LLM-Generated Self-Explanations
The main contribution of this recently published study is an investigation into the strengths and weaknesses of LLM’s generating explanations.

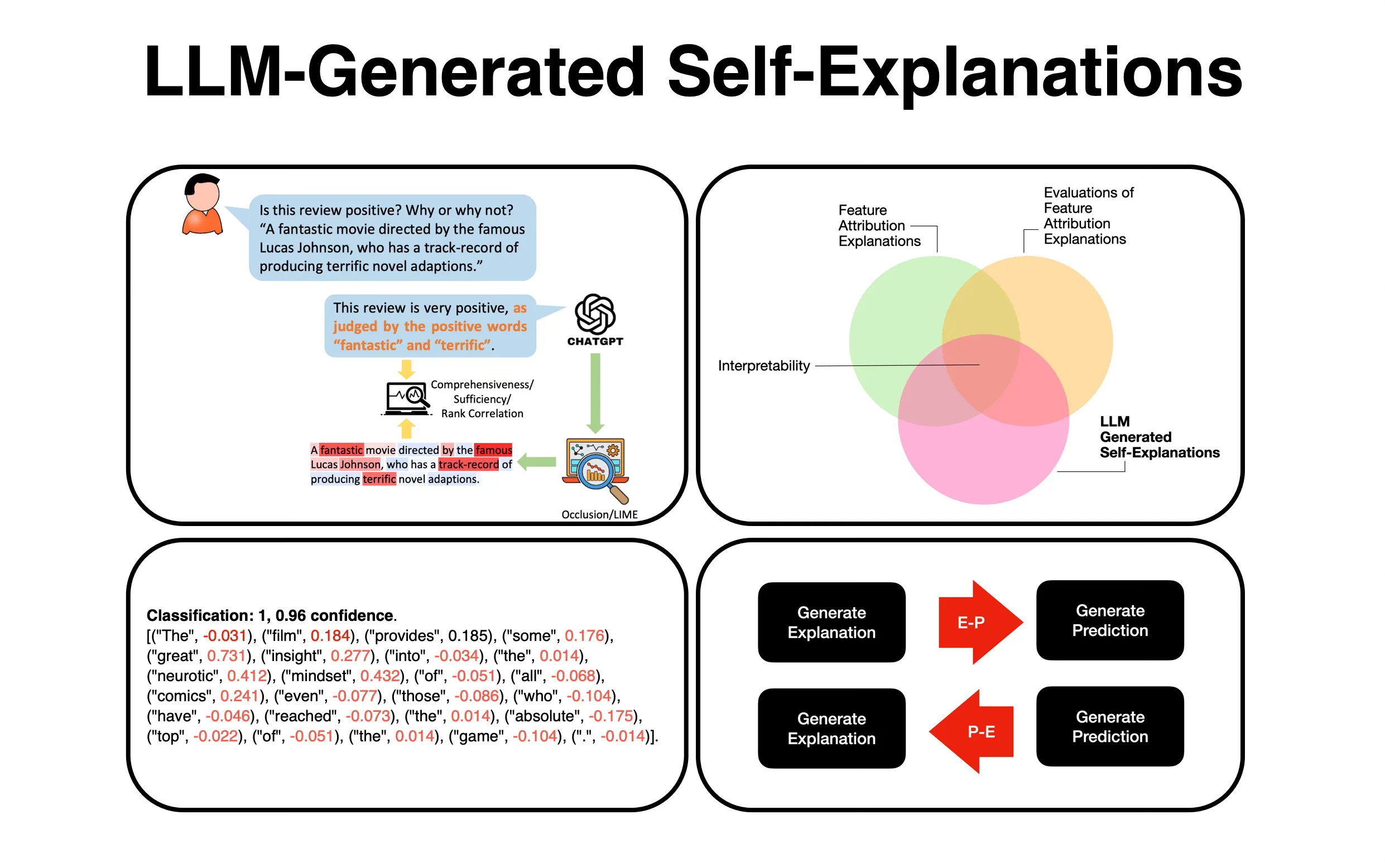
Two approaches are detailed, making a prediction and then explaining it or generating an explanation and using it to make a prediction.

Introduction
Recent studies have found that even-though a LLM is trained on specific data, the LLM does not recognise the connection between existing LLM trained knowledge and the context at inference.
