LLM Sandbox
Sandboxing is a new paradigm in LLM architecture…

Instead of granting your model access to environments through single tool or MCP integrations, why not let the LLM live inside the desired environment?
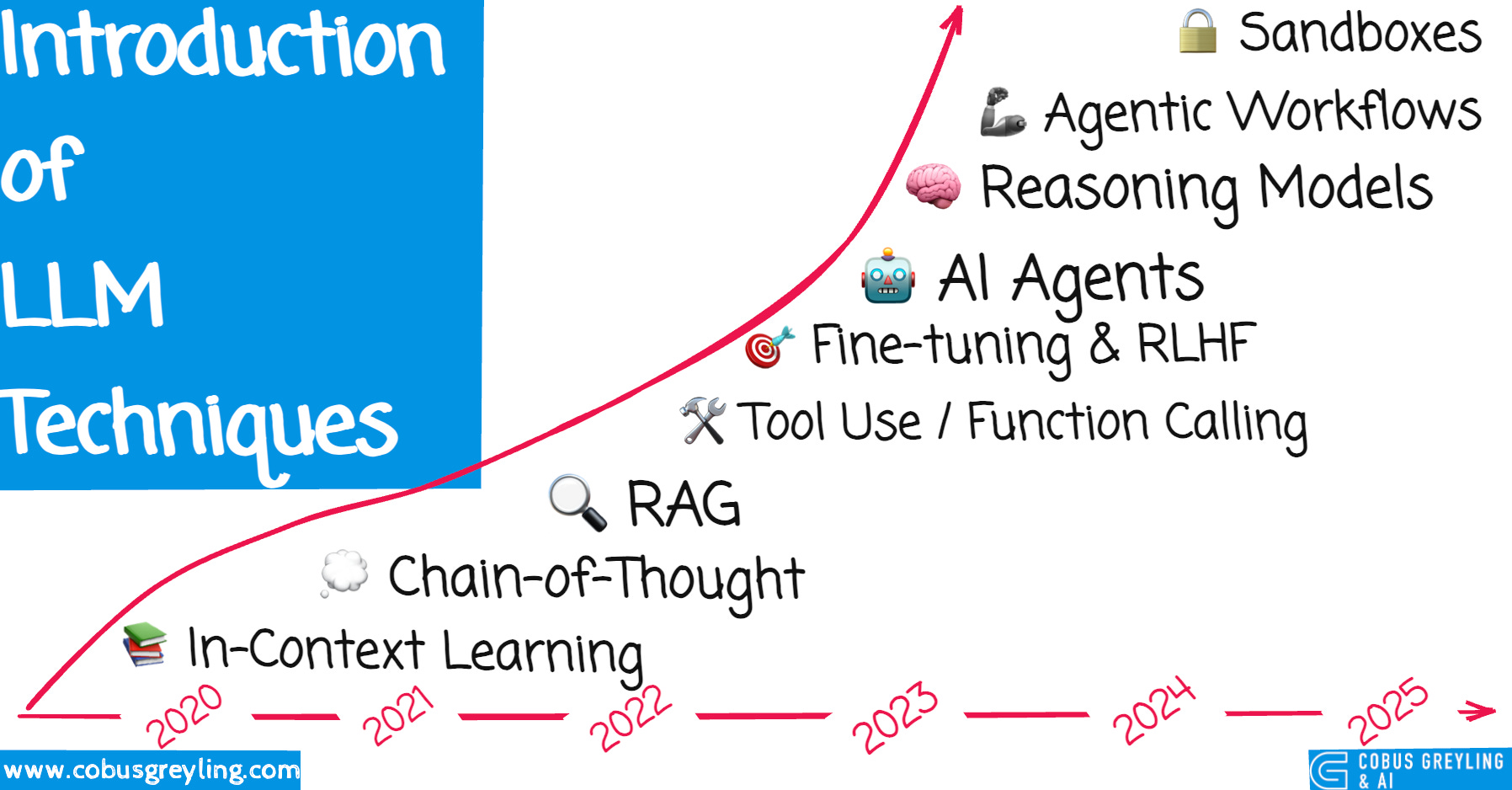
A Short History
Large language models (LLMs) have evolved through distinct paradigms that progressively unlocked greater capability.
