LLM Performance Over Time & Task Contamination
The study reveals that LLMs perform significantly better on datasets released before their training data creation date compared to datasets released after...

Introduction
Data contamination in LLMs occurs when the training data contains test data used for downstream tasks. Hence having an impact on testing and general use.
Taking A Step Back
A study released on 31 Oct 2023 evaluated the most widely used Large Language Models (LLMs), including GPT-3.5 and GPT-4, in their March 2023 and June 2023 versions over a period of time.
The study covered diverse tasks such as math problems, sensitive questions, opinion surveys, multi-hop knowledge-intensive questions, code generation, visual reasoning and more. The analysis revealed significant variations in the performance and behaviour of both GPT-3.5 and GPT-4 over time.
GPT-4 accuracy in identifying prime vs. composite numbers dropped from 84% in March 2023 to 51% in June 2023.
GPT-4’s reduced ability to follow Chain-Of-Thought (CoT) prompting and a decline in answering sensitive questions contribute to these changes.
The study emphasises again the importance of continuous monitoring of LLMs due to the observed substantial changes in behaviour over a relatively short period.
A New Study…
…dated 26 Dec 2023 investigated how zero-shot and few-shot performance of LLMs have changed over a period of time.
We find evidence that some LLMs have seen task examples during pre-training for a range of tasks, and are therefore no longer zero or few-shot for these tasks. — Source
The study considered 12 models shown below…
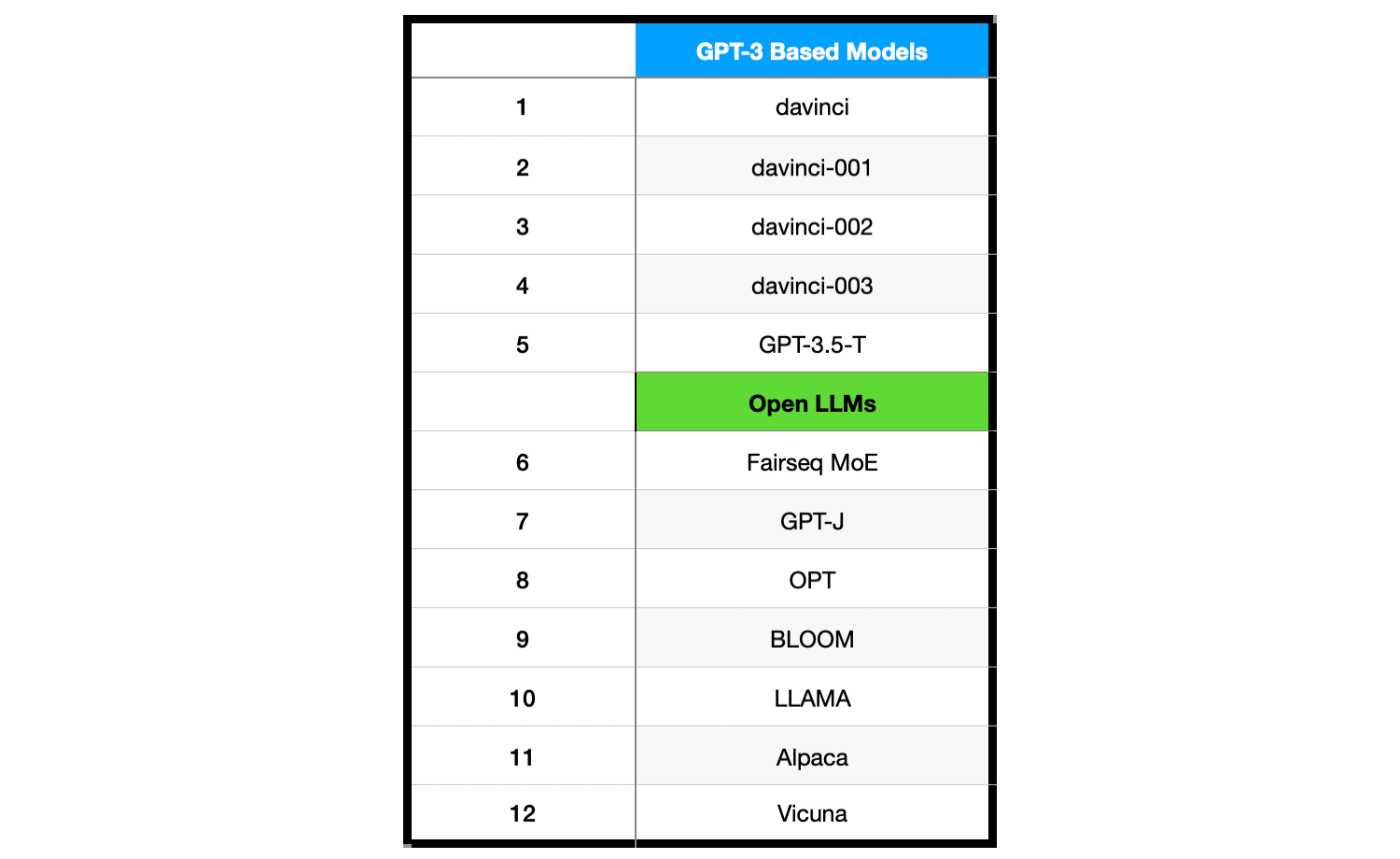
LLMs from the GPT-3 series of models and several other open-sourced LLMs were used for the tests.