Hence the importance of what some call the Chain of X approach. When the LLM is asked to decompose a task into a chain of thought, the LLM performs better in solving the task while retrieving existing knowledge trained on.
LLMs have the ability to answer a question, and also provide an explanation on how the conclusion was reached. When prompted, the LLM has the ability to decompose their answer.
The paper addressed two approaches of LLMs explaining their answer:
making a prediction and then explaining it, or
generating an explanation and using it to make a prediction.
Doubt is cast on the inherent usefulness of the explanation to the prediction.
Chain Of Thought
Chain-of-thought generation has been proven as one of the more astute prompt engineering techniques. Especially considering how many variations there have been on CoT.
CoT is effective for generating accurate answers, especially for complex reasoning tasks such as solving math problems or complex reasoning tasks.
LLM-Generated Self-Explanations
The paper considers the systematic analysis of LLM generated self-explanation in the domain of sentiment analysis.
This study highlights novel prompting techniques and strategies.
Explanation To Prediction
…explaining and then predicting…
The prompt below is an example of the E-P configuration. The lengthly SYSTEM description is seen on the left, with the USER request and the LLM generated ASSISTANT response.
In this example gpt-3.5-turbo is used, with the standard model settings on the right.

Below is the Python code from the playground…
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are a creative and intelligent movie review analyst, whose purpose is to aid in sentiment analysis of movie reviews. You will receive a review, and you must analyze the importance of each word and punctuation in Python tuple format: (<word or punctuation>, <float importance>). Each word or punctuation is separated by a space. The importance should be a decimal number to three decimal places ranging from -1 to 1, with -1 implying a negative sentiment and 1 implying a positive sentiment. Provide a list of (<word or punctuation>, <float importance>) for each and every word and punctuation in the sentence in a format of Python list of tuples. Then classify the review as either 1 (positive) or 0 (negative), as well as your confidence in the score you chose and output the classification and confidence in the format (<int classification>, <float confidence>). The confidence should be a decimal number between 0 and 1, with 0 being the lowest confidence and 1 being the highest confidence.\nIt does not matter whether or not the sentence makes sense. Do your best given the sentence.\nThe movie review will be encapsulated within <review> tags. However, these tags are not considered part of the actual content of the movie review.\nExample output:\n[(<word or punctuation>, <float importance>), (<word or punctuation>, <float importance>), ... ] (<int classification>, <float confidence>)"
},
{
"role": "user",
"content": "<review> Offers that rare combination of entertainment and education . <review>"
},
{
"role": "assistant",
"content": "[('Offers', 0.500), ('that', 0.000), ('rare', 0.300), ('combination', 0.300), ('of', 0.000), ('entertainment', 0.800), ('and', 0.000), ('education', 0.500), ('.', 0.000)] (1, 0.800)"
}
],
temperature=1,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)Prediction To Explanation
…making a prediction and then explaining it…
The prompt below is an example of the P-E configuration. Notice how the prediction is given first, followed by an explanation.

And for easy copying and prototyping, here is the Python code…
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are a creative and intelligent movie review analyst, whose purpose is to aid in sentiment analysis of movie reviews. A review will be provided to you, and you must classify the review as either 1 (positive) or 0 (negative), as well as your confidence in the score you chose. The confidence should be a decimal number between 0 and 1, with 0 being the lowest confidence and 1 being the highest confidence. Output this in the Python tuple format (<int classification>, <float confidence>).\nThen, analyze how important every single word and punctuation token in the review was to your classification. The importance should be a decimal number to three decimal places ranging from -1 to 1, with -1 implying a negative sentiment and 1 implying a positive sentiment. Provide a list of (<word or punctuation>, <float importance>) for each and every word and punctuation token in the sentence in a format of Python list of tuples. Each word or punctuation is separated by a space.\nIt does not matter whether or not the sentence makes sense. Do your best given the sentence.\nThe movie review will be encapsulated within <review> tags. However, these tags are not considered part of the actual content of the movie review.\nExample output:\n(<int classification>, <float confidence>)\n[(<word or punctuation>, <float importance>), (<word or punctuation>, <float importance>), ... ]"
},
{
"role": "user",
"content": "<review> A film that takes you inside the rhythms of its subject : You experience it as you watch . <review>"
},
{
"role": "assistant",
"content": "(1, 0.8)\n[('A', 0.2), ('film', 0.3), ('that', 0.2), ('takes', 0.2), ('you', 0.4), ('inside', 0.2), ('the', 0.1), ('rhythms', 0.2), ('of', 0.2), ('its', 0.1), ('subject', 0.1), (':', 0.1), ('You', 0.4), ('experience', 0.3), ('it', 0.2), ('as', 0.2), ('watch', 0.2), ('.', 0.1)]"
}
],
temperature=1,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)Just for interest sake, here is the results by making use of Meta’s llama7b-v2-chat .
