LLM Context Rot
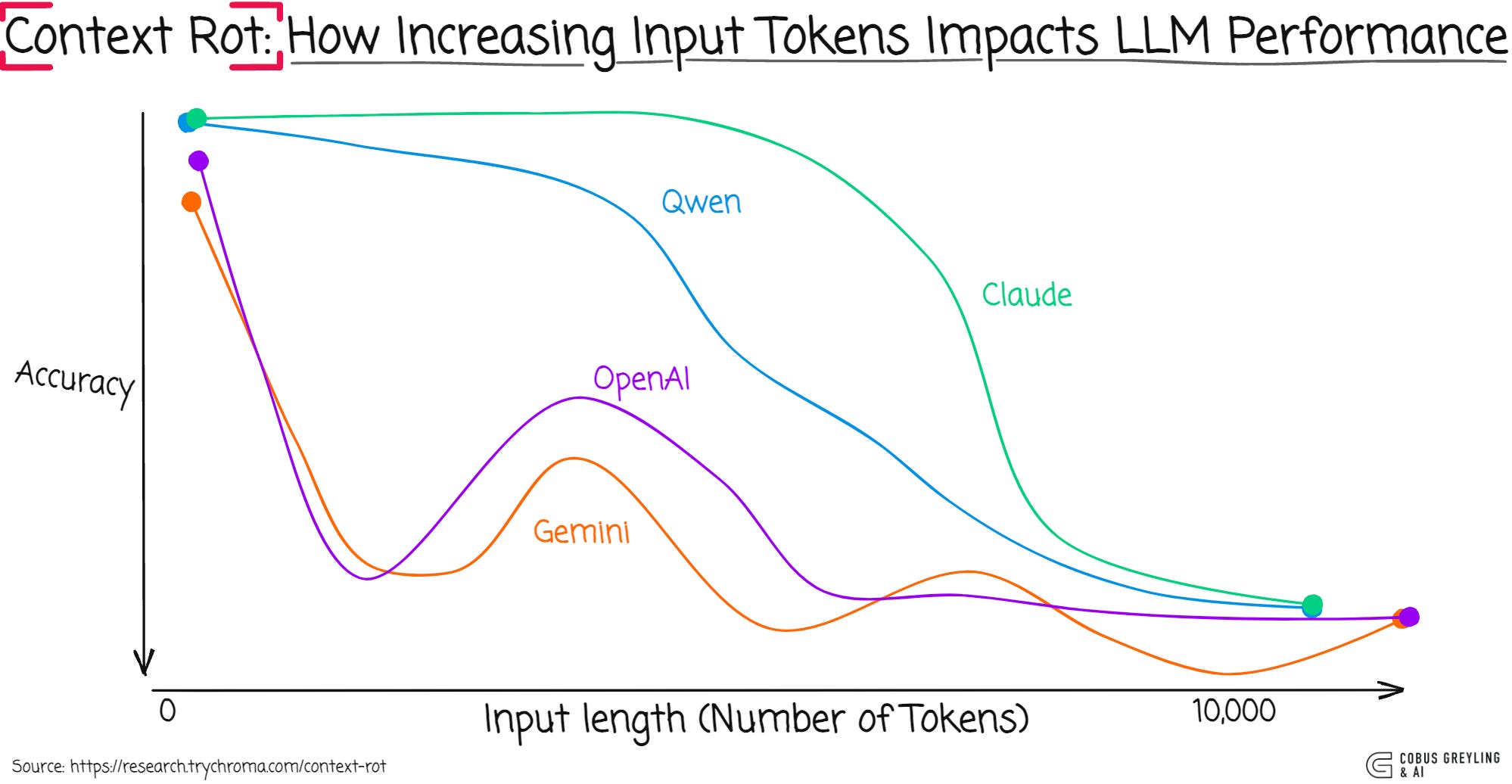
The Chroma “Context Rot” study reveals that simply increasing input length & maximising token windows doesn’t deliver linearly improving accuracy.

Instead, LLM performance degrades unevenly & often unpredictably as contexts grow, underscoring the limitations of relying on sheer scale over thoughtful context engineering.
In Short
Chroma’s recent study evaluated 18 leading large language models (LLMs), including cutting-edge ones like GPT-4.1, Claude 4, Gemini 2.5 & Qwen3.
The research highlights that models don’t process context uniformly, leading to increasingly unreliable performance as input lengths expand — a phenomenon dubbed context rot.
Different model families exhibit unique behaviours; for instance, OpenAI’s GPT series often shows erratic and inconsistent outputs, while others degrade more predictably.