Key Findings
The study highlights the importance of datasets, timing and testing LLMs over a longer period of time, especially as new versions of an existing model is updated.
Expectations on the influence of data included in a LLMs base training varies.
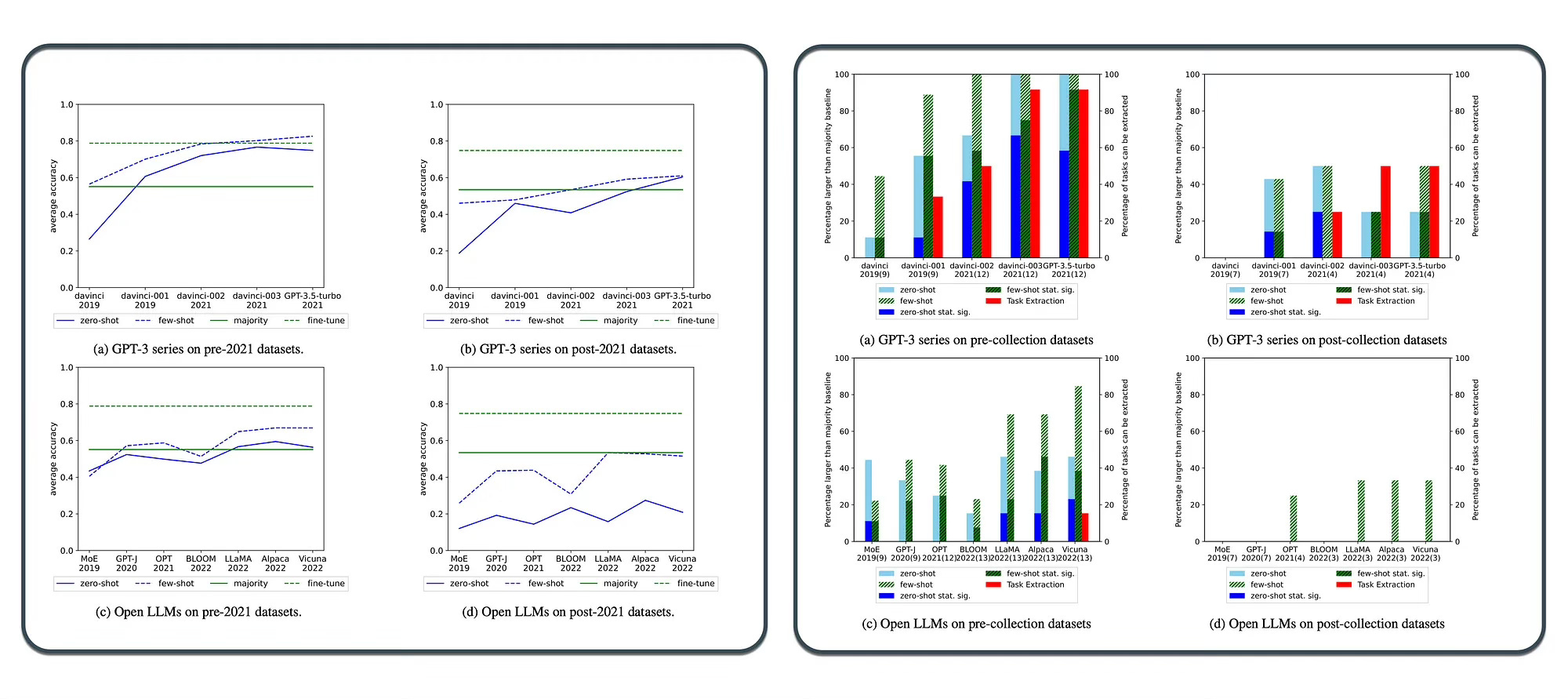
Large language models (LLMs) excel in zero-shot and few-shot tasks, but their performance may be affected by a potential limitation called task contamination.
The paper investigates the chronological changes in zero-shot and few-shot performance of LLMs, using GPT-3 series models and other recent open-sourced LLMs.
The study reveals that LLMs perform significantly better on datasets released before their training data creation date compared to datasets released after, suggesting the presence of task contamination.
In-Context Learning (ICL)
In recent times there has been immense focus on In-Context Learning where zero or few shot prompts are injected with highly contextual information at inference.
The study considers contamination of zero or few-shot methods, which is named task contamination, the inclusion of task training examples in the pre-training data, effectively making the evaluation no longer stricktly zero or few-shot.
Contamination
Zero-shot and few-shot evaluations involve models making predictions on tasks that they have never seen or seen only a few times during training.
The key premise is that the models have no prior exposure to the particular task at hand, ensuring a fair evaluation of their learning capacity.
Contamination is defined as instances where models, give a false impression of its zero or few shot competency, as they have already been trained on task examples during pre-training.
Finally
LLMs do not have a continuous learning capability and are frozen in time.
The study shows that LLMs perform well on tasks they have seen before during training & poorer on un-seen tasks.
Currently LLMs do not reliably & continuously adapt to drifting input distribution; might this point to the relevance of the newly introduced OpenAI fingerprint functionality; and models being updated on a perpetual basis?
Hence the LLMs performance is to some degree unpredictable, as users’ can be surprised by highly accurate and succinct results. Which might seem like highly astute LLM reasoning, where in actual fact it is previously seen information.
And on the flip side, there can be a deprecation in LLM performance, where the there data has not been seen during base model training.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.