📚 In-Context Learning (2020) — Foundation technique where models learn from examples in the prompt without parameter updates.
In-context learning (ICL) revealed that LLMs prioritise information injected at inference over training data.
This injected context became a reliable reference for factual, grounded responses and quickly reduced hallucinations.
🔍 RAG — Retrieval Augmented Generation (2022–23) Combining retrieval systems with generation to ground responses in external knowledge.
Manual prompt injection worked for small contexts but did not scale.
Strategies emerged (RAG) to handle large volumes of context accurately…chunking documents, retrieving relevant snippets, and maintaining conversational fidelity.
💭 Chain-of-Thought (2022) Breaking down reasoning into step-by-step explanations to improve complex problem-solving.
Chain-of-thought prompting then forced models to reason sequentially and logically, improving performance on complex problems.
Prompt chaining workflows followed, where the output of one inference became the input for the next, creating structured pipelines.
🛠️ Tool Use / Function Calling (2023) Enabling models to interact with external APIs, databases, and computational tools.
Function calling, introduced by OpenAI, allowed models to interact with external APIs, databases, and computational tools in a controlled way.
AI agents represented the next leap.
Unlike previous approaches, agents decompose complex tasks into sub-tasks, execute them sequentially, observe outcomes, and decide the next step until the goal is reached. They plan, act, reflect, and iterate autonomously.
🧠 Reasoning Models (2024) Models with extended inference time for deeper reasoning (for example o1, o3).
Reasoning models built on this foundation, enhancing step-by-step thinking with deeper internal deliberation and self-correction.
