LLMs & Contextual Demonstration
Large Language Models are able to learn in-context via a number of examples which acts as demonstrations, also referred to as few-shot learning.

In the recent past, there has been little understanding on how models learn from few-shot, in-context demonstrations & what part of the demonstration is the most important to performance.
With human language in general and LLMs in specific, context is of utmost importance. When a few-shot learning approach is followed via Prompt Engineering, a contextual reference is established for the LLM to serve as an input specific contextual reference.
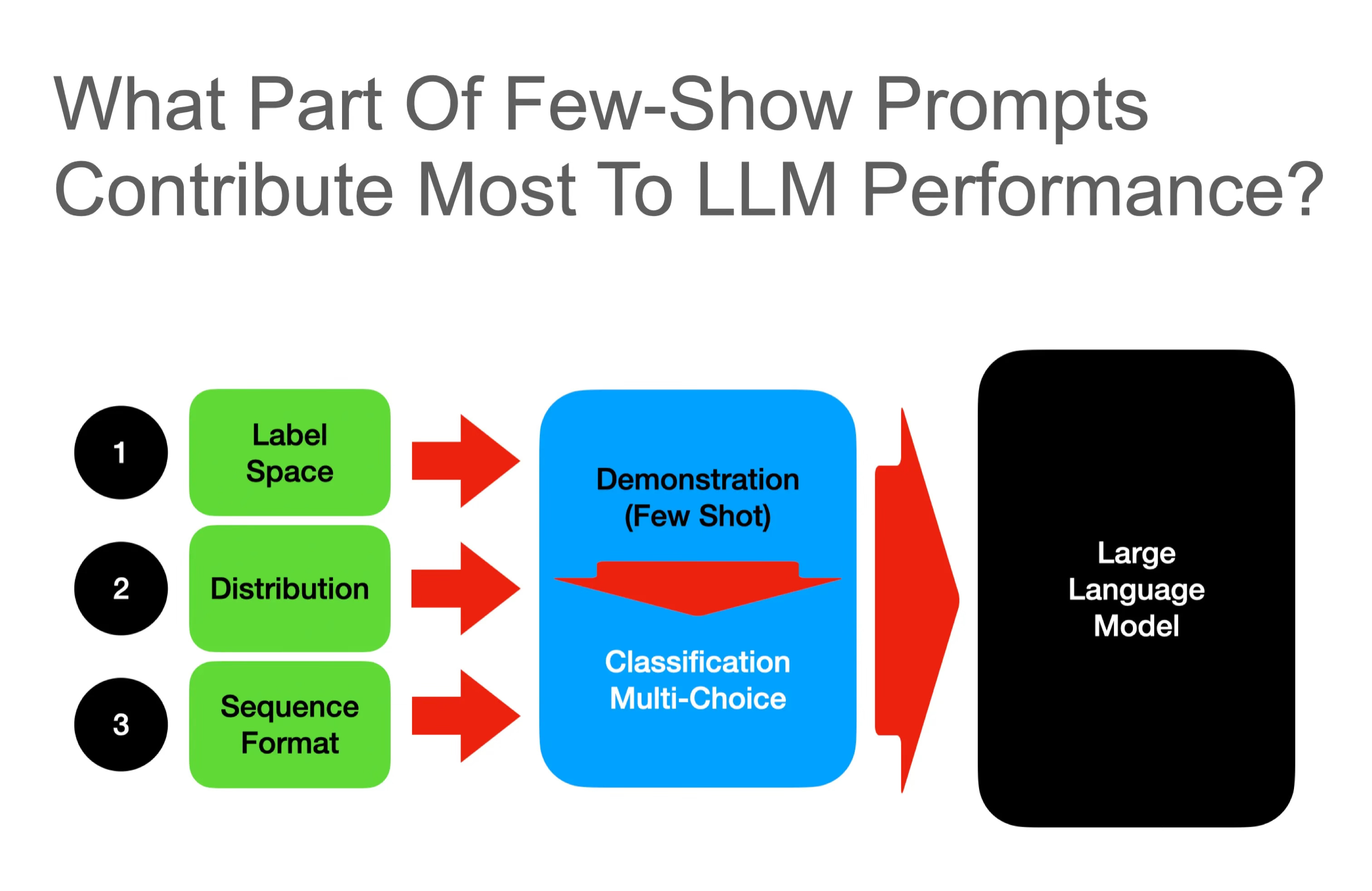
A recent study explored how models learn and which aspects contribute most to the tasks and performance. The study found that the key drivers of few-shot training are:
Label Space
Distribution of input text, and
the overall format of the sequence.