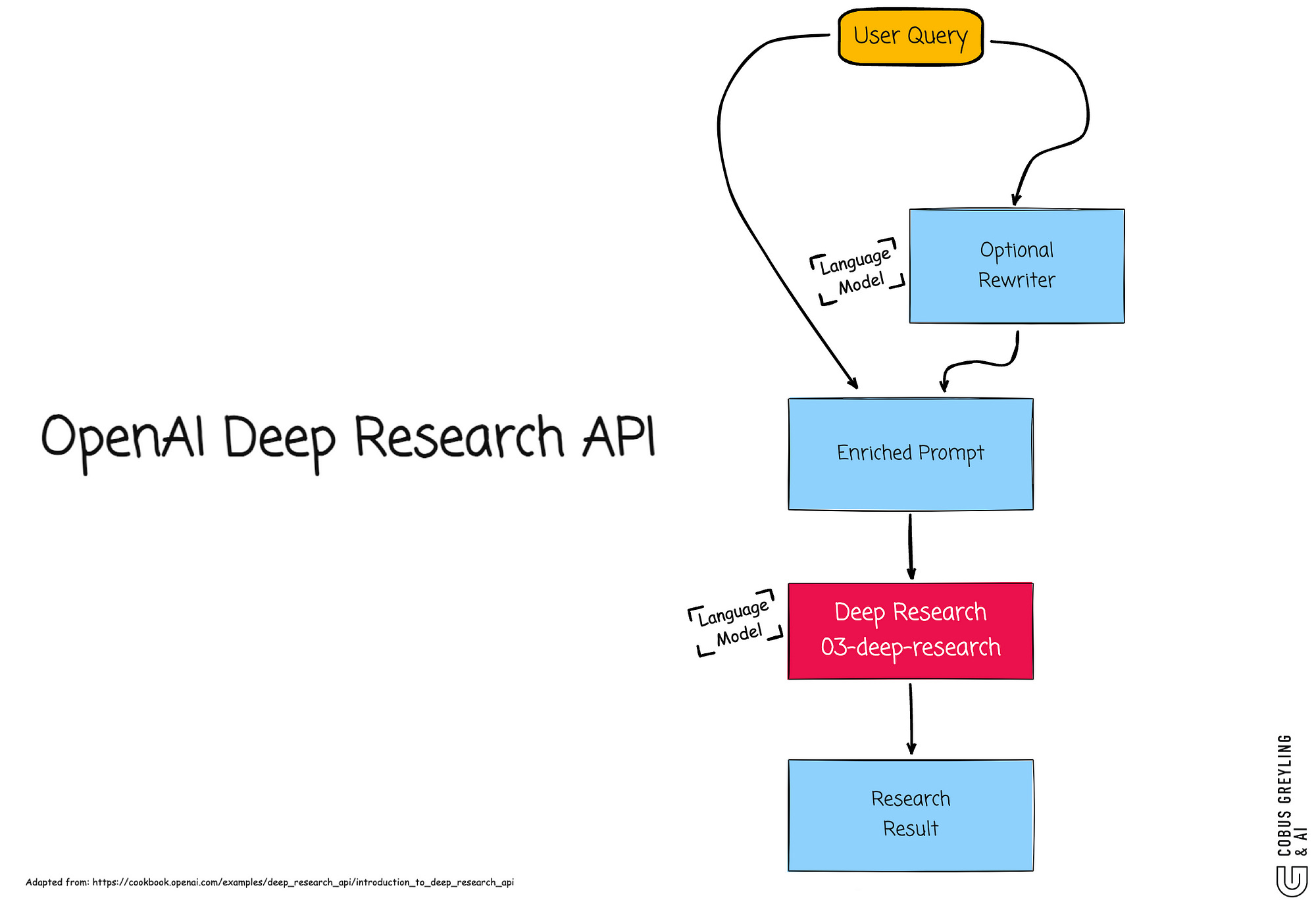
This create concerns around model drift, where underlying behaviors shift unexpectedly, amplified by recent OpenAI disclosures about their Deep Research API, which relies on model orchestration to handle intricate workflows.
For enterprises, it underscores the risks of investing heavily in AI Agents or generative AI apps, as unpredictable elements in commercial models can undermine efforts to manage and optimise application performance.
Key Considerations
In AI Agent implementations, prioritising model independence — or at least some degree of model agnosticism — is crucial to avoid getting locked into a single provider’s ecosystem.
Context management, a key element, can either be built directly into your framework for fine-grained control.
Or context management can be offloaded to the language model itself, but the latter approach introduces dependencies on the model’s unpredictable behaviour.
Model performance degrades unevenly with longer inputs.
This reliance also leaves you vulnerable to fluctuating token costs, pricing changes & model deprecations, which can disrupt your application’s reliability without warning.
Instead, handle context management at the framework level with granular techniques like chunking or retrieval-augmented generation (RAG), reducing exposure to these risks and ensuring more consistent results.
This strategy aligns with NVIDIA’s push for open-source, fine-tuned small language models (SLMs), which deliver strong performance for specific tasks without the overhead of massive, proprietary LLMs — enabling cost-effective, customizable AI that scales efficiently for enterprises.