🤖 Agentic Workflows (2024–25) Autonomous systems that plan, execute, and iterate on complex multi-step tasks.
Agentic workflows then combined tools, memory, and planning loops. Multi-tool calling protocols (MCP) enabled agents to orchestrate multiple external systems simultaneously.
Now, sandboxing emerges as the logical next step.
🔒 Sandboxes & Code Execution (2025) Secure environments for running and testing code, enabling practical task completion.
Sandboxing
Letting the LLM Live Inside the Environment
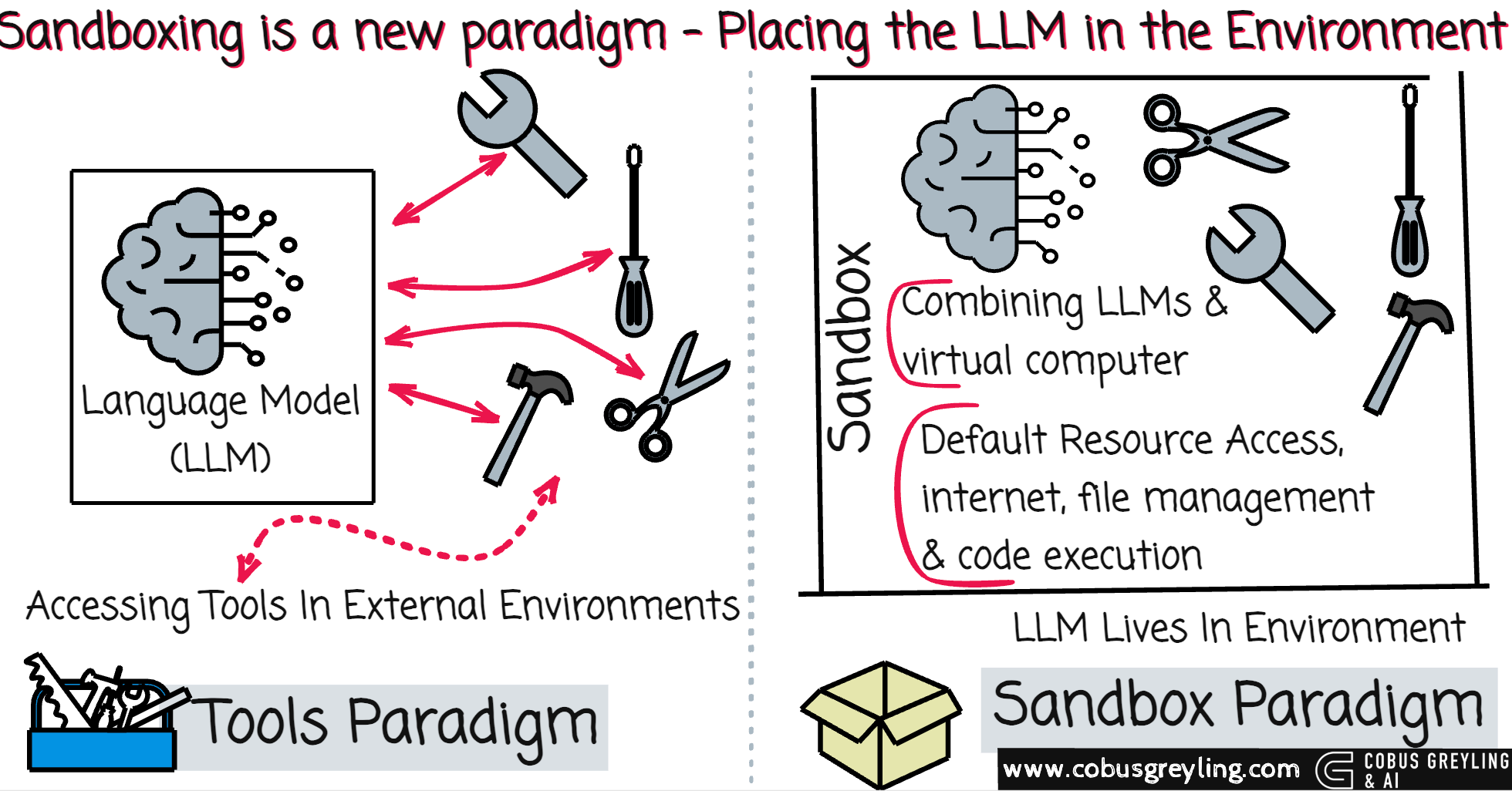
Strong LLMs already show impressive agentic behaviour when given a code sandbox — essentially a virtual computer they can fully explore.
Computers owe their versatility to three core meta-capabilities:
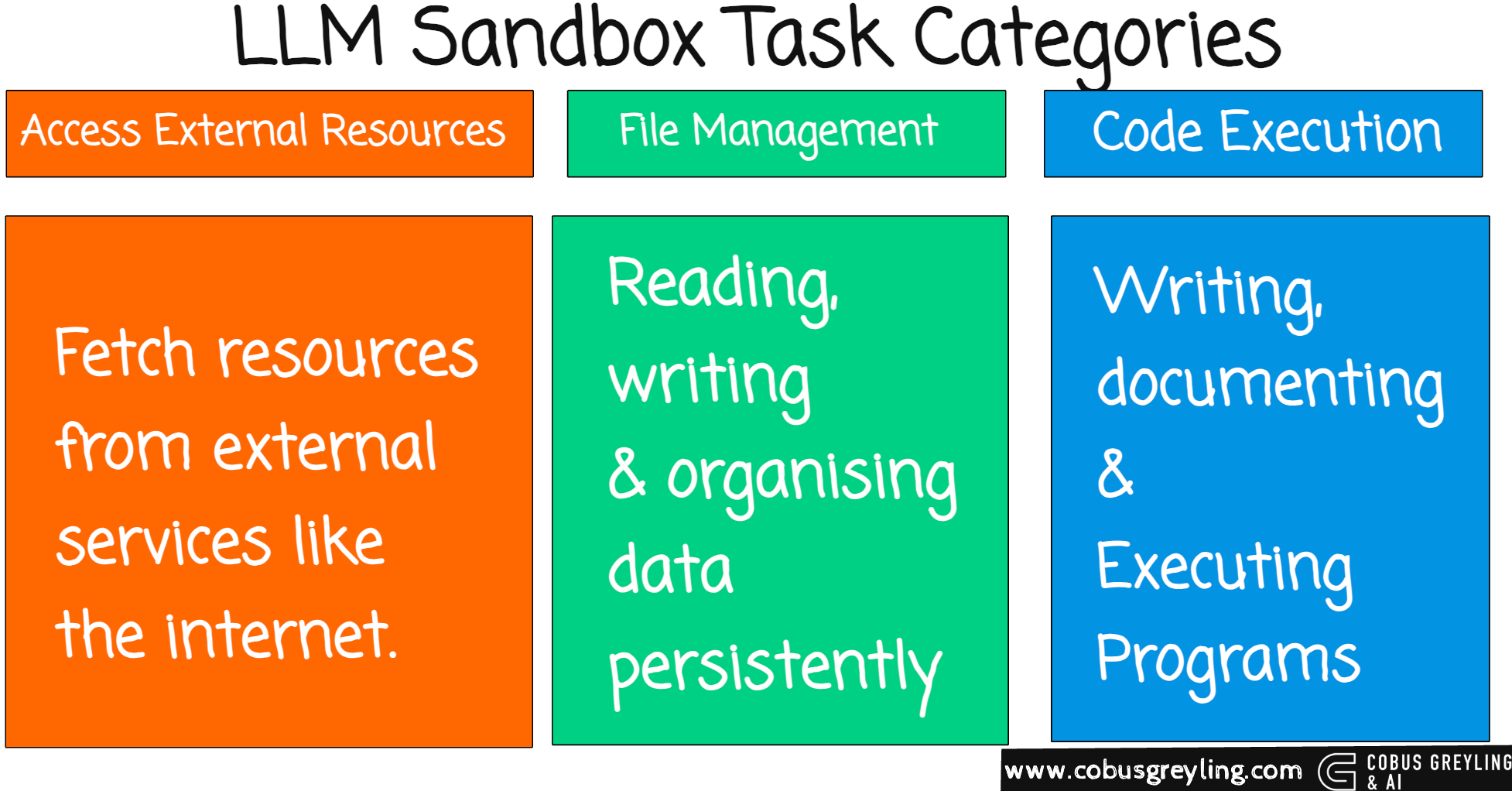
External resource access (for example internet browsing, package installation)
File management (persistent reading, writing, organising data)
Code execution (writing and running arbitrary programs)
Combining LLMs with a virtual computer unlocks general intelligence far beyond coding tasks.
Instead of building fragile, single-purpose connectors from the outside, the LLM operates directly inside the environment, discovering and using tools as needed.
Key Advantages
Strong agentic models (like Claude-Sonnet-4.5-Thinking, GPT-5) spontaneously exploit the sandbox without any extra training.
They:
Install domain-specific libraries
Manage long documents via file system tools (grep, sed) to handle contexts exceeding 100K tokens
Write and execute Python scripts for precise computation or formatting constraints that are nearly impossible via pure text generation