The analysis creates a new understanding of how in-context learning worksand challenges notions of what can be achieved at inference alone.
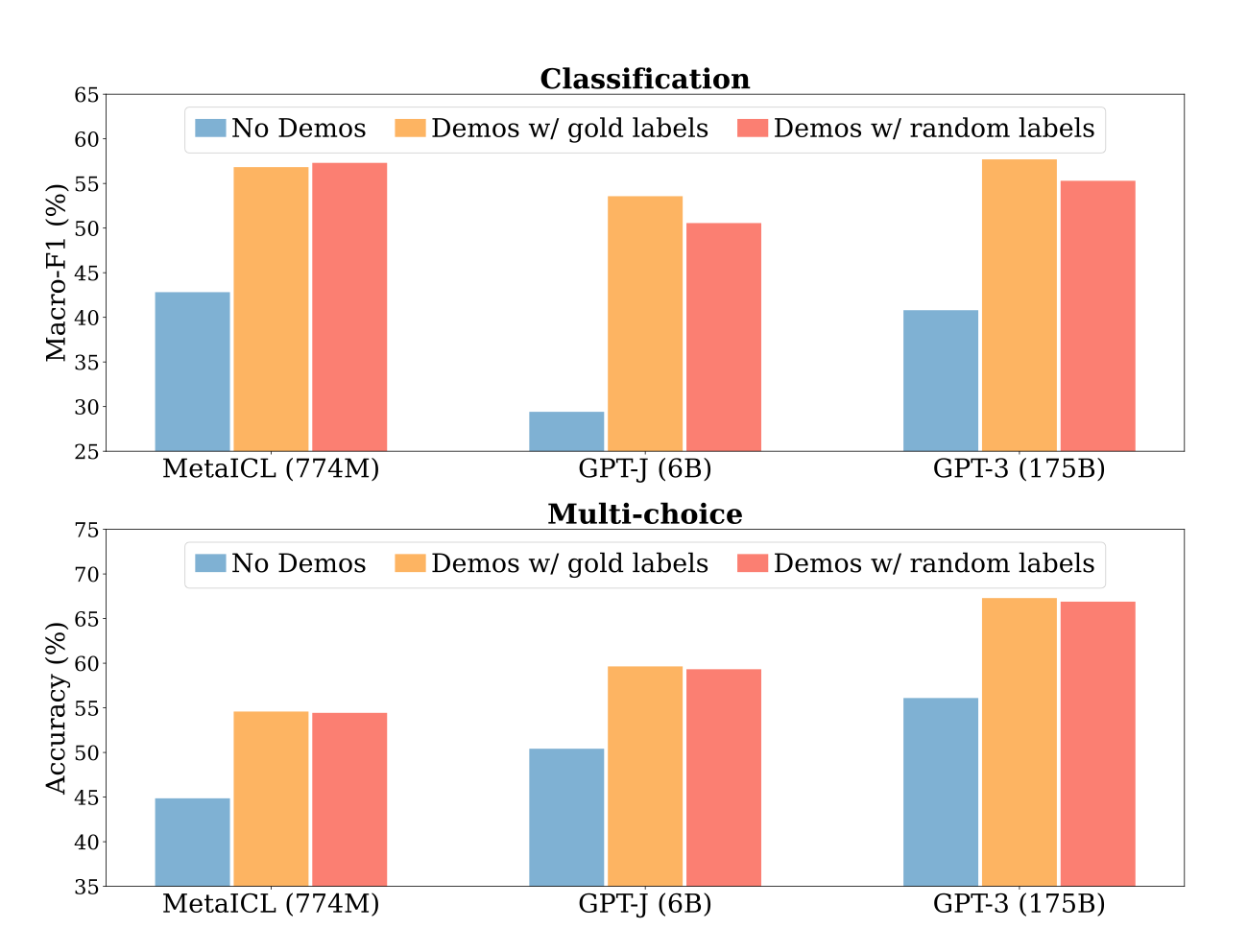
Considering the image below, the performance of two use-cases are shown across three models. The model performance where no demonstration is given, varies quite a bit.
