self-consistency confidence score adjusted for citation quality, and the ranking provided by the retrieval module.
Furthermore, the HGOT framework proposes a scoring mechanism to evaluate the quality of retrieved passages. This mechanism takes into account various factors, including the frequency of passage citation and the citation quality.
Graph Structure
What I found interesting from the study is the sequence followed of Probe, Plan, Search & Infer which is followed.
However, the Hierarchical Graph Of Thought (HGOT) is the more opaque part of the structure.
The initial challenges that the study needed to overcome involved dynamically constructing hierarchical graphs, along with assessing and ranking the qualities of thoughts and retrieved passages within this complex structure.
The HGOT framework places a strong emphasis on the dynamic creation of a hierarchical graph structure by exploring the applicability of the emergent planning capabilities of LLMs.
Another key feature of the HGOT framework is the improvement of the self-consistency majority voting mechanism.
Furthermore, the HGOT framework proposes a scoring mechanism to evaluate the quality of retrieved passages. This mechanism takes into account various factors, including the frequency of passage citation, the citation quality.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.