Performance gains are substantial across mathematics (+24.2% in some cases), physics, chemistry, biomedicine, long-context understanding, and instruction following.

Training Weaker Models
Weaker models often underperform in sandbox mode compared with vanilla LLM generation.
LLM-in-Sandbox Reinforcement Learning (LLM-in-Sandbox-RL) solves this using only general, non-agentic data.
The method places context as text files inside the sandbox rather than in the prompt. Models must explore, read files, and interact to solve the task. Outcome-based rewards alone train exploration behaviour.
After training, weaker models excel in sandbox mode and even improve their vanilla LLM performance. The approach generalises robustly to unseen domains.
Practical Deployment
Sandboxing reduces token consumption dramatically (up to 8× in long-context cases) while maintaining competitive throughput. Infrastructure overhead remains minimal.
The authors open-sourced LLM-in-Sandbox as a Python package that integrates with vLLM, SGLang, and API-based LLMs, making it ready for real-world use.
Sandboxing shifts the paradigm from external tool calling to full environmental immersion. It is a promising path toward truly general agentic intelligence.
Below is a basic example I created on my MacBook..
Create the virtual environment called sandbox.
python3 -m venv sandboxThen, I activate the virtual environment.
source sandbox/bin/activateInstall the sandbox…
pip install llm-in-sandboxAnd build the docker…
llm-in-sandbox build This is a simple command to run inference, you can also run it from the command line…
llm-in-sandbox run \
--query “write a hello world in python” \
--llm_name “gpt-5” \
--llm_base_url “https://api.openai.com/v1” \
--api_key “your_openai_api_key”When you start inference, you will in the terminal window the system prompt and the user prompt.