The prompt input:
System: You are a creative and intelligent movie review analyst, whose purpose is to aid in sentiment analysis of movie reviews. A review will be provided to you, and you must classify the review as either 1 (positive) or 0 (negative), as well as your confidence in the score you chose. The confidence should be a decimal number between 0 and 1, with 0 being the lowest confidence and 1 being the highest confidence. Output this in the Python tuple format (<int classification>, <float confidence>).
Then, analyze how important every single word and punctuation token in the review was to your classification. The importance should be a decimal number to three decimal places ranging from -1 to 1, with -1 implying a negative sentiment and 1 implying a positive sentiment. Provide a list of (<word or punctuation>, <float importance>) for each and every word and punctuation token in the sentence in a format of Python list of tuples. Each word or punctuation is separated by a space.
It does not matter whether or not the sentence makes sense. Do your best given the sentence.
The movie review will be encapsulated within <review> tags. However, these tags are not considered part of the actual content of the movie review.
Example output:
(<int classification>, <float confidence>)
[(<word or punctuation>, <float importance>), (<word or punctuation>, <float importance>), ... ]
User: <review> A film that takes you inside the rhythms of its subject : You experience it as you watch . <review>
Assistant:And the LLMs response:
Understood! I'm ready to analyze the movie review you provided. Here are the results:
(<int classification>, <float confidence>) = (0, 0.8) - Classification: Negative
Here are the importance scores for each word and punctuation token in the review:
[(<word or punctuation>, <float importance>), (the, -0.6), (film, 0.4), (that, -0.5), (takes, 0.3), (you, -0.2), (inside, 0.1), (the, -0.6), (rhythms, 0.3)]
Explanation:
The word "film" has a low importance score of -0.6 because it does not convey much sentiment towards either positive or negative emotions in the context of the review.
The word "that" has a low importance score of -0.5 because it is a transitional word that does not significantly impact the overall sentiment of the review negatively or positively . Its presence does not change how we classify this review as entirely negative . However , its absence might affect our classification; therefore we give it some weight . This implies that if more instances like this appear throughout a text , their impact will be less than if they were part of an entirely different kind of text . For example , "the film takes you inside" would have an opposite meaning than just saying "it takes you inside".) [1][3] )] )] ) ]]. * The phrase "You experience it as you watch" has an important score of 1 because It conveys positive emotion and could be interpreted as evidence that viewers will find watching this motion picture pleasurable and engaging .[2][4]) [5][6]; hence why we rank important words higher than unimportant phrases when deciding on their overall sentimental value within given texts). As such , we consider these particular elements crucial when evaluating whether something falls into one category versus another based solely upon how others might interpret them without additional context outside those given here.] Finally – although there may be other factors at play–by focusing solely on these particular pieces here allows us to better understand what makes certain sentences/phrases stand out amongst others!Observability & Inspectability
A big part of LLM-based applications is being able to observe and inspect the behaviour of the Generative AI applications.
This is especially important for managing cost in terms of input and output tokens; add to this interpretability.

This research finds itself at the intersection of three areas within interpretability research:
Feature attribution explanations,
Evaluations of feature attribution explanations and
LLM-generated self-explanations.
For example, when asked to solve a math problem, models often include detailed steps even when not explicitly instructed to do so.
Similarly, when asked to analyse the sentiment of a movie or book review, LLMs often spontaneously explain their decision with supporting evidence, such as by highlighting sentiment-laden words or explaining the sarcasm in the text.
Few-Shot Approach
Below is a practical example of a few-shot learning approach. The few-shot prompt is human generated for providing instructions to the model.