Caveat
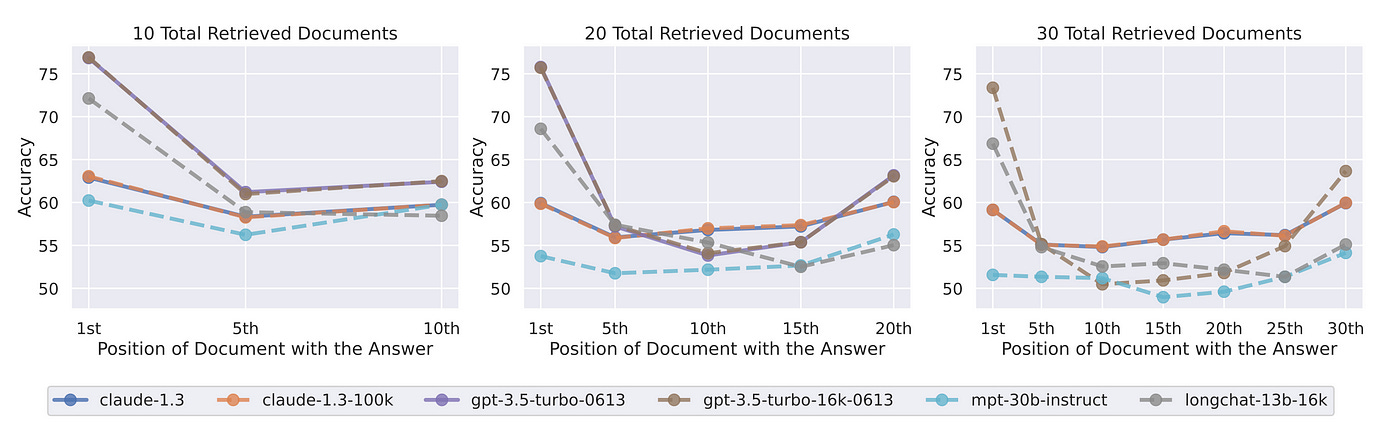
In 2023 there was a study that coined the term “Lost in the Middle”…the study examined the performance of LLMs on two types of tasks:
One involving the identification of relevant information within input contexts.
A second involving multi-document question answering and key-value retrieval.
The study found that LLMs perform better when the relevant information is located at the beginning or end of the input context.
However, when relevant context is in the middle of longer contexts, the retrieval performance is degraded considerably. This is also the case for models specifically designed for long contexts.
Fast forward to 2025, and a study from Chroma coins the term “Context Rot”…
Before we get into Context Rot…overall, the study provides useful insights into LLM limitations, its origins warrant scrutiny.
If long contexts prove detrimental as claimed, it bolsters Chroma’s RAG ecosystem; if not, it could be seen as marketing spin.
For a balanced view, some cross-referencing might be prudent…
Overall, it’s a wake-up call that bigger context windows aren’t a magic fix — smart design beats brute force for getting accurate results.