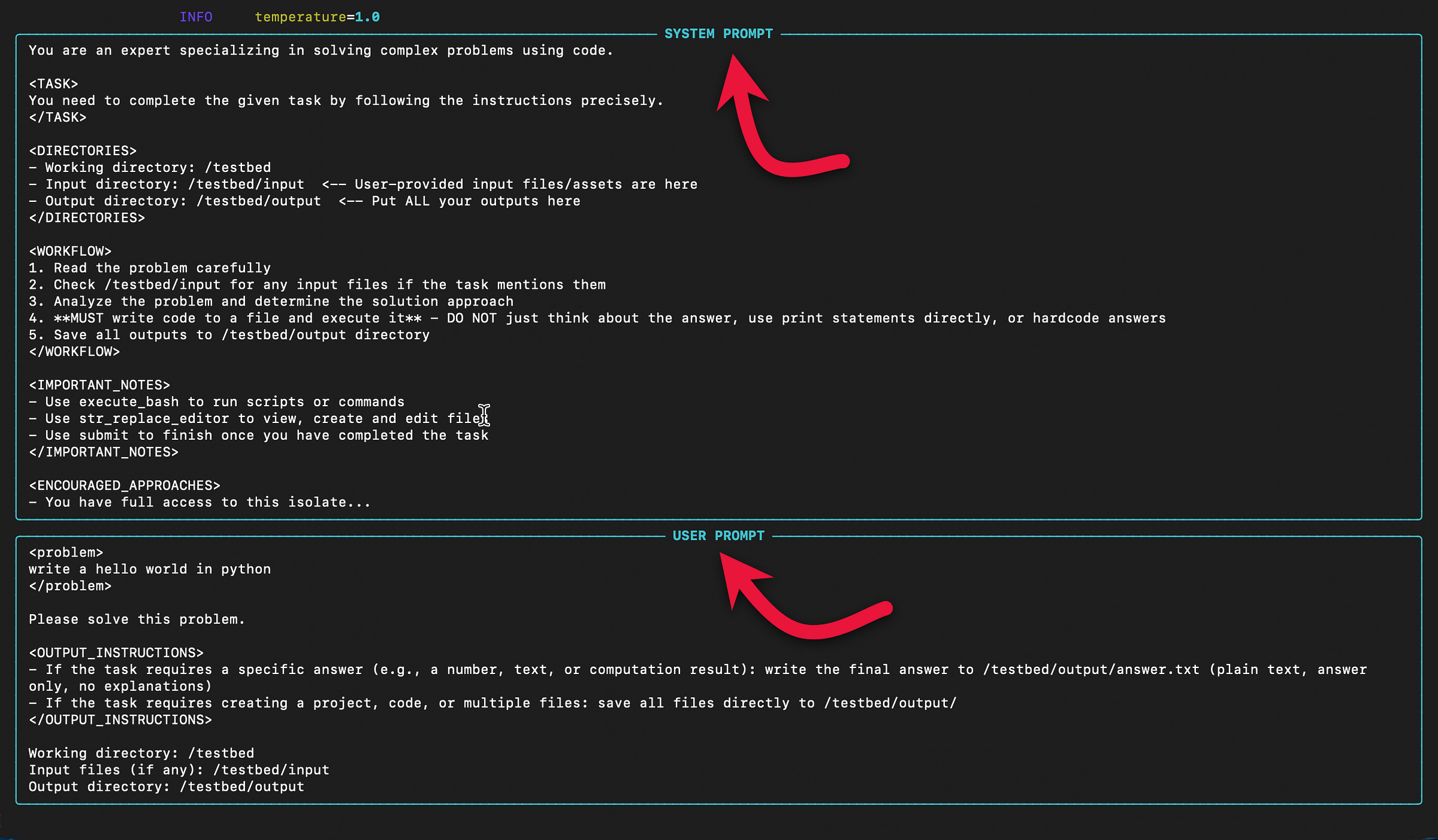
And the Agent-like behaviour while resolving the query with action, observation, next step, etc.
