LLaVA-o1
A Vision Language Models Which Can Reason Step-by-Step au- tonomous multistage reasoning.

Current reasoning models, such as OpenAI o1, operate as black boxes, with their internal processes largely hidden.
In contrast, LLaVA-o1 introduces a transparent, multi-stage reasoning approach that integrates visual and textual information to provide greater insight into its decision-making process.
What is LLaVA-01?
LLaVA-o1 is an open-source visual language model designed to outperform counterparts like GPT-4o-mini in reasoning tasks.
It achieves this by leveraging both vision and language to enable autonomous, structured, multi-stage reasoning during inference.
By incorporating visual inputs, the model establishes a contextually rich reference, enhancing its ability to interpret and reason about the world effectively.
Why Vision Integration Matters
Integrating vision into language models is essential for developing a more comprehensive understanding of the world.
Vision provides context, allowing models to make connections that extend their cognitive capabilities.
LLaVA-o1 emphasises this integration to build a multimodal framework that supports systematic, deep reasoning.
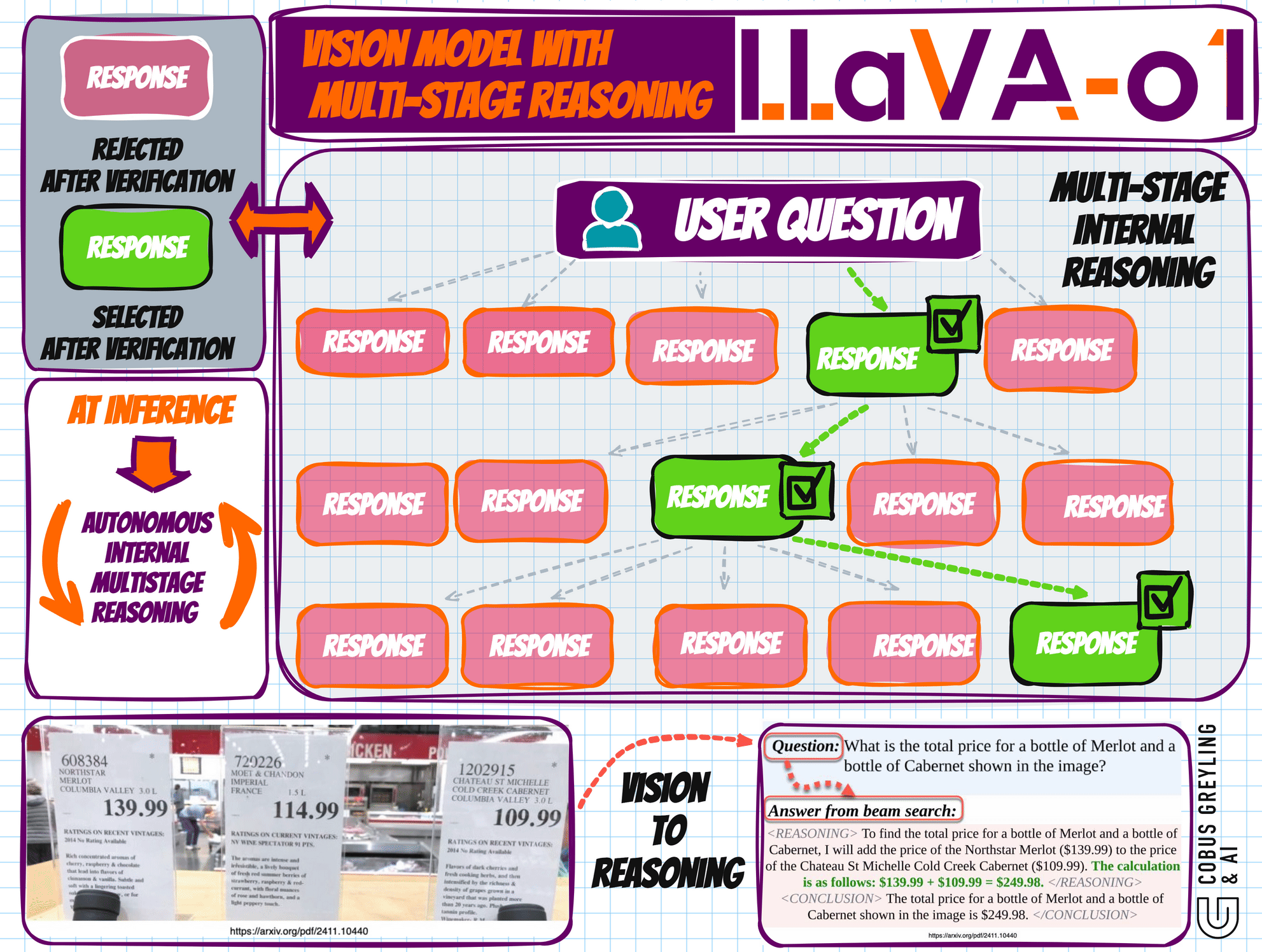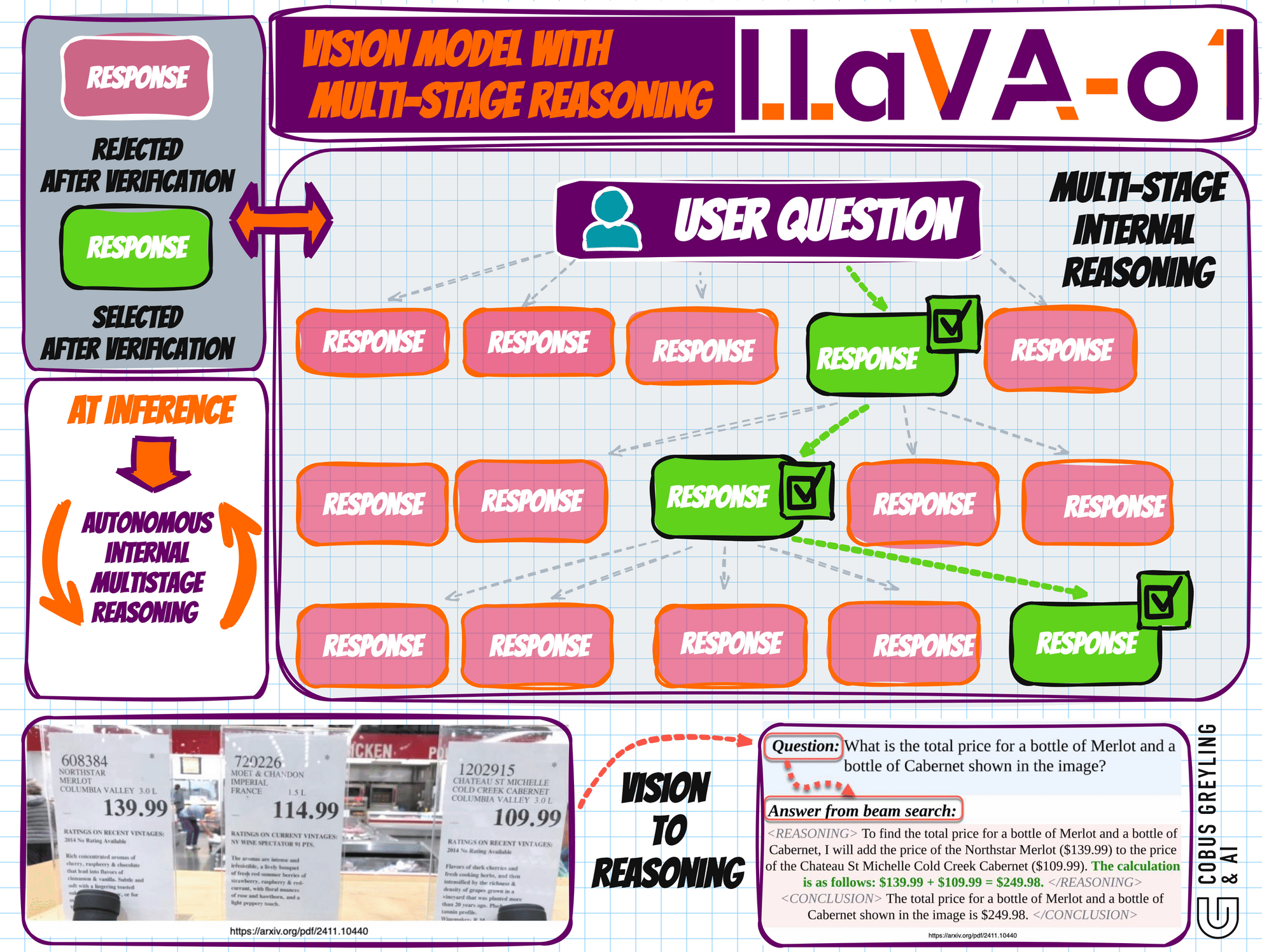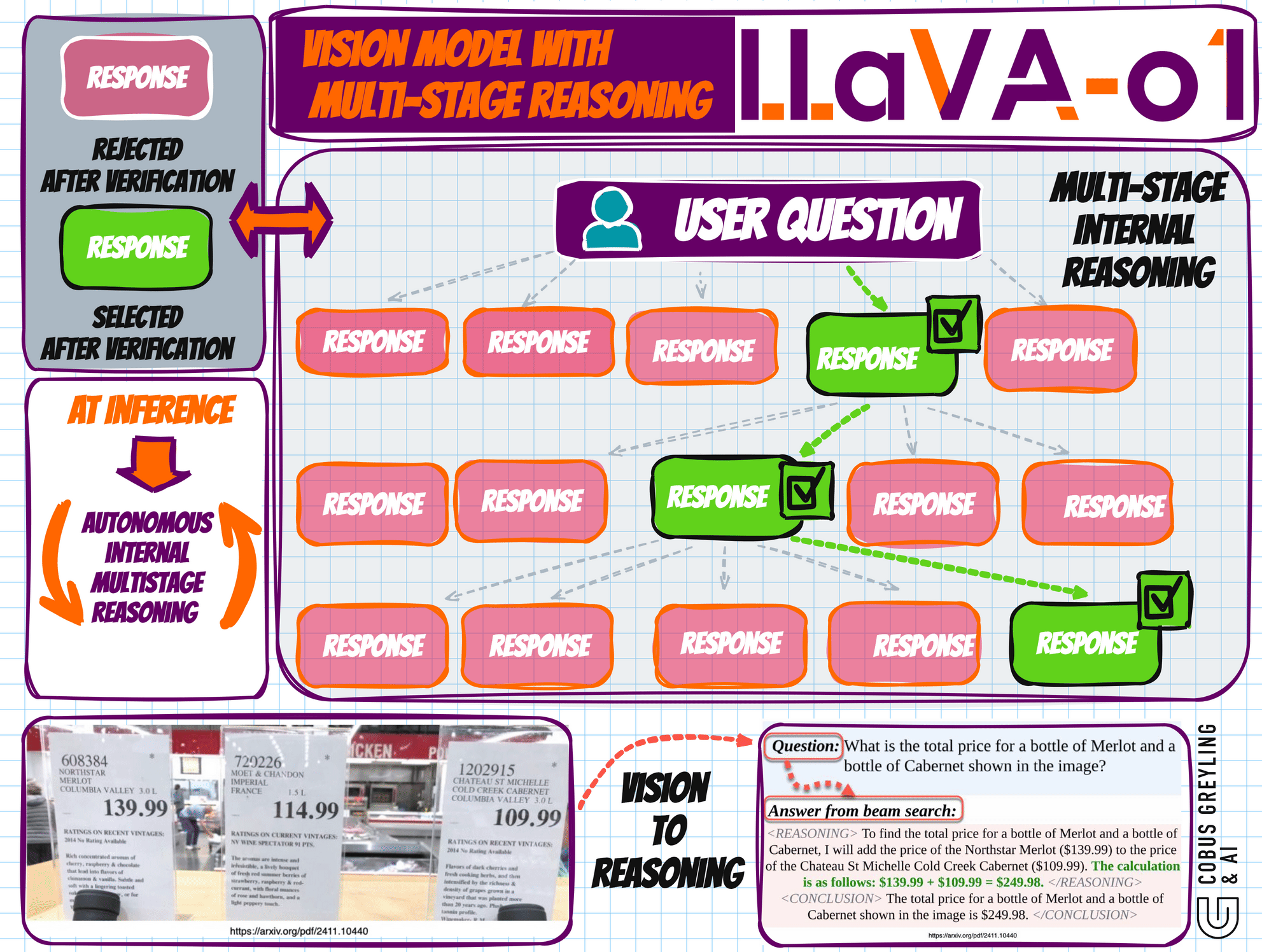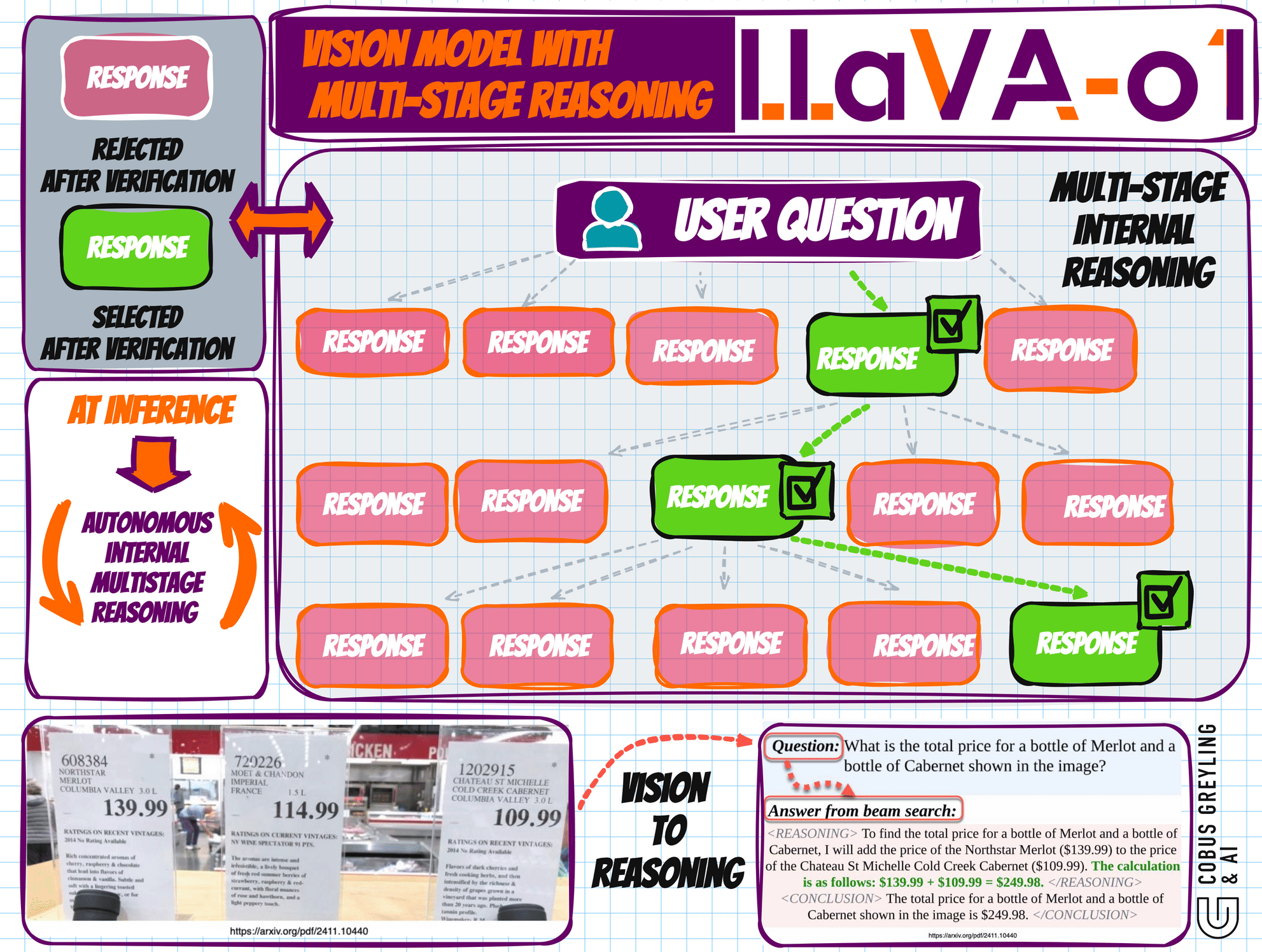
The Multi-Stage Reasoning Process
LLaVA-o1 decomposes tasks into four distinct stages, each serving a specific role in the reasoning pipeline:
Summary: A brief outline in which the model summa- rizes the forthcoming task.
Caption: A description of the relevant parts of an image, focusing on elements related to the question.
Reasoning: A detailed analysis in which the model systematically considers the question.
Conclusion: A concise summary of the answer, providing a final response based on the preceding reasoning.
This structured approach ensures that each stage is transparent, systematic, and clearly defined, enabling users to understand the progression of the model’s reasoning.
Advancing Systematic Reasoning
Existing Visual Language Models (VLMs) often lack a sufficiently systematic and structured reasoning process.
LLaVA-o1 addresses this gap by following a well-organised reasoning chain, identifying the task at hand, and focusing on it at each stage.
This not only enhances interpretability but also improves the model’s overall performance and reliability.
The Key Differentiator
Unlike GPT-4o-mini, which provides no visibility into its internal reasoning structure, LLaVA-o1 offers a transparent decomposition of tasks.
This insight into the model’s multi-stage reasoning process represents a significant leap forward in the field of multimodal AI, paving the way for more advanced and trustworthy systems.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.