Repeated Word Test
This test and the subsequent degradation of performance proves that throwing more data at model doesn’t always help.
On the contrary, it can lead to random errors, refusals or hallucinations, wasting time and trust.
Practically, it pushes developers to break down big inputs into smaller chunks or use tools like search databases to feed only the relevant bits, making AI more reliable and efficient for stuff like legal reviews or customer support.
Overall, it’s a wake-up call that bigger context windows aren’t a magic fix — smart design beats brute force for getting accurate results.
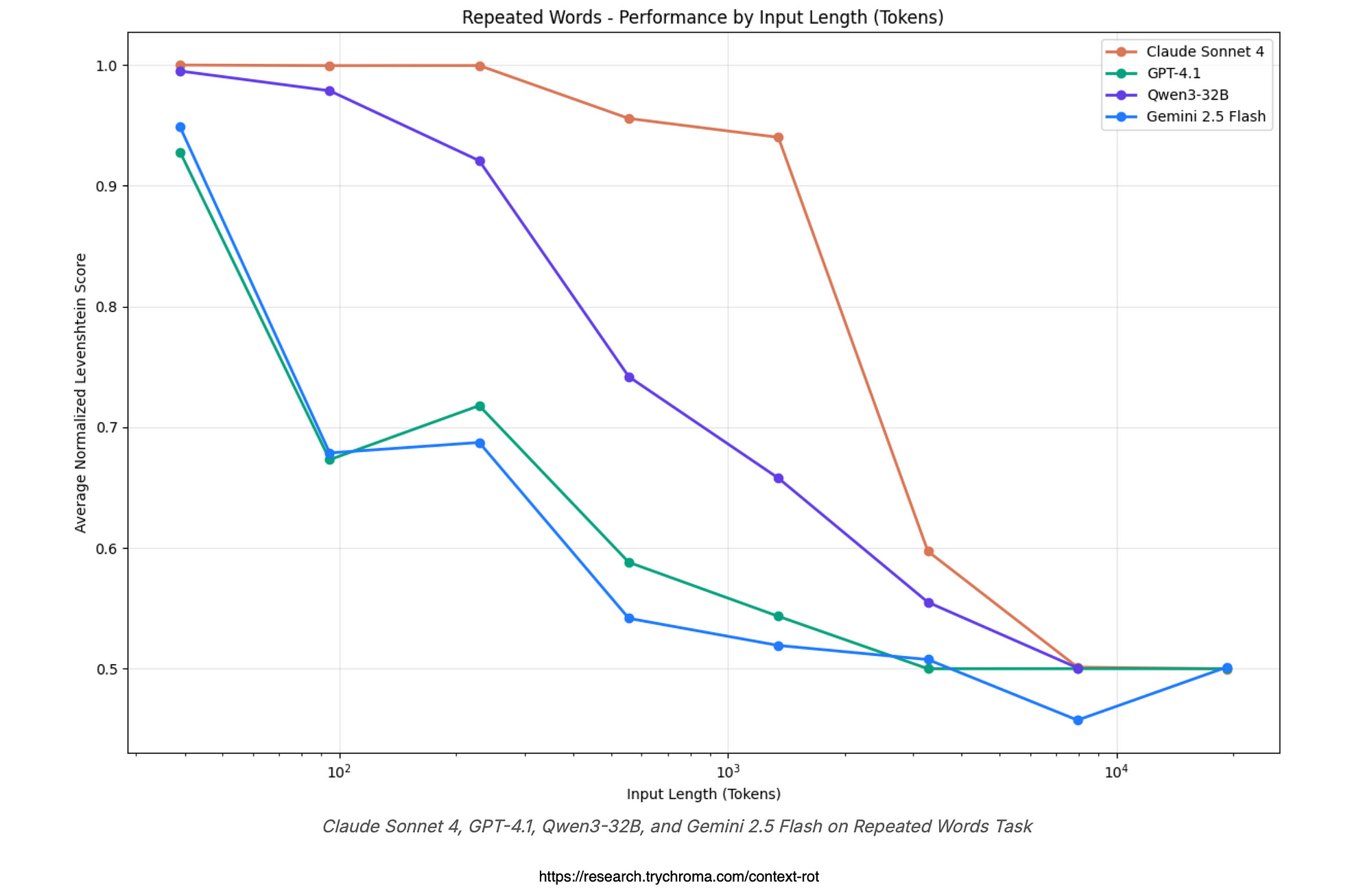
In the repeated word test, all four model families —
Qwen,
OpenAI’s GPT,
Google’s Gemini &
Anthropic’s Claude
— show a clear drop in performance as the input gets longer, meaning they struggle more to copy a bunch of repeated words with one oddball word thrown in somewhere.
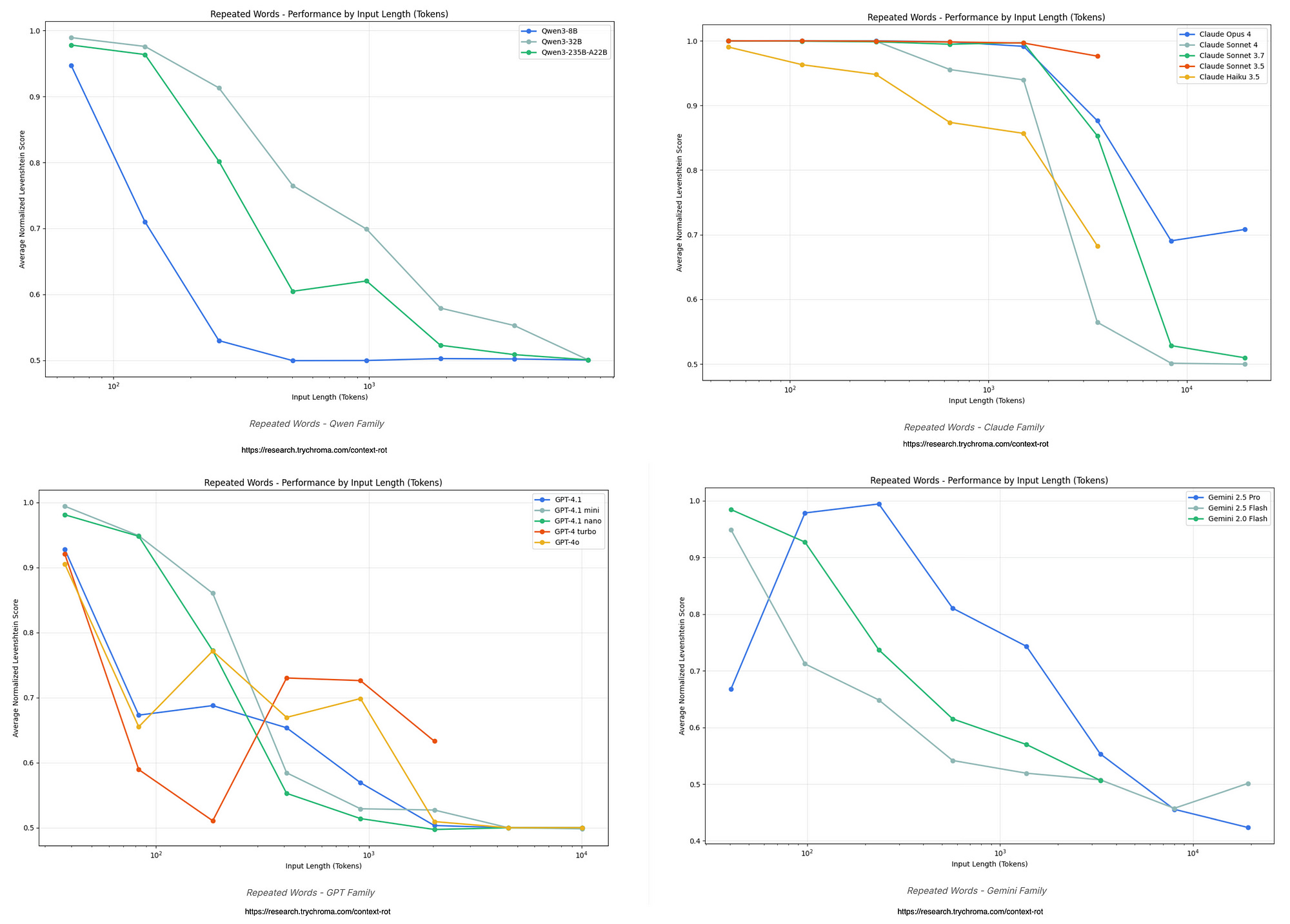
Qwen models degrade steadily but hold up better with bigger versions, while GPT models are more erratic with random mistakes and outright refusals to try.