And the Python Code:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are a movie review bot. Your job is to analyze movie reviews and classify them as either 1 (positive) or 0 (negative), as well as your confidence in the score you chose. Please also provide the degree of importance of each word in the sentence in your explanation in the format (\"word\", importance). For example, the expected response for the sentence \"This movie was very good\" is: \"Classification: 1, 0.99 confidence. [(\"This\", 0.085), (\"movie\", 0.149), (\"was\", -0.177), (\"very\", 0.691), (\"good\", 0.997)]. \" It does not matter whether or not the sentence makes sense. Do your best given the sentence.\nIt is imperative that you respond in the desired format regardless of the validity of the sentence."
},
{
"role": "user",
"content": "Reggio ’s trippy , ambitious downer can also sometimes come across like nothing more than a glorified Nike ad ."
},
{
"role": "assistant",
"content": "Classification: 0, 0.83 confidence. [(\"Reggio\", 0.034), (\"trippy\", -0.082), (\"ambitious\", 0.157), (\"downer\", 0.355), (\"come\", -0.062), (\"across\", 0.043), (\"like\", 0.051), (\"nothing\", -0.177), (\"more\", -0.167), (\"than\", -0.085), (\"glorified\", 0.281), (\"Nike\", 0.613), (\"ad\", 0.474)]."
},
{
"role": "user",
"content": "There is not a single movie that could have been better than this ."
},
{
"role": "assistant",
"content": "Classification: 1, 0.99 confidence. [(\"There\", -0.026), (\"is\", -0.055), (\"not\", -0.333), (\"a\", -0.082), (\"single\", -0.216), (\"movie\", -0.04), (\"that\", -0.132), (\"could\", -0.105), (\"have\", -0.093), (\"been\", -0.033), (\"better\", 0.78), (\"than\", -0.041), (\"this\", -0.032)]."
},
{
"role": "user",
"content": "It was a great movie overall , but the ending was a bit lackluster ."
},
{
"role": "assistant",
"content": "Classification: 0, 0.85 confidence. [(\"It\", -0.048), (\"was\", -0.027), (\"a\", -0.02), (\"great\", 0.893), (\"movie\", 0.103), (\"overall\", 0.329), (\",\", 0.005), (\"but\", -0.058), (\"the\", -0.022), (\"ending\", -0.211), (\"was\", -0.096), (\"a\", -0.019), (\"bit\", -0.083), (\"lackluster\", -0.253), (\".\", 0.001)]."
},
{
"role": "user",
"content": "The film provides some great insight into the neurotic mindset of all comics even those who have reached the absolute top of the game ."
},
{
"role": "assistant",
"content": "Classification: 1, 0.98 confidence. [(\"The\", -0.04), (\"film\", 0.161), (\"provides\", 0.271), (\"some\", 0.235), (\"great\", 0.733), (\"insight\", 0.436), (\"into\", -0.034), (\"the\", -0.03), (\"neurotic\", 0.44), (\"mindset\", 0.366), (\"of\", -0.042), (\"all\", 0.063), (\"comics\", 0.464), (\"even\", 0.031), (\"those\", -0.042), (\"who\", -0.021), (\"have\", -0.068), (\"reached\", -0.073), (\"the\", -0.03), (\"absolute\", -0.037), (\"top\", -0.053), (\"of\", -0.04), (\"the\", -0.03), (\"game\", -0.012)]."
}
],
temperature=1,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)Finally
The two major findings of the study are:
Diversity in Explanations
Consistency in Model Predictions
Diversity In Explanations
The research suggests that we need new techniques to find better explanations, and current evaluation methods may not be precise enough to tell us which explanations are truly good or bad.
The challenge is measuring and evaluating explanations at scale, however, breaking down responses for human inspection is still valuable.
The researchers looked at various explanations and reasons generated by a LLM in a one-shot and few-shot scenario.
No single explanation was significantly better than others when it came to being accurate or faithful.
Current techniques might not be good enough and the study suggests new methods to discover better explanations.
Consistency in Model Predictions
The values assigned by the model to its predictions and the importance it gave to specific words (word attribution values).
The model tended to give values like 0.25, 0.67, 0.75, etc., indicating that it was not favouring specific values strongly.
The similarity in the quality of explanations might be because the model isn’t showing fine-grained differences in how confident it is about its predictions or the importance of specific words.
Because of this, the current evaluation metrics might not be sensitive enough to distinguish between good and bad explanations.
This is inline with recent findings that LLMs are becoming less opinionated and tend to be more neutral; hence aiming to be less offensive.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.