

LLamaIndex Agentic RAG Demo
Agentic RAG is an agent based approach to perform question answering over multiple documents in an orchestrated fashion.


Compare different documents, summarise a specific document or compare various summaries. Agentic RAG is a flexible approach and framework to question answering.
Basic Architecture
The basic architecture is to setup a document agent of each of the documents, with each document agent being able to perform question answering and summarisation within its own document.
Then a top level agent (meta-agent) is setup managing all of the lower order document agents.

Data Source Used
Wikipedia articles about different cities are downloaded and each city document is stored separately.
In total 18 cities will be loaded. The number of 18 documents with each its own agent, does not necessitate a top level agent. But the application merely serves as a fully working demonstration which can be iterated on.
For production implementations, a much larger number of documents will be needed to justify this type of implementation.
Working Example
Here is a Github link to a working notebook example. The only change you need to make to the original LlamaIndex notebook, is add your OpenAI API key to the code, as I show here:
!pip install llama-index
### Start of section to add
import os
import openai
os.environ["OPENAI_API_KEY"] = "<Your API Key goes here>"
### End of section to add
from llama_index import (
VectorStoreIndex,
SummaryIndex,
SimpleKeywordTableIndex,
SimpleDirectoryReader,
ServiceContext,
)
from llama_index.schema import IndexNode
from llama_index.tools import QueryEngineTool, ToolMetadata
from llama_index.llms import OpenAIBelow the list of cities for which data is extracted from Wikipedia.
wiki_titles = [
"Toronto",
"Seattle",
"Chicago",
"Boston",
"Houston",
"Tokyo",
"Berlin",
"Lisbon",
"Paris",
"London",
"Atlanta",
"Munich",
"Shanghai",
"Beijing",
"Copenhagen",
"Moscow",
"Cairo",
"Karachi",
]This code defined the vector query tool:
query_engine_tools = [
QueryEngineTool(
query_engine=vector_query_engine,
metadata=ToolMetadata(
name="vector_tool",
description=(
"Useful for questions related to specific aspects of"
f" {wiki_title} (e.g. the history, arts and culture,"
" sports, demographics, or more)."
),
),
),And here the summary tool is defined:
QueryEngineTool(
query_engine=summary_query_engine,
metadata=ToolMetadata(
name="summary_tool",
description=(
"Useful for any requests that require a holistic summary"
f" of EVERYTHING about {wiki_title}. For questions about"
" more specific sections, please use the vector_tool."
),
),
),And here the agent is defined:
function_llm = OpenAI(model="gpt-4")
agent = OpenAIAgent.from_tools(
query_engine_tools,
llm=function_llm,
verbose=True,
system_prompt=f"""\
You are a specialized agent designed to answer queries about {wiki_title}.
You must ALWAYS use at least one of the tools provided when answering a question; do NOT rely on prior knowledge.\
""",
)The top agent is being defined:
from llama_index.agent import FnRetrieverOpenAIAgent
top_agent = FnRetrieverOpenAIAgent.from_retriever(
obj_index.as_retriever(similarity_top_k=3),
system_prompt=""" \
You are an agent designed to answer queries about a set of given cities.
Please always use the tools provided to answer a question. Do not rely on prior knowledge.\
""",
verbose=True,
)Practical Examples of Question Answering
Considering the image below, the question Tell me about the arts and culture in Boston is posed to the Top Level Agent.
From the output one can see that the tool/function called tool_Boston is called. Notice in the input field, the entities of art and culture are retrieved.

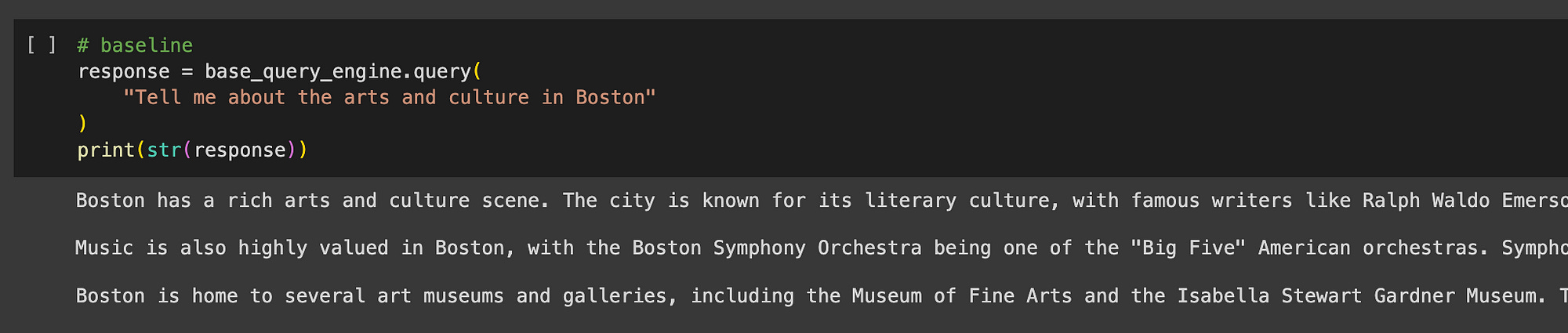
Below, a question is asked on the base level, and the tool /function answers the question.
Considering the image below, a question is asked which requires two tools / functions to be leveraged. In TURN 1 use is made of tool_Houston and then the vector_tool is called with demographics. Hence population data is returned on the city of Houston.
In TURN 2, tool_Chicago is called, and also the vector_tool with the term demographics.
The two responses from the base agents, are then synthesised for the final answer:
Houston has a population of 2,304,580, while Chicago has a population of under 2.7 million. Houston is known for its diverse demographic makeup, with a significant number of undocumented immigrants. In terms of age distribution, Houston has a large number of residents under 15 and between the ages of 20 to 34, with a median age of 33.4.
In Chicago, the largest racial or ethnic groups are non-Hispanic White, Blacks, and Hispanics. Additionally, Chicago has a significant LGBTQ population, with an estimated 7.5% of the adult population identifying as LGBTQ.

Lastly, looking at the image below…
What happens if a question is asked regarding a city which is not part of the uploaded RAG corpus?
Below a question is pose to the Agentic RAG implementation regarding Cape Town and Perth. On a base level, the query is answered by leveraging the LLM.
On a top agent level, there is an error, as the tool for Cape Town and Perth are not found. Obviously resilience will be added in terms of a production environment. And a decision will have to be made if a LLM is leveraged to answer the question. Or to what extent the user will be informed that the question falls outside of the implementation domain….

Considerations
This implementation by LlamaIndex illustrates a few key principles…
Agentic RAG, where an agent approach is followed for a RAG implementation adds resilience and intelligence to the RAG implementation.
It is a good illustration of multi-agent orchestration.
This architecture serves as a good reference framework of how scaling an agent can be optimised with a second tier of smaller worker-agents.
Agentic RAG is an example of a controlled and well defined autonomousagent implementation.
One of the most popular enterprise LLM implementation types are RAG, Agentic RAG is a natural progression of this.
It is easy to envisage how this architecture can grow and expand over an organisation with more sub bots being added.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.