Gemini stands out for starting to mess up earlier with wild variations, but Claude models decay the slowest overall, though they often quit on long tasks for safety reasons, making them reliable for shorter stuff but picky on longer ones.
In the end, no model is immune to this “rot,” but Claude edges out as the toughest, Gemini the flakiest, proving that throwing more words at these AI brains doesn’t always make them smarter — it can make them dumber.
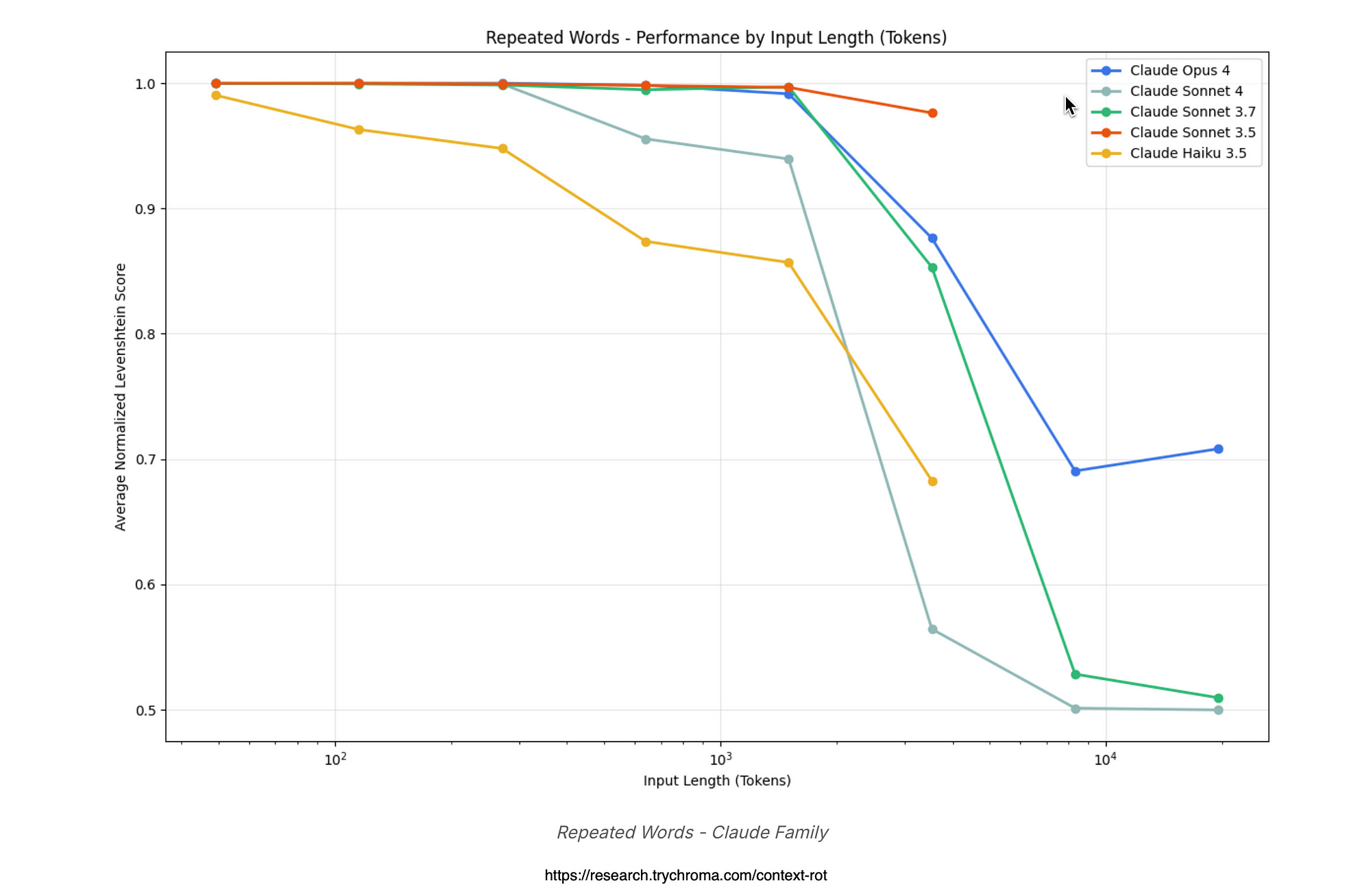
For the Claude graph below, it shows slower-rising error lines across models like Claude 3.5 Sonnet, with strong starts but fading beyond 8,000 words, often from under-generating to hit token limits.