Considering the no demonstration performance of GPT-J for a moment…the GPT-J model can be access via a few playgrounds; generally casual users are disappointed with the model’s performance.
However, consider the boost in performance with gold and random labels are used at inference. This goes to show that apart from fine-tuning, implementing an accurate and succinct prompt engineering pipeline can boost the performance of LLMs.
This finding has implications for local installations of smaller models which are open-sourced; models which are often deemed not good enough when being casually inspected.
However, when the principles detailed here are followed and as seen in the graph below, exceptional performance can be extracted from models.
This approach can solve for cost, data privacy, corporate governance requirements and more; considering smaller models can be made use of.
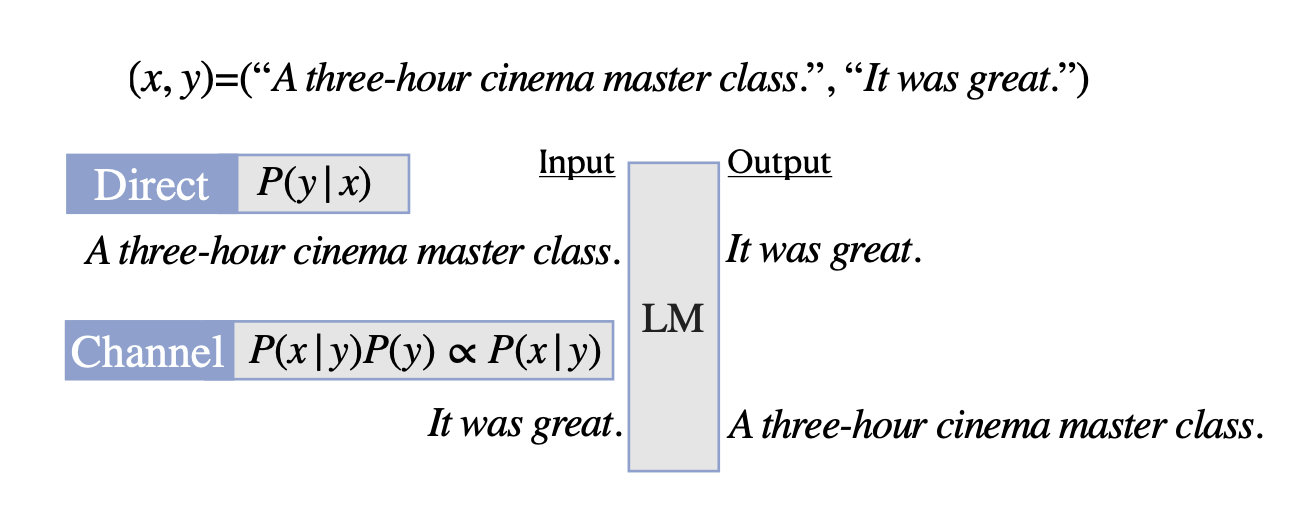
Below the impact of the distribution of the inputs are shown, notice the disparity between Direct & Channel. The direct model exploits the label space better than the input distribution, and the channel model exploits the input distribution better than the label space.

Below is a good breakdown of practical examples where format, input distribution, label space and input-label mapping are experimented with.

In Closing
It needs to be noted these experiments were limited to classification and multi-choice tasks.
Any study on how to optimise inference data for other tasks like completion, editing and chat will immensely useful.
Noisy Channel & Direct Approaches To Inference
For few-shot text classification. Instead of predicting the label from input; like intent detection works; channel models compute the conditional probability of the input given the label.
Direct prompting is shown very clearly in the image below. And I do get the sense that direct inference is more widely used as opposed to channel; while there are studies showing that channel outperforms direct.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.