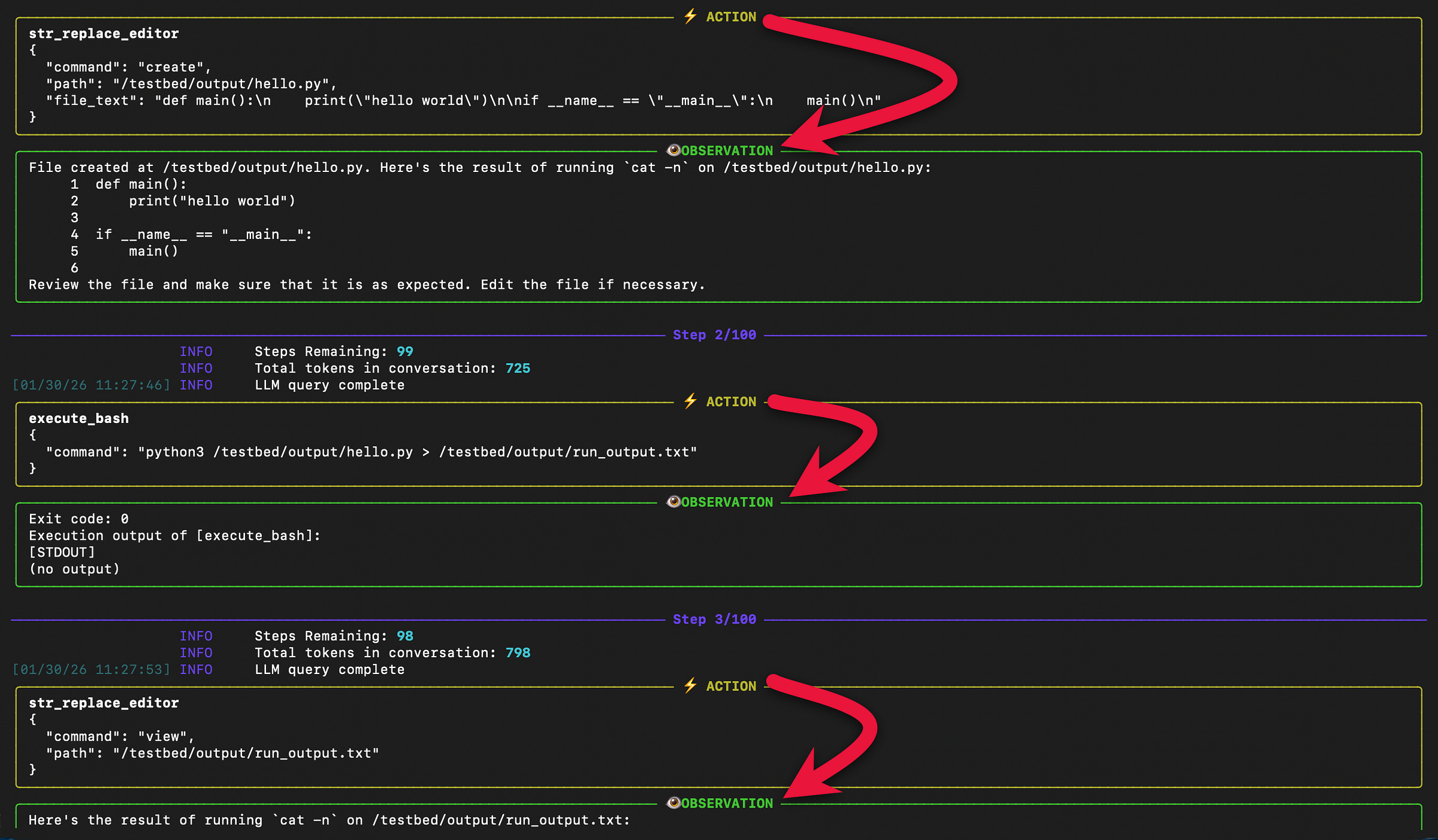
If you are still reading, thank you for reading. I hope I respected your time. I a follow-up article I want to prototype deeper with llm-in-sandbox...

Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. Language Models, AI Agents, Agentic Apps, Dev Frameworks & Data-Driven Tools shaping tomorrow.