Position matters big here — unique words up front get nailed better than those buried deep, boosting accuracy short-term.
Claude Opus refuses tasks around 2,500 words citing risks, like fearing copyright issues, which keeps it safer but limits its stamina compared to greedier models.
A higher Levenshtein score means more mistakes, like adding extra words, skipping some, or generating random gibberish, showing how “context rot” makes models mess up as input length grows.
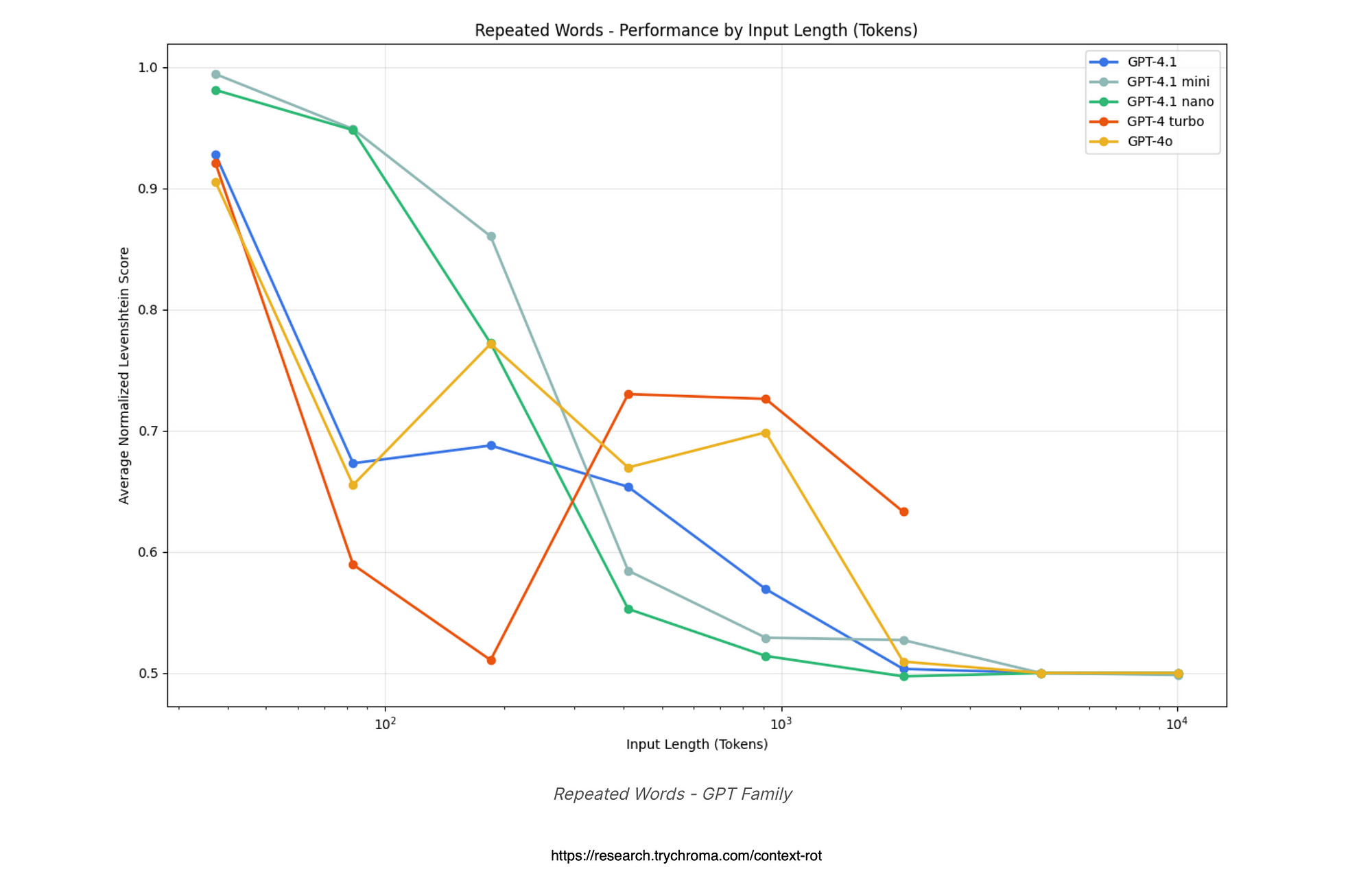
For the OpenAI GPT, it charts normalised edit distances rising with input length, meaning more errors creep in, and lines for models like GPT-4o show bumpy rides with peaks around 500 words from over- or under-copying.
GPT-3.5 often just refuses to play, hitting a 60% no-go rate, while even top ones like GPT-4 Turbo throw in extra words or cut short.
This highlights how GPTs get unpredictable fast, with random duplicates popping up tied to where the unique word sits.
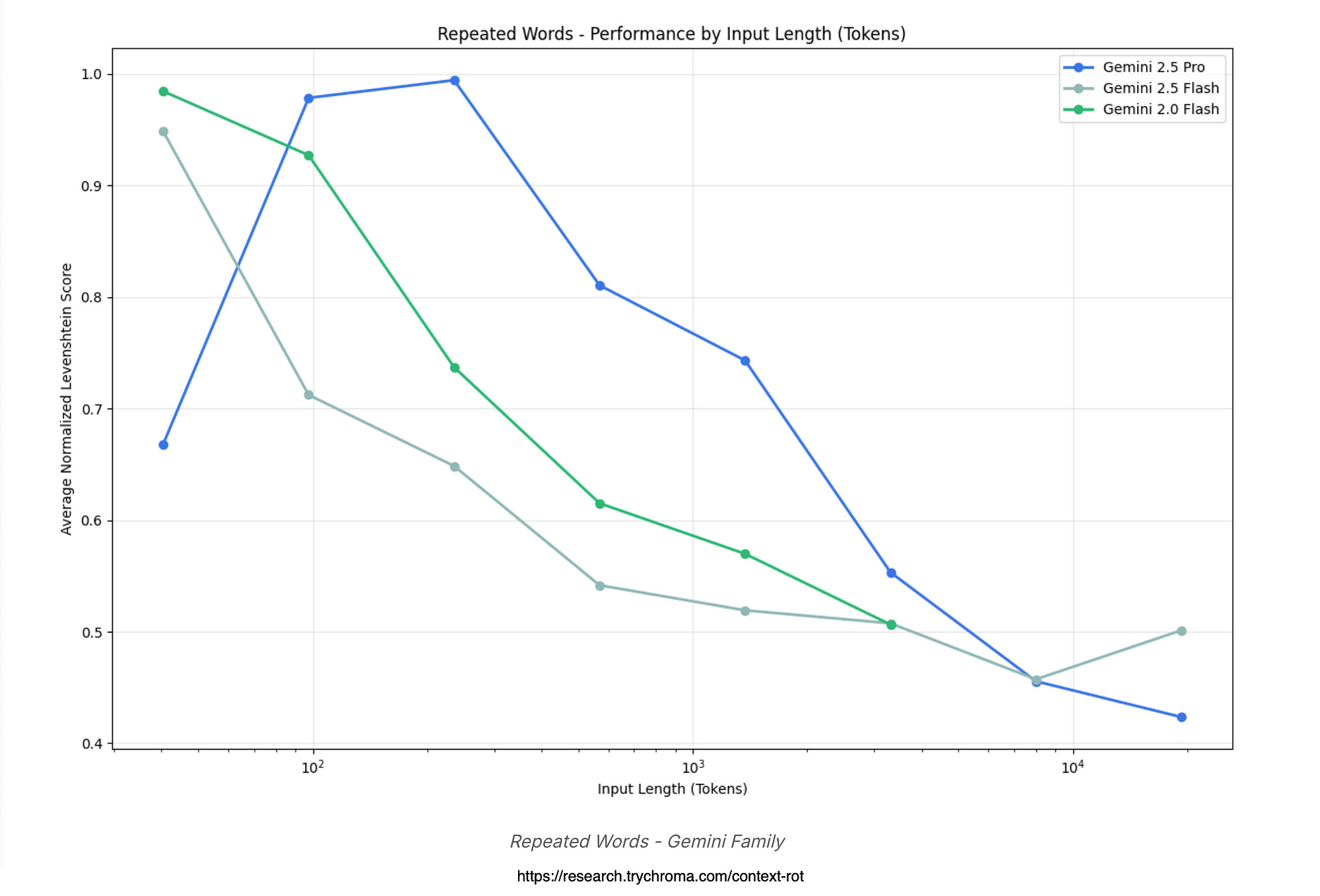
For the Gemini graph, performance lines for models like Gemini 1.5 Pro nosedive quicker than others, with errors measured by edit distance spiking from just 500–750 words due to random word swaps.
The Pro version shows the wildest swings, under-generating early and then going haywire with unrelated outputs. Overall, it reveals Gemini as the quickest to lose its grip, making it less trusty for any task needing long, precise recall.
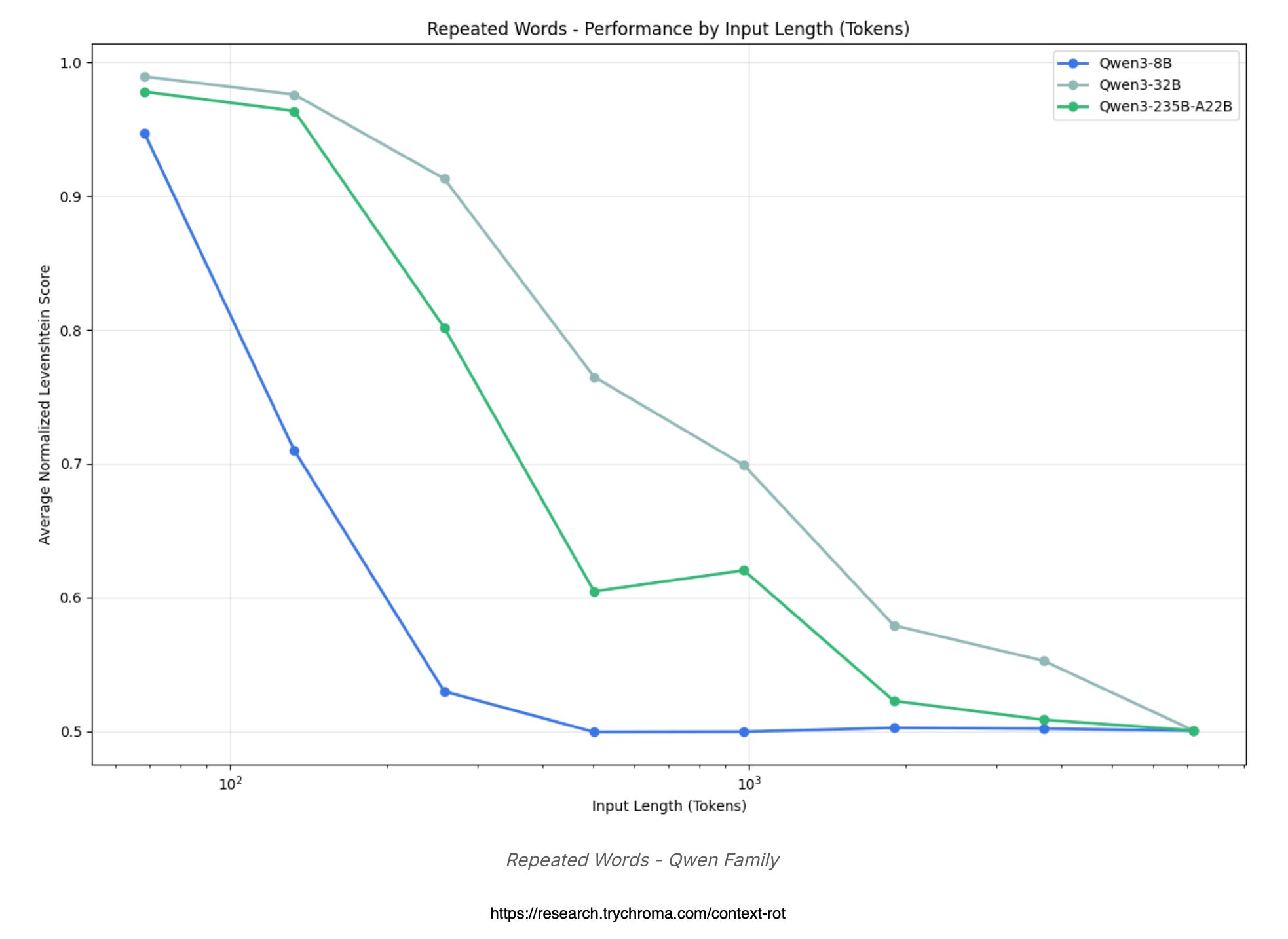
For Qwen, lines for each model size dipping down as things get longer.
Smaller Qwen versions start spitting out random junk around 5,000 words.
Bigger models like Qwen3–235B hang in there longer, showing that size helps fight the rot but doesn’t stop it cold.
Conclusion
Model-families behave differently compared to each-other, with some like ChatGPT showing erratic behaviour with disparate behaviour.
The study also brings to mind the concept of model drift where model behaviour changes under the hood. Recently OpenAI revealed the complexity behind their research API, with model orchestration.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.
Coming to this a bit late but the Chroma study findings still hold up. The "lost in the middle" problem from 2023 hasn't gone away with bigger windows; it's just been pushed further out.
Your point about handling context management at the framework level rather than offloading it to the model is the right call. I've been running into this practically with coding agents and one approach that's clicked is multi-agent isolation. Instead of one long conversation accumulating noise, you spin up sub-agents that each work in a clean context and send back summaries. Wrote up how Codex handles this natively here https://reading.sh/codex-has-a-multi-agent-mode-and-almost-nobody-is-using-it-088e44f774ef if you're interested. The gist is that context hygiene matters more than context size, which aligns with what you're saying about smart design beating brute force.